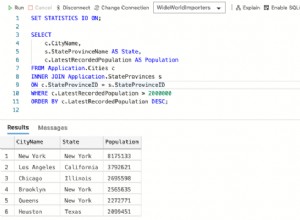
Utilizzando l'id sequenziale sarebbe più semplice in quanto è probabilmente (?) una chiave primaria e quindi indicizzata e di accesso più rapido. Dato che hai user_id , puoi affermare rapidamente le ultime modifiche e quelle precedenti.
Usando il timestamp è anche applicabile, ma è probabile che sia una voce più lunga e non sappiamo se sia indicizzata, oltre al potenziale di collisioni. Sottolinei giustamente che gli orologi di sistema possono cambiare... Mentre id sequenziale Non è possibile.
Dato il tuo aggiornamento:
Poiché è difficile vedere quali sono i tuoi requisiti esatti, l'ho incluso come prova di ciò che un particolare progetto richiedeva per oltre 200.000 documenti complessi e milioni di revisioni.
Dalla mia esperienza (costruzione di un sistema di documentazione/profilazione completamente verificabile) per un team interno di oltre 60 ricercatori a tempo pieno. Abbiamo finito per usare entrambi un id e una serie di altri campi (incluso timestamp ) per fornire audit-trailing e controllo delle versioni completo.
Il sistema che abbiamo costruito ha più di 200 campi per ogni profilo e quindi il controllo delle versioni di un documento era molto più complesso della semplice memorizzazione di un blocco di testo/contenuto modificato per ciascuno; Tuttavia, ogni profilo potrebbe essere, modificato, approvato, rifiutato, ripristinato, pubblicato e persino esportato come PDF o altro formato come UN UNICO documento.
Quello che abbiamo finito per fare (dopo un sacco di strategia/pianificazione) è stato memorizzare versioni sequenziali del profilo, ma erano chiave principalmente su un id campo .
Data e ora
I timestamp sono stati acquisiti anche come controllo secondario e ci siamo assicurati di mantenere gli orologi di sistema accurati (tra un cluster di server) attraverso l'uso di script cron che controllavano regolarmente l'allineamento temporale e li correggevano ove necessario. Abbiamo anche usato Ntpd per evitare la deriva dell'orologio.
Altri dati acquisiti
Altri dati acquisiti per ogni modifica includevano anche (ma non solo):
User_id
User_group
Action
Approval_id
C'erano anche altre tabelle che soddisfacevano i requisiti interni (comprese le annotazioni generate automaticamente per i documenti), poiché alcune delle modifiche al profilo venivano eseguite utilizzando i dati dei bot (creati utilizzando NER/machine learning/AI), ma con l'approvazione richiesta da uno dei il team prima che le modifiche/gli aggiornamenti possano essere pubblicati.
È stato inoltre tenuto un registro delle azioni di tutte le azioni dell'utente, in modo che, in caso di controllo, si potesse guardare le azioni di un singolo utente - anche quando non disponevano dei permessi per eseguire tale azione, veniva comunque registrato .
Per quanto riguarda la migrazione, non lo vedo come un grosso problema, poiché puoi facilmente preservare le sequenze di ID nello spostamento/scaricamento/trasferimento dei dati. Forse l'unico problema è se è necessario unire i set di dati. In tal caso potresti sempre scrivere un copione di migrazione, quindi da una prospettiva personale ritengo che lo svantaggio sia in qualche modo diminuito.
Potrebbe valere la pena esaminare le strutture della tabella Stack Overflow per l'esploratore di dati (che è ragionevolmente sofisticato). Puoi vedere la struttura della tabella qui:https://data.stackexchange.com/stackoverflow/query /nuovo , che deriva da una domanda su meta:Come archivia SO revisioni?
Come sistema di revisione, SO funziona bene e la funzionalità di markdown/revisione è probabilmente un buon esempio da prendere in considerazione.