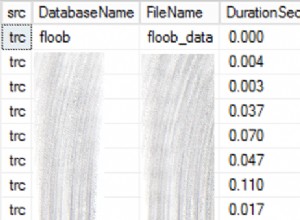
Penso che il problema sia che HAVING viene applicato dopo GROUP BY, ma ancora prima della fase SELECT. Mi rendo conto che è fonte di confusione perché la clausola HAVING fa riferimento a una colonna dell'istruzione SELECT, ma penso che fondamentalmente esegua semplicemente tutto ciò che è nell'istruzione SELECT due volte:una volta per avere, e poi di nuovo per SELECT.
Ad esempio, vedi questa risposta .
Nota, è particolarmente confuso perché se fai riferimento a un nome di colonna che non appare nell'istruzione SELECT in una clausola HAVING genererà un errore.
Ad esempio, questo violino
Ma come per quel violino sopra, ti consentirà comunque di filtrare effettivamente in base al risultato di una funzione che non appare nell'output. Per farla breve, la clausola HAVING sta ancora facendo quello che vuoi, ma non puoi sia filtrare su un valore casuale che visualizzarlo allo stesso tempo usando quell'approccio. Se è necessario farlo, è necessario utilizzare prima una sottoquery per correggere il valore, quindi la query esterna può filtrare e visualizzare su di essa.
Inoltre, per chiarire, probabilmente vale la pena semplicemente usare RAND() nella clausola have, non nella parte SQL. Anche se ho capito che questa domanda sta chiedendo perché sta facendo questo invece di cercare di risolvere il problema in modo specifico.