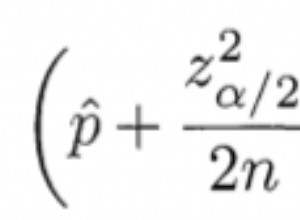Questo utilizza il concetto di cross join alias Prodotto cartesiano (tutte le permutazioni). Quindi i tuoi array producono una tabella derivata (in memoria) con un conteggio di righe di x*y*z , dove quelle x,y,z sono le dimensioni degli array. Se hai fornito matrici di dimensioni 3,4 e 5, la tabella derivata avrebbe un conteggio di righe di 3*4*5=60.
La corrispondenza dell'array fornita che produce una riga era solo 4*1*1=4
thing7 di seguito è riportata la tabella principale che stai cercando. L'covering index dovrebbe far volare questa cosa anche con una tonnellata di dati al suo interno. Un indice di copertura è quello in cui le informazioni fornite sono fornite tramite la scansione dell'albero b dell'indice e che non è richiesta la lettura di una pagina di dati. Come mai? Perché i dati necessari sono nell'indice. E nel tuo caso, estremamente sottile.
Le tabelle A B C sono da utilizzare come array.
L'unica altra cosa da dire è che ogni tabella derivata richiede un nome. Quindi gli abbiamo dato il nome xDerived nella domanda. Pensa a una tabella derivata come a qualcosa restituito e utilizzato in memoria. Non è un tavolo fisico.
Schema
create table thing7
( id int auto_increment primary key,
A int not null,
B int not null,
C int not null,
index(A,B,C) -- covering index (uber-thin, uber-fast)
);
insert thing7(A,B,C) values
(1,2,7),
(1,2,8),
(2,2,1),
(1,3,1);
create table A
( id int auto_increment primary key,
value int
);
create table B
( id int auto_increment primary key,
value int
);
create table C
( id int auto_increment primary key,
value int
);
Test 1
truncate table A;
truncate table B;
truncate table C;
insert A (value) values (1),(2),(3),(4);
insert B (value) values (2);
insert C (value) values (7);
select t7.*
from thing7 t7
join
( select A.value as Avalue, B.value as Bvalue, C.value as Cvalue
from A
cross join B
cross join C
order by a.value,b.value,c.value
) xDerived
on xDerived.Avalue=t7.A and xDerived.Bvalue=t7.B and xDerived.Cvalue=t7.C;
+----+---+---+---+
| id | A | B | C |
+----+---+---+---+
| 1 | 1 | 2 | 7 |
+----+---+---+---+
..
Test 2
truncate table A;
truncate table B;
truncate table C;
insert A (value) values (1);
insert B (value) values (2);
insert C (value) values (0);
select t7.*
from thing7 t7
join
( select A.value as Avalue, B.value as Bvalue, C.value as Cvalue
from A
cross join B
cross join C
order by a.value,b.value,c.value
) xDerived
on xDerived.Avalue=t7.A and xDerived.Bvalue=t7.B and xDerived.Cvalue=t7.C;
-- no rows returned
Sarebbe molto facile trasformarlo in una ricerca basata sulla sessione. Il concetto è quello in cui gli array da cercare (tabelle A B C) hanno una colonna di sessione. Faciliterebbe quindi l'uso simultaneo multiutente. Ma questa è una risposta troppo ingegneristica, ma chiedi se desideri maggiori informazioni al riguardo.