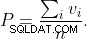Se non hai assolutamente dati sul tuo problema, sei costretto a fare un preventivo.
La forma generale di tale formula è spiegata nei commenti:
- se utilizziamo solo una colonna chiave (
x) di un indice multicolonna (conccolonne), otteniamoarighe (1% delle righe totali). Quindi perx=1, il risultato èaper definizione. - se conosciamo il valore per ogni colonna chiave di un indice multicolonna, otteniamo il numero di righe per chiave intera (
b); quindi perx=c, otteniamobrighe (che è 1 o 10 ) per definizione. - tra (se utilizziamo valori chiave per più di 1 colonna chiave, ma non per tutte), per ogni valore chiave noto aggiuntivo, possiamo escludere alcune righe aggiuntive:abbiamo
a-brighe che non apparterranno al caso in cui conosciamo il nostro completo chiave (che avrebbebrighe), e per definizione sono escluse proporzionalmente al rapporto delle colonne di tasti utilizzabili ((x-1)/(c-1)). - Il
-1in(x-1)/(c-1)è solo uno spostamento (potresti semplicemente usare nomi di variabili diversi), poiché abbiamo solo bisogno di contare il aggiuntivo colonne, macexè il conteggio inclusa la prima colonna. (In una serie temporale, chiamereste il parametro per la prima colonnat=0e il-1fa esattamente questo).
Quindi in conclusione otteniamo a - (a-b) * (x-1)/(c-1) (a per la prima colonna chiave meno le righe che escludiamo proporzionalmente). Questa è (se trasformi un po' quell'espressione) esattamente la formula data. Un rapido controllo di integrità:per x=1 (x-1=0 ), il secondo termine è 0 e otteniamo a , come definito dalla prima condizione; per x=c , otteniamo a-(a-b)=b come definito dalla seconda condizione.
Non è irragionevole fare questo ansatz usando questi presupposti, ma probabilmente puoi trovare una formula diversa che abbia altrettanto senso. Sostenere che è meglio sarebbe comunque un compito più difficile.
Poi c'è la questione della scelta dei valori (b=10 e 1% in questo caso). Ovviamente puoi scegliere qualsiasi valore. Per fare questo senza alcun dato affidabile tranne una sensazione viscerale, esiste un concetto chiamato stima di Fermi :
Fondamentalmente scegli solo l'ordine di magnitudo (1, 1000000, 1/100) per i tuoi parametri di input e ottieni un ordine di grandezza ragionevole per il tuo risultato.
Quindi quante righe ti aspetti da coprire una chiave non univoca? È più di 1, altrimenti la renderesti una chiave univoca, ma è più simile a 2, 10 o 100? 10 è probabilmente una buona ipotesi (copre il valore da circa 3 a 30 in quella stima). Quindi, sebbene questi numeri possano provenire da un'indagine mondiale di 2 anni sulla distribuzione delle chiavi, i valori stimati in poteri di 10 sono generalmente derivati in questo modo. Se vuoi essere assolutamente certo, chiedi allo sviluppatore.
E il xkcd obbligatorio per questo tipo di argomenti:What-if? Dipingi la Terra