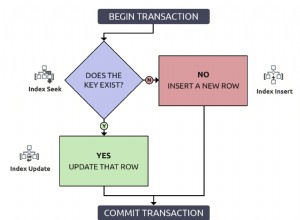
Introduzione
Al momento le tue condizioni di corrispondenza potrebbero essere troppo ampie. Tuttavia, puoi usare la distanza di Levenshtein per controllare le tue parole. Potrebbe non essere troppo facile raggiungere tutti gli obiettivi desiderati con esso, come la somiglianza del suono. Pertanto, ti suggerisco di dividere il tuo problema in altri problemi.
Ad esempio, puoi creare un controllo personalizzato che utilizzerà l'input richiamabile passato che prende due stringhe e quindi risponde alla domanda se sono uguali (per levenshtein quella sarà una distanza minore di un valore, per similar_text - una certa percentuale di somiglianza e t.c. - sta a te definire le regole).
Somiglianza, basata sulle parole
Bene, tutte le funzioni integrate falliranno se stiamo parlando di case quando stai cercando una corrispondenza parziale, specialmente se si tratta di una corrispondenza non ordinata. Pertanto, dovrai creare uno strumento di confronto più complesso. Hai:
- Stringa di dati (che sarà nel DB, per esempio). Sembra D =D0 D1 D2 ... Dn
- Stringa di ricerca (che sarà l'input dell'utente). Sembra S =S0 S1 ... Sm
Qui i simboli di spazio significano qualsiasi spazio (presumo che i simboli di spazio non influiranno sulla somiglianza). Anche n > m . Con questa definizione il tuo problema sta per trovare l'insieme di m parole in D che sarà simile a S . Per set Intendo qualsiasi sequenza non ordinata. Quindi, se troveremo qualsiasi sequenza del genere in D , quindi S è simile a D .
Ovviamente, se n < m quindi l'input contiene più parole della stringa di dati. In questo caso potresti pensare che non siano simili o agire come sopra, ma scambiare dati e input (che, tuttavia, sembra un po' strano, ma è applicabile in un certo senso)
Attuazione
Per fare le cose, dovrai essere in grado di creare un insieme di stringhe che sono parti di m parole da D . Sulla base della mia questa domanda
puoi farlo con:
protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-quindi per qualsiasi array, getAssoc() restituirà un array di selezioni non ordinate composte da m articoli ciascuno.
Il passo successivo riguarda l'ordine nella selezione dei prodotti. Dovremmo cercare in entrambi Niels Andersen e Andersen Niels nel nostro D corda. Pertanto, dovrai essere in grado di creare permutazioni per array. È un problema molto comune, ma metterò anche la mia versione qui:
protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
Dopodiché sarai in grado di creare selezioni di m parole e quindi, permutando ciascuna di esse, ottieni tutte le varianti da confrontare con la stringa di ricerca S . Tale confronto verrà effettuato ogni volta tramite alcuni callback, come levenshtein . Ecco un esempio:
public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
Questo verificherà la somiglianza, in base alla richiamata dell'utente, che deve accettare almeno due parametri (cioè stringhe confrontate). Inoltre potresti voler restituire la stringa che ha attivato il ritorno positivo della richiamata. Tieni presente che questo codice non differirà da maiuscolo e minuscolo, ma potresti non volere un tale comportamento (quindi sostituisci semplicemente strtolower() ).
Un esempio di codice completo è disponibile in questo elenco (Non ho usato sandbox poiché non sono sicuro di quanto tempo sarà disponibile l'elenco del codice). Con questo esempio di utilizzo:
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
otterrai risultati come:
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
-qui è una demo per questo codice, per ogni evenienza.
Complessità
Dal momento che non ti preoccupi solo di qualsiasi metodo, ma anche di quanto è buono, potresti notare che tale codice produrrà operazioni piuttosto eccessive. Voglio dire, almeno, la generazione di parti di archi. La complessità qui è composta da due parti:
- Parte per la generazione di parti di stringhe. Se vuoi generare tutte le parti di stringa, dovrai farlo come ho descritto sopra. Possibile punto da migliorare:generazione di insiemi di stringhe non ordinati (che precede la permutazione). Ma dubito ancora che si possa fare perché il metodo nel codice fornito li genererà non con "forza bruta", ma poiché sono calcolati matematicamente (con cardinalità di
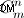 )
) - Parte di verifica della somiglianza. Qui la tua complessità dipende dal controllo di somiglianza dato. Ad esempio,
similar_text()ha complessità O(N), quindi con insiemi di confronto di grandi dimensioni sarà estremamente lento.
Ma puoi comunque migliorare la soluzione attuale con il controllo al volo. Ora questo codice genererà prima tutte le sottosequenze di stringhe e quindi inizierà a controllarle una per una. In casi comuni non è necessario farlo, quindi potresti voler sostituirlo con il comportamento, quando dopo aver generato la sequenza successiva verrà immediatamente verificato. Quindi aumenterai le prestazioni per le stringhe che hanno una risposta positiva (ma non per quelle che non hanno corrispondenza).