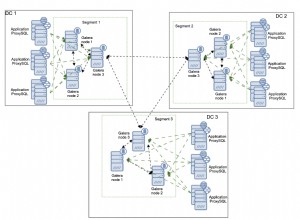
Per memorizzazione nella cache delle query, intendevo CachedSqlEntityProcessor . Preferisco il fuso soluzione come nell'altra domanda MySQL GROUP_CONCAT voci duplicate . Ma anche CachedSqlEntityProcessor aiuterà, se p_id ripetuto più e più volte nel set di risultati della query principale publication_authors e ti preoccupi meno dell'utilizzo della memoria extra.
Aggiornamento:sembra che tu abbia altre due domande risolte, probabilmente puoi andare in entrambi i modi, pubblico il breve esempio/puntatore come hai richiesto comunque nel caso in cui altri lo trovino utile avere
<entity name="x" query="select * from x">
<entity name="y" query="select * from y" processor="CachedSqlEntityProcessor" where="xid=x.id">
</entity>
<entity>
Questo esempio è stato tratto da wiki . Questo eseguirà comunque ogni query "select * from y where xid=id" per id dalla query principale "select * from x". Ma non invierà ripetutamente la stessa query.