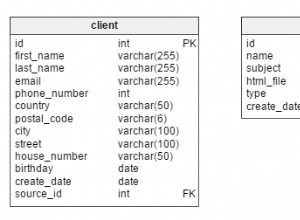
Correggi il LEFT JOIN
Questo dovrebbe funzionare:
SELECT o.name AS organisation_name, count(e.id) AS total_used
FROM organisations o
LEFT JOIN exam_items e ON e.organisation_id = o.id
AND e.item_template_id = #{sanitize(item_template_id)}
AND e.used
GROUP BY o.name
ORDER BY o.name;
Hai avuto un LEFT [OUTER] JOIN ma il successivo WHERE le condizioni lo facevano agire come un semplice [INNER] JOIN .
Sposta le condizioni in JOIN clausola per farlo funzionare come previsto. In questo modo, vengono unite in primo luogo solo le righe che soddisfano tutte queste condizioni (o le colonne da destra la tabella è riempita con NULL). Come hai fatto tu, le righe unite vengono testate per condizioni aggiuntive praticamente dopo il LEFT JOIN e rimossi se non passano, proprio come con un semplice JOIN .
count() non restituisce mai NULL per cominciare. È un'eccezione tra le funzioni aggregate a questo riguardo. Pertanto, COALESCE(COUNT(col))
Va notato che tranne count , queste funzioni restituiscono un valore nullo quando non sono selezionate righe.
Enfasi in grassetto mio. Vedi:
- Conta il numero di attributi NULL per una riga
count() deve trovarsi su una colonna definita NOT NULL (come e.id ), o dove la condizione di unione garantisce NOT NULL (e.organisation_id , e.item_template_id o e.used ) nell'esempio.
Dal momento che used è di tipo boolean , l'espressione e.used = true è un rumore che si riduce solo a e.used .
Dal momento che o.name non è definito UNIQUE NOT NULL , potresti voler GROUP BY o.id invece (id essendo il PK) - a meno che tu non intenda per piegare righe con lo stesso nome (incluso NULL).
Prima aggrega, poi unisciti
Se la maggior parte o tutte le righe di exam_items vengono conteggiati nel processo, questa query equivalente è in genere notevolmente più veloce/economica:
SELECT o.id, o.name AS organisation_name, e.total_used
FROM organisations o
LEFT JOIN (
SELECT organisation_id AS id -- alias to simplify join syntax
, count(*) AS total_used -- count(*) = fastest to count all
FROM exam_items
WHERE item_template_id = #{sanitize(item_template_id)}
AND used
GROUP BY 1
) e USING (id)
ORDER BY o.name, o.id;
(Questo presuppone che tu non voglia piegare righe con lo stesso nome come menzionato sopra - il caso tipico.)
Ora possiamo usare il più veloce/semplice count(*) nella sottoquery e non abbiamo bisogno di GROUP BY nel SELECT esterno .
Vedi:
- Più chiamate array_agg() in una singola query