Sono sorpreso che uno dei due sia veloce. Suggerirei di sostituirli con exists :
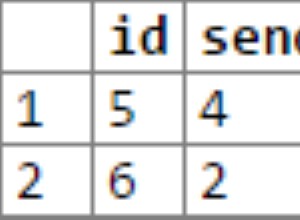
SELECT COUNT(*)
FROM ips_usuario u
WHERE EXISTS (SELECT 1 FROM ips_fatura f WHERE u.id = f.ips_usuario_id) OR
EXISTS (SELECT 1 FROM ips_fatura f WHERE u.ips_usuario_id_titular = f.ips_usuario_id);
E per il secondo:
SELECT COUNT(*)
FROM ips_usuario u
WHERE EXISTS (SELECT 1 FROM ips_fatura f WHERE u.id = f.ips_usuario_id) OR
(u.ips_usuario_id_titular IS NOT NULL AND
EXISTS (SELECT 1 FROM ips_fatura f WHERE u.ips_usuario_id_titular = f.ips_usuario_id)
)
Per entrambi, vuoi due indici:ips_fatura(ips_usuario_id) e ips_fatura(ips_usuario_id_titular) . Puoi controllare la spiegazione per essere sicuro che EXISTS sta usando l'indice. In caso contrario, le versioni più recenti di MySQL utilizzano gli indici per IN :
SELECT COUNT(*)
FROM ips_usuario u
WHERE u.id IN (SELECT f.ips_usuario_id FROM ips_fatura f) OR
u.ips_usuario_id_titular IN (SELECT f.ips_usuario_id FROM ips_fatura f);
In entrambi i casi (EXISTS o IN ) l'obiettivo è fare un "semi join". Cioè, per multare solo la prima riga con una corrispondenza piuttosto che tutte le partite. Questa è un'efficienza importante, perché consente alla query di evitare la rimozione della duplicazione.
Suppongo che il problema sia l'ottimizzazione del or -- di solito questo si traduce in un JOIN inefficiente algoritmi. Tuttavia, forse MySQL è intelligente nel tuo primo caso. Ma l'aggiunta di IS NULL al tavolo esterno lo getta via.