Quello di cui stai parlando è un processo di clustering del testo. Stai cercando di trovare parti di testo simili e di sceglierne una arbitrariamente. Non ho familiarità con nessun database che esegua questa forma di estrazione di testo.
Per quello che descrivi, una tecnica di estrazione di testo piuttosto semplice probabilmente funzionerebbe. Crea una matrice termine-documento con tutte le parole tranne i nomi utente. Quindi utilizzare la scomposizione del valore singolare per ottenere il valore singolare e il vettore più grandi (questo è il primo componente principale della matrice di correlazione). Le attività simili dovrebbero raggrupparsi lungo questa linea.
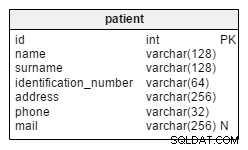
Se hai un vocabolario limitato e hai i termini in una tabella, puoi misurare la distanza tra due azioni in base alla proporzione di parole che si sovrappongono. Hai un elenco di tutte le parole nelle azioni?