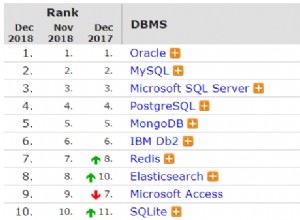
Non riesco a ricordare l'ultima volta in cui ho effettivamente avuto bisogno di utilizzare un cursore esplicito per eseguire il loop in plpgsql.
Usa il cursore implicito di un FOR loop, è molto più pulito:
DO
$$
DECLARE
rec record;
nbrow bigint;
BEGIN
FOR rec IN
SELECT *
FROM pg_tables
WHERE tablename NOT LIKE 'pg\_%'
ORDER BY tablename
LOOP
EXECUTE 'SELECT count(*) FROM '
|| quote_ident(rec.schemaname) || '.'
|| quote_ident(rec.tablename)
INTO nbrow;
-- Do something with nbrow
END LOOP;
END
$$;
Devi includere il nome dello schema per farlo funzionare per tutti gli schemi (inclusi quelli non presenti nel tuo search_path ).
Inoltre, hai effettivamente necessità per utilizzare quote_ident() o format() con %I o una regclass variabile per proteggersi dall'iniezione SQL. Il nome di una tabella può essere quasi qualsiasi tra virgolette doppie. Vedi:
- Nome tabella come parametro di funzione PostgreSQL
Dettaglio minore:sfuggire al trattino basso (_ ) nel LIKE pattern per renderlo un letterale underscore:tablename NOT LIKE 'pg\_%'
Come potrei farlo:
DO
$$
DECLARE
tbl regclass;
nbrow bigint;
BEGIN
FOR tbl IN
SELECT c.oid
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = 'r'
AND n.nspname NOT LIKE 'pg\_%' -- system schema(s)
AND n.nspname <> 'information_schema' -- information schema
ORDER BY n.nspname, c.relname
LOOP
EXECUTE 'SELECT count(*) FROM ' || tbl INTO nbrow;
-- raise notice '%: % rows', tbl, nbrow;
END LOOP;
END
$$;
Interroga pg_catalog.pg_class invece di tablename , fornisce l'OID della tabella.
Il tipo di identificatore dell'oggetto regclass è utile semplificare. In particolare, i nomi delle tabelle sono tra virgolette doppie e, se necessario, qualificati automaticamente dallo schema (impedisce anche l'iniezione SQL).
Questa query esclude anche le tabelle temporanee (lo schema temporaneo è denominato pg_temp% internamente).
Per includere solo tabelle da un determinato schema:
AND n.nspname = 'public' -- schema name here, case-sensitive