Nel mondo dell'informatica, l'automazione non è una novità per la maggior parte di noi. In effetti, la maggior parte delle organizzazioni lo utilizza per vari scopi a seconda del tipo di lavoro e degli obiettivi. Ad esempio, gli analisti di dati utilizzano l'automazione per generare report, gli amministratori di sistema utilizzano l'automazione per le loro attività ripetitive come la pulizia dello spazio su disco e gli sviluppatori utilizzano l'automazione per automatizzare il loro processo di sviluppo.
Oggigiorno, ci sono molti strumenti di automazione per l'IT disponibili e possono essere scelti, grazie all'era DevOps. Qual è lo strumento migliore? La risposta è un prevedibile "dipende", poiché dipende da ciò che stiamo cercando di ottenere e dalla configurazione dell'ambiente. Alcuni degli strumenti di automazione sono Terraform, Bolt, Chef, SaltStack e uno molto alla moda è Ansible. Ansible è un motore IT agentless open source in grado di automatizzare la distribuzione delle applicazioni, la gestione della configurazione e l'orchestrazione IT. Ansible è stata fondata nel 2012 ed è stata scritta nel linguaggio più popolare, Python. Utilizza un playbook per implementare tutta l'automazione, in cui tutte le configurazioni sono scritte in un linguaggio leggibile dall'uomo, YAML.
Nel post di oggi impareremo come utilizzare Ansible per eseguire la distribuzione del database Postgresql.
Cosa rende speciale Ansible?
Il motivo per cui ansible viene utilizzato principalmente per le sue caratteristiche. Queste caratteristiche sono:
-
Tutto può essere automatizzato utilizzando un semplice linguaggio leggibile dall'uomo YAML
-
Nessun agente verrà installato sulla macchina remota (architettura agentless)
-
La configurazione verrà inviata dal tuo computer locale al server dal tuo computer locale (modello push)
-
Sviluppato utilizzando Python (uno dei linguaggi popolari attualmente utilizzati) e molte librerie possono essere scelte da
-
Raccolta di moduli Ansible accuratamente selezionati dal Red Had Engineering Team
Il modo in cui Ansible funziona
Prima che Ansible possa eseguire qualsiasi attività operativa sugli host remoti, è necessario installarlo in un host che diventerà il nodo del controller. In questo nodo controller, orchestreremo tutte le attività che vorremmo eseguire negli host remoti noti anche come nodi gestiti.
Il nodo controller deve disporre dell'inventario dei nodi gestiti e del software Ansible per gestirlo. I dati richiesti per essere utilizzati da Ansible come il nome host o l'indirizzo IP del nodo gestito verranno inseriti in questo inventario. Senza un inventario adeguato, Ansible non potrebbe eseguire correttamente l'automazione. Vedi qui per saperne di più sull'inventario.
Ansible è agentless e utilizza SSH per eseguire il push delle modifiche, il che significa che non dobbiamo installare Ansible in tutti i nodi, ma tutti i nodi gestiti devono avere python e tutte le librerie python necessarie installate. Sia il nodo controller che i nodi gestiti devono essere impostati come senza password. Vale la pena ricordare che la connessione tra tutti i nodi controller e i nodi gestiti è buona e testata correttamente.
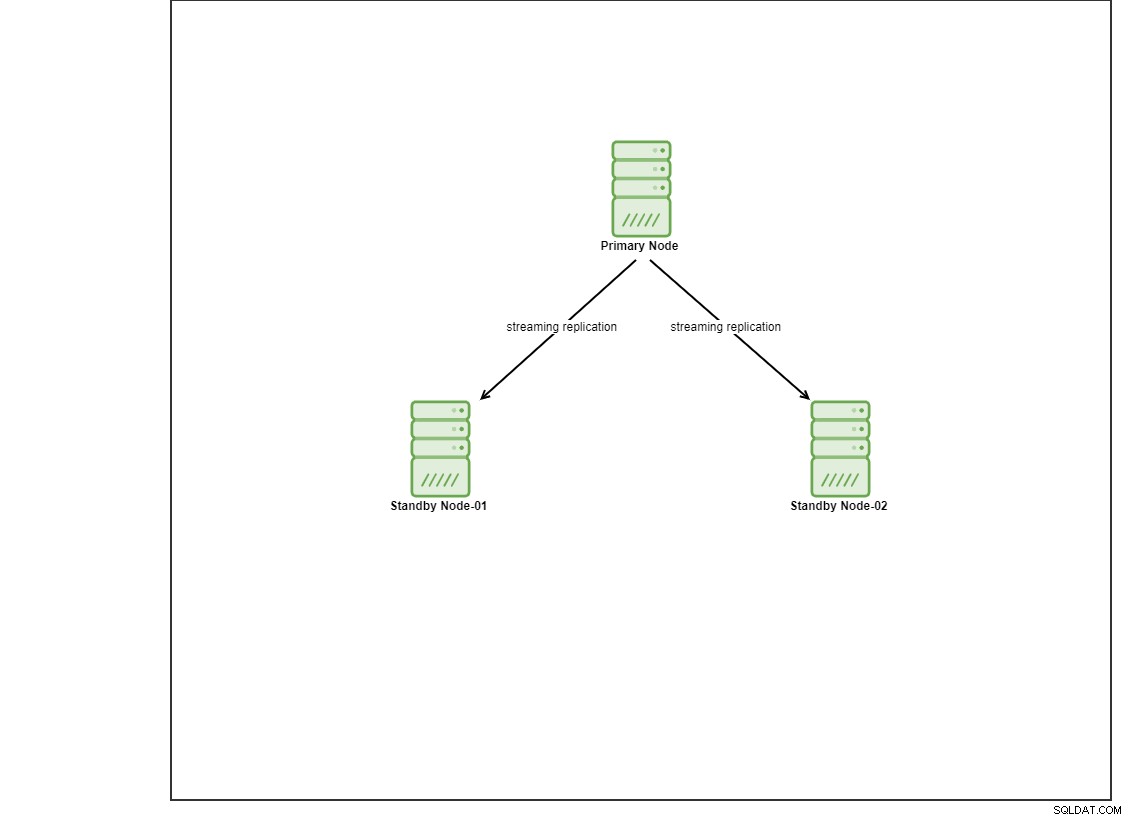
Per questa demo, ho eseguito il provisioning di 4 Centos 8 VM utilizzando vagrant. Uno fungerà da nodo controller e le altre 2 VM fungeranno da nodi di database da distribuire. Non entreremo nei dettagli su come installare Ansible in questo post del blog, ma nel caso in cui desideri vedere la guida, non esitare a visitare questo link. Si noti che stiamo usando 3 nodi per impostare una topologia di replica in streaming, con un nodo primario e 2 nodi di standby. Al giorno d'oggi, molti database di produzione sono in una configurazione ad alta disponibilità e una configurazione a 3 nodi è comune.
Installazione di PostgreSQL
Ci sono diversi modi per installare PostgreSQL usando Ansible. Oggi userò Ansible Roles per raggiungere questo scopo. Ansible Roles in poche parole è un insieme di attività per configurare un host per servire un determinato scopo come la configurazione di un servizio. I ruoli Ansible vengono definiti utilizzando file YAML con una struttura di directory predefinita disponibile per il download dal portale Ansible Galaxy.
Ansible Galaxy, d'altra parte, è un repository per Ansible Roles che possono essere inseriti direttamente nei tuoi Playbook per semplificare i tuoi progetti di automazione.
Per questa demo, ho scelto i ruoli che sono stati mantenuti da dudefellah. Per poter utilizzare questo ruolo, dobbiamo scaricarlo e installarlo nel nodo del controller. L'attività è piuttosto semplice e può essere eseguita eseguendo il comando seguente a condizione che Ansible sia stato installato sul nodo del controller:
$ ansible-galaxy install dudefellah.postgresqlDovresti vedere il seguente risultato una volta che il ruolo è stato installato correttamente nel tuo nodo controller:
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfully
Per poter installare PostgreSQL utilizzando questo ruolo, è necessario eseguire alcuni passaggi. Ecco che arriva l'Ansible Playbook. Ansible Playbook è dove possiamo scrivere codice Ansible o una raccolta di script che vorremmo eseguire sui nodi gestiti. Ansible Playbook utilizza YAML e consiste in una o più riproduzioni eseguite in un ordine particolare. Puoi definire gli host e un insieme di attività che desideri eseguire sugli host assegnati o sui nodi gestiti.
Tutte le attività verranno eseguite come l'utente ansible che ha effettuato l'accesso. Per poter eseguire le attività con un utente diverso, incluso 'root', possiamo fare uso di gets. Diamo un'occhiata a pg-play.yml di seguito:
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13Come puoi vedere, ho definito gli host come pgcluster e ho fatto uso dibe in modo che Ansible esegua le attività con il privilegio sudo. L'utente vagabondo è già nel gruppo sudoer. Ho anche definito il ruolo che ho installato dudefellah.postgresql. pgcluster è stato definito nel file hosts che ho creato. Nel caso ti chiedi come appare, puoi dare un'occhiata qui sotto:
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansibleOltre a questo, ho creato un altro file personalizzato (custom_var.yml) in cui ho incluso tutta la configurazione e le impostazioni per PostgreSQL che vorrei implementare. I dettagli per il file personalizzato sono i seguenti:
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }Per eseguire l'installazione, tutto ciò che dobbiamo fare è eseguire il comando seguente. Non sarai in grado di eseguire il comando ansible-playbook senza il file playbook creato (nel mio caso è pg-play.yml).
$ ansible-playbook pg-play.yml -i pghostDopo aver eseguito questo comando, eseguirà alcune attività definite dal ruolo e mostrerà questo messaggio se il comando è stato eseguito correttamente:
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12Una volta che l'ansible ha completato le attività, ho effettuato l'accesso allo slave (n2), ho interrotto il servizio PostgreSQL, ho rimosso il contenuto della directory dei dati (/var/lib/pgsql/13/data/) ed eseguire il comando seguente per avviare l'attività di backup:
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |Possiamo anche controllare lo stato della replica in standby usando il seguente comando dopo aver riavviato il servizio PostgreSQL:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=anyCome puoi vedere, ci sono molti lavori da fare per poter impostare la replica per PostgreSQL anche se abbiamo automatizzato alcune attività. Vediamo come farlo con ClusterControl.
Distribuzione PostgreSQL utilizzando la GUI ClusterControl
Ora che sappiamo come distribuire PostgreSQL utilizzando Ansible, vediamo come possiamo distribuire utilizzando ClusterControl. ClusterControl è un software di gestione e automazione per cluster di database inclusi MySQL, MariaDB, MongoDB e TimescaleDB. Aiuta a distribuire, monitorare, gestire e ridimensionare il tuo cluster di database. Esistono due modi per distribuire il database, in questo post del blog ti mostreremo come distribuirlo utilizzando l'interfaccia utente grafica (GUI) supponendo che ClusterControl sia già installato nel tuo ambiente.
Il primo passo è accedere a ClusterControl e fare clic su Distribuisci:
Ti verrà presentato lo screenshot seguente per il passaggio successivo della distribuzione , scegli la scheda PostgreSQL per continuare:
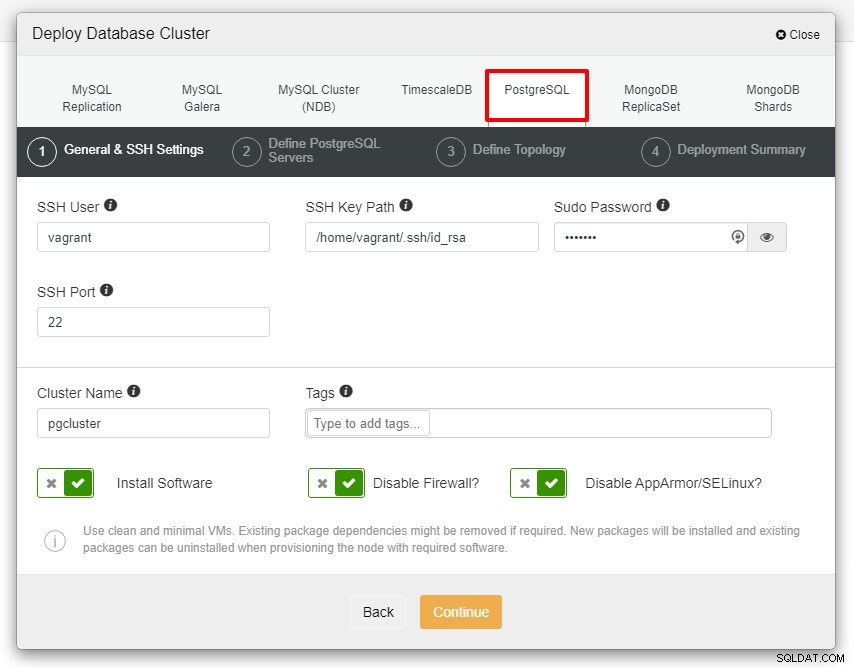
Prima di procedere oltre, vorrei ricordare che la connessione tra il nodo ClusterControl ei nodi database deve essere senza password. Prima della distribuzione, tutto ciò che dobbiamo fare è generare ssh-keygen dal nodo ClusterControl e quindi copiarlo su tutti i nodi. Compila l'input per l'utente SSH, la password Sudo e il nome del cluster in base alle tue esigenze e fai clic su Continua.
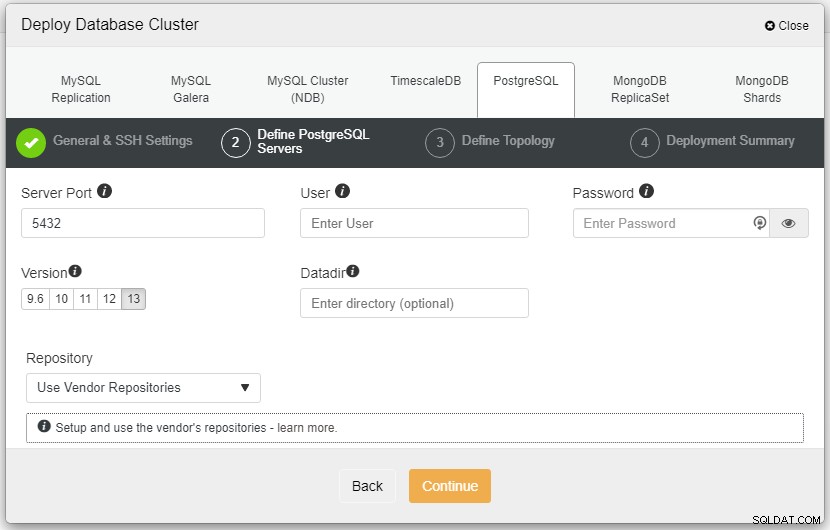
Nello screenshot qui sopra, dovrai definire la Porta del Server (nel caso tu voglia usarne altre), l'utente che vorresti così come la password e la Versione che desideri da installare.
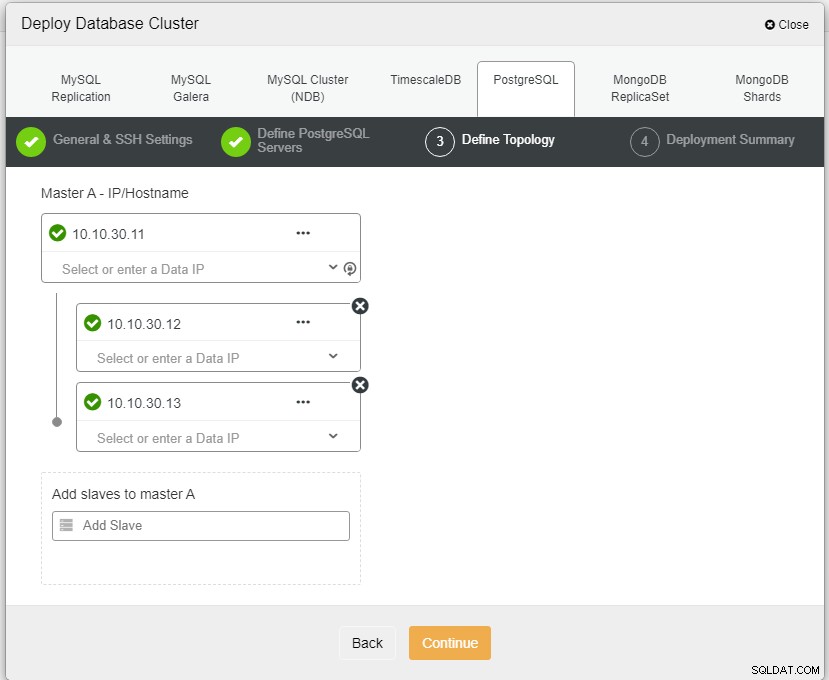
Qui dobbiamo definire i server usando il nome host o l'indirizzo IP, come in questo caso 1 master e 2 slave. Il passaggio finale è scegliere la modalità di replica per il nostro cluster.
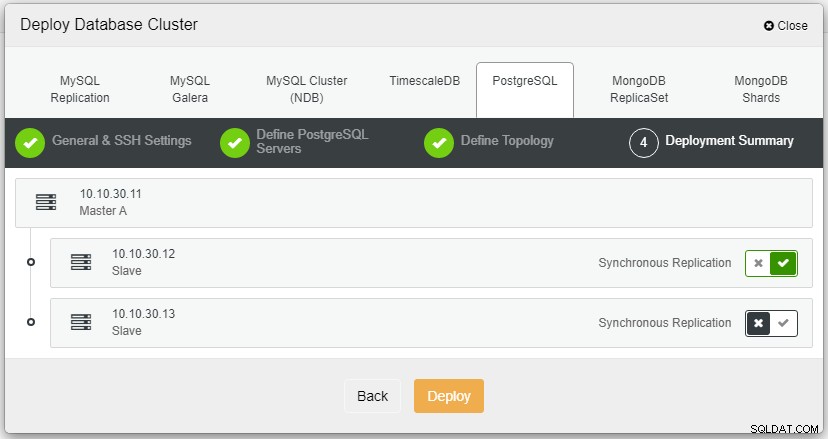
Dopo aver fatto clic su Distribuisci, verrà avviato il processo di distribuzione e potremo monitorare l'avanzamento nella scheda Attività.
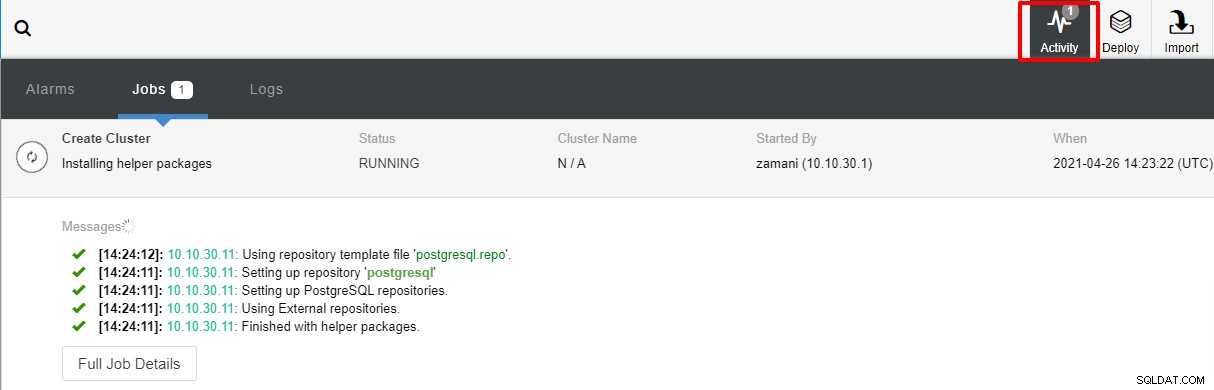
La distribuzione richiede normalmente un paio di minuti, le prestazioni dipendono principalmente dalla rete e dalle specifiche del server.

Ora abbiamo installato PostgreSQL utilizzando ClusterControl.
Distribuzione PostgreSQL utilizzando ClusterControl CLI
L'altro modo alternativo per distribuire PostgreSQL è utilizzare la CLI. a condizione che abbiamo già configurato la connessione senza password, possiamo semplicemente eseguire il comando seguente e lasciarlo terminare.
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logDovresti visualizzare il messaggio seguente una volta che il processo è stato completato correttamente e puoi accedere al Web ClusterControl per verificare:
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.Conclusione
Come puoi vedere, ci sono alcuni modi per distribuire PostgreSQL. In questo post del blog, abbiamo imparato come distribuirlo utilizzando Ansible e anche utilizzando il nostro ClusterControl. Entrambi i modi sono facili da seguire e possono essere raggiunti con una curva di apprendimento minima. Con ClusterControl, la configurazione della replica in streaming può essere integrata con HAProxy, VIP e PGBouncer per aggiungere alla configurazione failover di connessione, IP virtuale e pool di connessioni.
Si noti che la distribuzione è solo un aspetto di un ambiente di database di produzione. Mantenerlo attivo e funzionante, automatizzare i failover, ripristinare i nodi interrotti e altri aspetti come monitoraggio, avvisi e backup sono essenziali.
Se tutto va bene, questo post del blog gioverà ad alcuni di voi e darà un'idea su come automatizzare le distribuzioni di PostgreSQL.