Inserito originariamente su Serverless il 2 luglio 2019

L'esposizione di un semplice database tramite un'API GraphQL richiede molto codice e infrastruttura personalizzati:vero o falso?
Per coloro che hanno risposto "vero", siamo qui per mostrarti che la creazione di API GraphQL è in realtà abbastanza semplice, con alcuni esempi concreti per illustrare perché e come.
(Se sai già quanto è facile creare API GraphQL con Serverless, c'è molto anche per te in questo articolo.)
GraphQL è un linguaggio di query per le API Web. C'è una differenza fondamentale tra un'API REST convenzionale e le API basate su GraphQL:con GraphQL, puoi utilizzare una singola richiesta per recuperare più entità contemporaneamente. Ciò si traduce in caricamenti di pagina più rapidi e abilita una struttura più semplice per le tue app front-end, con conseguente migliore esperienza web per tutti. Se non hai mai usato GraphQL prima, ti suggeriamo di dare un'occhiata a questo tutorial di GraphQL per una rapida introduzione.
Il framework Serverless è perfetto per le API GraphQL:con Serverless, non devi preoccuparti di eseguire, gestire e ridimensionare i tuoi server API nel cloud e non dovrai scrivere script di automazione dell'infrastruttura. Scopri di più su Serverless qui. Inoltre, Serverless offre un'eccellente esperienza di sviluppo indipendente dal fornitore e una solida community per aiutarti a creare le tue applicazioni GraphQL.
Molte applicazioni nella nostra esperienza quotidiana contengono funzionalità di social networking e quel tipo di funzionalità può davvero trarre vantaggio dall'implementazione di GraphQL invece del modello REST, dove è difficile esporre strutture con entità nidificate, come gli utenti e i loro post su Twitter. Con GraphQL puoi creare un endpoint API unificato che ti consente di eseguire query, scrivere e modificare tutte le entità di cui hai bisogno utilizzando un'unica richiesta API.
In questo articolo, esamineremo come creare una semplice API GraphQL con l'aiuto del framework Serverless, Node.js e una qualsiasi delle numerose soluzioni di database ospitate disponibili tramite Amazon RDS:MySQL, PostgreSQL e il workalike MySQL Amazon Aurora.
Segui questo esempio di repository su GitHub e tuffiamoci!
Creazione di un'API GraphQL con un backend DB relazionale
Nel nostro progetto di esempio, abbiamo deciso di utilizzare tutti e tre i database (MySQL, PostgreSQL e Aurora) nella stessa base di codice. Sappiamo che è eccessivo anche per un'app di produzione, ma volevamo stupirti con il modo in cui costruiamo su scala web. 😉
Ma seriamente, abbiamo sovraccaricato il progetto solo per assicurarci che trovassi un esempio pertinente che si applica al tuo database preferito. Se desideri vedere esempi con altri database, faccelo sapere nei commenti.
Definizione dello schema GraphQL
Iniziamo definendo lo schema dell'API GraphQL che vogliamo creare, cosa che facciamo nel file schema.gql alla radice del nostro progetto utilizzando la sintassi GraphQL. Se non hai familiarità con questa sintassi, dai un'occhiata agli esempi in questa pagina della documentazione di GraphQL.
Per cominciare, aggiungiamo i primi due elementi allo schema:un'entità Utente e un'entità Post, definendoli come segue in modo che ogni Utente possa avere più entità Post associate ad esso:
digita Utente {
UUID:stringa
Nome:stringa
Post:[Post]
}
digita Post {
UUID:stringa
Testo:stringa
}
Ora possiamo vedere come appaiono le entità Utente e Post. Successivamente, ci assicureremo che questi campi possano essere archiviati direttamente nei nostri database.
Successivamente, definiamo come gli utenti dell'API eseguiranno query su queste entità. Sebbene potremmo utilizzare i due tipi di GraphQL User e Post direttamente nelle nostre query GraphQL, è consigliabile creare tipi di input invece di mantenere lo schema semplice. Quindi andiamo avanti e aggiungiamo due di questi tipi di input, uno per i post e uno per gli utenti:
inserisci UserInput {
Nome:stringa
Messaggi:[PostInput]
}
inserisci PostInput {
Testo:stringa
}
Ora definiamo le mutazioni, le operazioni che modificano i dati archiviati nei nostri database tramite la nostra API GraphQL. Per questo creiamo un tipo di Mutazione. L'unica mutazione che useremo per ora è createUser. Poiché stiamo utilizzando tre database diversi, aggiungiamo una mutazione per ogni tipo di database. Ciascuna delle mutazioni accetta l'input UserInput e restituisce un'entità Utente:
Vogliamo anche fornire un modo per interrogare gli utenti, quindi creiamo un tipo di query con una query per tipo di database. Ogni query accetta una stringa che è l'UUID dell'utente, restituendo l'entità Utente che contiene il suo nome, UUID e una raccolta di ogni Pos``t associato:
Infine, definiamo lo schema e puntiamo ai tipi Query e Mutation:
schema { query: Query mutation: Mutation }
Ora abbiamo una descrizione completa per la nostra nuova API GraphQL! Puoi vedere l'intero file qui.
Definizione dei gestori per l'API GraphQL
Ora che abbiamo una descrizione della nostra API GraphQL, possiamo scrivere il codice di cui abbiamo bisogno per ogni query e mutazione. Iniziamo creando un file handler.js nella radice del progetto, proprio accanto al file schema.gql che abbiamo creato in precedenza.
Il primo lavoro di handler.js è leggere lo schema:
La costante typeDefs ora contiene le definizioni per le nostre entità GraphQL. Successivamente, specifichiamo dove vivrà il codice per le nostre funzioni. Per mantenere le cose chiare, creeremo un file separato per ogni query e mutazione:
La costante del risolutore ora contiene le definizioni per tutte le funzioni della nostra API. Il nostro prossimo passo è creare il server GraphQL. Ricordi la libreria graphql-yoga che abbiamo richiesto sopra? Useremo quella libreria qui per creare un server GraphQL funzionante in modo facile e veloce:
Infine, esportiamo il gestore GraphQL insieme al gestore GraphQL Playground (che ci consentirà di provare la nostra API GraphQL in un browser web):
Ok, per ora abbiamo finito con il file handler.js. Prossimo:scrittura del codice per tutte le funzioni che accedono ai database.
Scrittura del codice per le query e le mutazioni
Ora abbiamo bisogno del codice per accedere ai database e per alimentare la nostra API GraphQL. Nella radice del nostro progetto, creiamo la seguente struttura per le nostre funzioni del resolver MySQL, con gli altri database a seguire:
Query comuni
Nella cartella Common, popolamo il file mysql.js con ciò che ci occorre per la mutazione createUser e la query getUser:una query init, per creare tabelle per Utenti e Post se non esistono ancora; e una query utente, per restituire i dati di un utente durante la creazione e l'esecuzione di query per un utente. Lo useremo sia nella mutazione che nella query.
La query init crea sia le tabelle Utenti che Post come segue:
La query getUser restituisce l'utente e i suoi post:
Entrambe queste funzioni vengono esportate; possiamo quindi accedervi nel file handler.js.
Scrittura della mutazione
È ora di scrivere il codice per la mutazione createUser, che deve accettare il nome del nuovo utente, nonché un elenco di tutti i post che gli appartengono. Per fare ciò creiamo il file resolver/Mutation/mysql_createUser.js con una singola funzione func esportata per la mutazione:
La funzione di mutazione deve fare le seguenti cose, in ordine:
-
Connettiti al database utilizzando le credenziali nelle variabili di ambiente dell'applicazione.
-
Inserisci l'utente nel database utilizzando il nome utente, fornito come input per la mutazione.
-
Inserisci anche eventuali post associati all'utente, forniti come input per la mutazione.
-
Restituisce i dati utente creati.
Ecco come lo realizziamo nel codice:
Puoi vedere il file completo che definisce la mutazione qui.
Scrittura della query
La query getUser ha una struttura simile alla mutazione che abbiamo appena scritto, ma questa è ancora più semplice. Ora che la funzione getUser si trova nello spazio dei nomi Common, non è più necessario alcun SQL personalizzato nella query. Quindi, creiamo il file resolver/Query/mysql_getUser.js come segue:
Puoi vedere la query completa in questo file.
Riunire tutto nel file serverless.yml
Facciamo un passo indietro. Al momento abbiamo quanto segue:
-
Uno schema dell'API GraphQL.
-
Un file handler.js.
-
Un file per query di database comuni.
-
Un file per ogni mutazione e query.
L'ultimo passaggio è connettere tutto questo insieme tramite il file serverless.yml. Creiamo un serverless.yml vuoto alla radice del progetto e iniziamo definendo il provider, la regione e il runtime. Applichiamo anche il ruolo LambdaRole IAM (che definiremo più avanti qui) al nostro progetto:
Definiamo quindi le variabili di ambiente per le credenziali del database:
Si noti che tutte le variabili fanno riferimento alla sezione personalizzata, che viene successiva e contiene i valori effettivi per le variabili. Nota che la password è una password terribile per il tuo database e dovrebbe essere cambiata in qualcosa di più sicuro (forse p@ssw0rd 😃):
Quali sono quei riferimenti dopo Fn::GettAtt, chiedi? Questi si riferiscono alle risorse del database:
Il file Resource/MySqlRDSInstance.yml definisce tutti gli attributi dell'istanza MySQL. Puoi trovare il suo contenuto completo qui.
Infine, nel file serverless.yml definiamo due funzioni, graphql e playground. La funzione graphql gestirà tutte le richieste API e l'endpoint playground creerà per noi un'istanza di GraphQL Playground, che è un ottimo modo per provare la nostra API GraphQL in un browser web:
Ora il supporto MySQL per la nostra applicazione è completo!
Puoi trovare il contenuto completo del file serverless.yml qui.
Aggiunta del supporto Aurora e PostgreSQL
Abbiamo già creato tutta la struttura di cui abbiamo bisogno per supportare altri database in questo progetto. Per aggiungere il supporto per Aurora e Postgres, dobbiamo solo definire il codice per le loro mutazioni e query, cosa che facciamo come segue:
-
Aggiungi un file di query comuni per Aurora e per Postgres.
-
Aggiungi la mutazione createUser per entrambi i database.
-
Aggiungi la query getUser per entrambi i database.
-
Aggiungi la configurazione nel file serverless.yml per tutte le variabili di ambiente e le risorse necessarie per entrambi i database.
A questo punto, abbiamo tutto ciò di cui abbiamo bisogno per implementare la nostra API GraphQL, basata su MySQL, Aurora e PostgreSQL.
Distribuzione e test dell'API GraphQL
L'implementazione della nostra API GraphQL è semplice.
-
Per prima cosa eseguiamo npm install per mettere in atto le nostre dipendenze.
-
Quindi eseguiamo npm run deploy, che imposta tutte le nostre variabili di ambiente ed esegue la distribuzione.
-
Sotto il cofano, questo comando esegue la distribuzione senza server utilizzando l'ambiente giusto.
Questo è tutto! Nell'output del passaggio di distribuzione vedremo l'endpoint URL per la nostra applicazione distribuita. Possiamo inviare richieste POST alla nostra API GraphQL utilizzando questo URL e il nostro Playground (con cui giocheremo tra un secondo) è disponibile utilizzando GET rispetto allo stesso URL.
Prova l'API nel parco giochi GraphQL
GraphQL Playground, che è ciò che vedi quando visiti quell'URL nel browser, è un ottimo modo per provare la nostra API.
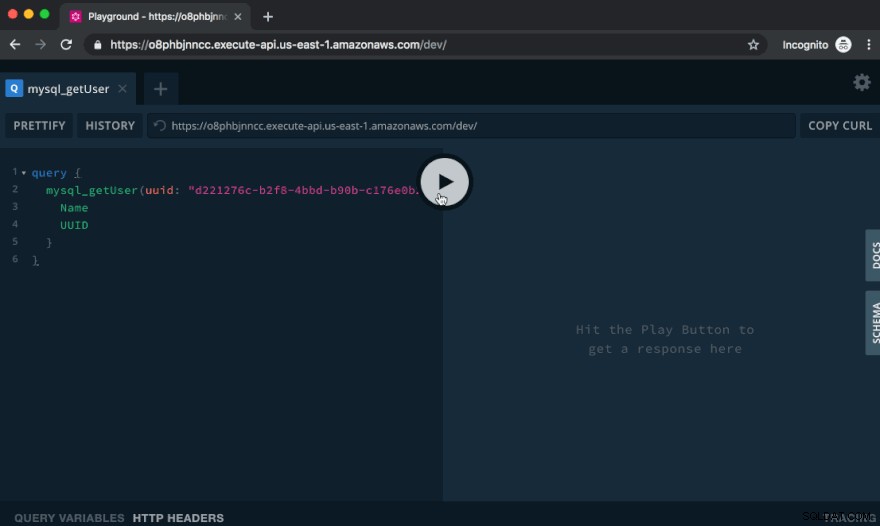
Creiamo un utente eseguendo la seguente mutazione:
mutation { mysql_createUser( input: { Name: "Cicero" Posts: [ { Text: "Lorem ipsum dolor sit amet, consectetur adipiscing elit." } { Text: "Proin consequat mauris orci, ut consequat purus efficitur vel." } ] } ) { Name UUID } }
In questa mutazione, chiamiamo l'API mysql_createUser, forniamo il testo dei post del nuovo utente e indichiamo che vogliamo recuperare il nome dell'utente e l'UUID come risposta.
Incolla il testo sopra sul lato sinistro del Parco giochi e fai clic sul pulsante Riproduci. Sulla destra, vedrai l'output della query:
Ora interroghiamo per questo utente:
query { mysql_getUser(uuid: "f5593682-6bf1-466a-967d-98c7e9da844b") { Name UUID } }
Questo ci restituisce il nome e l'UUID dell'utente che abbiamo appena creato. Pulito!
Possiamo fare lo stesso con gli altri backend, PostgreSQL e Aurora. Per questo, dobbiamo solo sostituire i nomi della mutazione con postgres_createUser o aurora_createUser e le query con postgres_getUser o aurora_getUser. Provalo tu stesso! (Tieni presente che gli utenti non sono sincronizzati tra i database, quindi potrai eseguire query solo per gli utenti che hai creato in ogni database specifico.)
Confronto tra le implementazioni MySQL, PostgreSQL e Aurora
Per cominciare, le mutazioni e le query sembrano esattamente le stesse su Aurora e MySQL, poiché Aurora è compatibile con MySQL. E ci sono solo differenze minime di codice tra questi due e l'implementazione di Postgres.
In effetti, per casi d'uso semplici, la più grande differenza tra i nostri tre database è che Aurora è disponibile solo come cluster. La configurazione Aurora più piccola disponibile include ancora una replica di sola lettura e una di scrittura, quindi abbiamo bisogno di una configurazione in cluster anche per questa distribuzione Aurora di base.
Aurora offre prestazioni più veloci rispetto a MySQL e PostgreSQL, principalmente grazie alle ottimizzazioni SSD apportate da Amazon al motore di database. Man mano che il tuo progetto cresce, probabilmente scoprirai che Aurora offre una migliore scalabilità del database, una manutenzione più semplice e una migliore affidabilità rispetto alle configurazioni predefinite di MySQL e PostgreSQL. Ma puoi apportare alcuni di questi miglioramenti anche su MySQL e PostgreSQL se ottimizzi i tuoi database e aggiungi la replica.
Per progetti di test e playground consigliamo MySQL o PostgreSQL. Questi possono essere eseguiti su istanze db.t2.micro RDS, che fanno parte del piano gratuito di AWS. Aurora attualmente non offre istanze db.t2.micro, quindi pagherai un po' di più per utilizzare Aurora per questo progetto di test.
Un'ultima nota importante
Ricordati di rimuovere la tua distribuzione serverless una volta che hai finito di provare l'API GraphQL in modo da non continuare a pagare per le risorse di database che non stai più utilizzando.
Puoi rimuovere lo stack creato in questo esempio eseguendo npm run remove nella radice del progetto.
Buona sperimentazione!
Riepilogo
In questo articolo ti abbiamo guidato attraverso la creazione di una semplice API GraphQL, utilizzando tre diversi database contemporaneamente; sebbene questo non sia qualcosa che avresti mai fatto in realtà, ci ha permesso di confrontare semplici implementazioni dei database Aurora, MySQL e PostgreSQL. Abbiamo visto che l'implementazione per tutti e tre i database è più o meno la stessa nel nostro caso semplice, salvo piccole differenze nella sintassi e nelle configurazioni di distribuzione.
Puoi trovare il progetto di esempio completo che abbiamo utilizzato in questo repository GitHub. Il modo più semplice per sperimentare il progetto è clonare il repository e distribuirlo dal tuo computer utilizzando npm run deploy.
Per altri esempi di API GraphQL che utilizzano Serverless, controlla il repository serverless-graphql.
Se desideri saperne di più sull'esecuzione di API GraphQL serverless su larga scala, potresti apprezzare la nostra serie di articoli "Esecuzione di un endpoint GraphQL scalabile e affidabile con Serverless"
Forse GraphQL non fa per te e preferiresti distribuire un'API REST? Ti abbiamo coperto:dai un'occhiata a questo post del blog per alcuni esempi.
Domande? Commenta questo post o crea una discussione nel nostro forum.
Pubblicato originariamente su https://www.serverless.com.