Sembra che ti interessi:
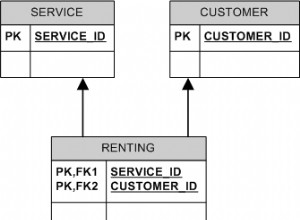
-- a and b are related by the association of interest
Foo(a, b)
-- foo(a, b) but not foo(a2, b) for some a2 <> a
Boring(a, b)
unique(b)
FK (a, b) references Foo
-- foo(a, b) and foo(a2, b) for some a2 <> a
Rare(a, b)
FK (a, b) references foo
Se vuoi domande per essere libero, basta definire Foo. Puoi interrogarlo per Rare.
Rare = select * from Foo f join Foo f2
where f.a <> f2.a and f.b = f2.b
Qualsiasi altro progetto soffre della complessità dell'aggiornamento nel mantenere coerente il database.
Hai qualche confusa preoccupazione sul fatto che Rare sia molto più piccolo di Foo. Ma qual è la tua esigenza ci sono solo n su un milione di record Foo essendo molti:molti con cui sceglieresti qualche altro design?
Il livello successivo di complessità è avere Foo e Rare. Gli aggiornamenti devono mantenere l'equazione di cui sopra vera.
Sembra estremamente improbabile che ci sia un vantaggio nel ridurre la ridondanza di 2 o 3 su un milione di Foo + Rare avendo solo Boring + Rare e ricostruendo Foo da loro. Ma può essere utile definire un indice univoco (b) per Boring che affermerà che a b in esso contiene solo una a. Quando hai bisogno di Foo:
Foo = select * from Boring union select * from Rare
Ma i tuoi aggiornamenti devono mantenerlo
not exists (select * from Boring b join Rare r where b.b = r.b)