Anche io ho riscontrato questo problema. Fondamentalmente si riduce ad avere un numero variabile di valori nella clausola IN e Hibernate che tenta di memorizzare nella cache quei piani di query.
Ci sono due ottimi post sul blog su questo argomento. Il primo:
Utilizzo di Hibernate 4.2 e MySQL in un progetto con una query in clausola come:select t from Thing t where t.id in (?)
Hibernate memorizza nella cache queste query HQL analizzate. In particolare HibernateSessionFactoryImpl ha QueryPlanCache con queryPlanCache e parameterMetadataCache . Ma questo si è rivelato un problema quando il numero di parametri per la clausola nella clausola è grande e varia.
Queste cache crescono per ogni query distinta. Quindi questa query con 6000parametri non è la stessa di 6001.
La query nella clausola viene espansa al numero di parametri nella raccolta. I metadati sono inclusi nel piano di query per ogni parametro nella query, incluso un nome generato come x10_, x11_ , ecc.
Immagina 4000 diverse variazioni nel numero di conteggi di parametri nella clausola, ognuno di questi con una media di 4000 parametri. I metadati della query per ogni parametro si sommano rapidamente in memoria, riempiendo l'heap, poiché non possono essere raccolti.
Ciò continua fino a quando tutte le diverse variazioni nel conteggio dei parametri della query non vengono memorizzate nella cache o la JVM esaurisce la memoria heap e inizia a throwingjava.lang.OutOfMemoryError:Java heap space.
È possibile evitare le clausole nelle clausole, oltre a utilizzare una dimensione di raccolta fissa per il parametro (o almeno una dimensione inferiore).
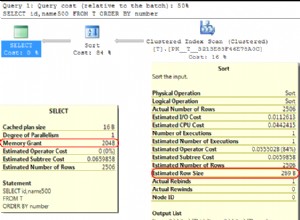
Per configurare la dimensione massima della cache del piano di query, vedere la proprietàhibernate.query.plan_cache_max_size , per impostazione predefinita 2048 (facilmente troppo grande per query con molti parametri).
E secondo (anch'esso richiamato dal primo):
Hibernate utilizza internamente una cache che mappa le istruzioni HQL (asstrings) ai piani di query. La cache è costituita da una mappa limitata limitata per impostazione predefinita a 2048 elementi (configurabili). Tutte le query HQL vengono caricate tramite questa cache. In caso di errore, la voce viene automaticamente aggiunta alla cache. Questo lo rende molto suscettibile al thrashing - scenario in cui inseriamo costantemente nuove voci nella cache senza mai riutilizzarle e quindi impedendo alla cache di apportare miglioramenti alle prestazioni (aggiunge anche un sovraccarico di gestione della cache). A peggiorare le cose, è difficile rilevare questa situazione per caso:devi profilare esplicitamente la cache per notare che hai un problema lì. Dirò alcune parole su come questo potrebbe essere fatto più avanti.
Quindi il cache thrashing risulta dalla generazione di nuove query a tassi elevati. Ciò può essere causato da una moltitudine di problemi. I due più comuni che ho visto sono:bug in ibernazione che causano il rendering dei parametri nell'istruzione JPQL invece di essere passati come parametri e l'uso di una clausola "in" -.
A causa di alcuni bug oscuri in ibernazione, ci sono situazioni in cui i parametri non vengono gestiti correttamente e vengono visualizzati nella JPQLquery (ad esempio, controlla HHH-6280). Se hai una query che è affetta da tali difetti e viene eseguita a velocità elevate, verrà distrutta la cache del tuo piano di query perché ogni query JPQL generata è quasi unica (contenente ad esempio gli ID delle tue entità).
Il secondo problema risiede nel modo in cui l'ibernazione elabora le query con una clausola "in" (ad es. Dammi tutte le entità persona il cui campo ID azienda è uno di 1, 2, 10, 18). Per ogni numero distinto di parametri nella clausola "in", l'ibernazione produrrà una query diversa, ad esempio select x from Person x where x.company.id in (:id0_) per 1 parametro,select x from Person x where x.company.id in (:id0_, :id1_) per 2 parametri e così via. Tutte queste query sono considerate diverse, per quanto riguarda la cache del piano di query, risultando nuovamente in cachethrashing. Probabilmente potresti aggirare questo problema scrivendo una classe di utilità per produrre solo un certo numero di parametri, ad es. 1,10, 100, 200, 500, 1000. Se, ad esempio, si passano 22 parametri, restituirà un elenco di 100 elementi con i 22 parametri inclusi init e i restanti 78 parametri impostati su un valore impossibile (es. -1per ID usato per chiavi esterne). Sono d'accordo sul fatto che questo è un brutto trucco ma potrebbe portare a termine il lavoro. Di conseguenza avrai solo al massimo 6query uniche nella tua cache e quindi ridurrai il thrashing.
Allora come fai a sapere che hai il problema? Potresti scrivere del codice aggiuntivo ed esporre le metriche con il numero di voci nella cache, ad es. su JMX, ottimizza la registrazione e analizza i log, ecc. Se non vuoi (o non puoi) modificare l'applicazione, puoi semplicemente scaricare l'heap ed eseguire questa query OQL su di esso (ad esempio usando mat):SELECT l.query.toString() FROM INSTANCEOF org.hibernate.engine.query.spi.QueryPlanCache$HQLQueryPlanKey l . Emetterà tutte le query attualmente presenti in qualsiasi cache del piano di query sul tuo heap. Dovrebbe essere abbastanza facile individuare se sei affetto da uno dei suddetti problemi.
Per quanto riguarda l'impatto sulle prestazioni, è difficile dirlo in quanto dipende da troppi fattori. Ho visto una query molto banale che causa 10-20 milioni di sovraccarico speso nella creazione di un nuovo piano di query HQL. In generale, se c'è una cache da qualche parte, ci deve essere una buona ragione per questo:sbagliare è probabilmente costoso, quindi dovresti cercare di evitare il più possibile errori. Ultimo ma non meno importante, il tuo database dovrà gestire anche grandi quantità di istruzioni SQL univoche, causandone l'analisi e forse la creazione di piani di esecuzione diversi per ognuna di esse.