Ahi... non è così che funziona MySQL Cluster.
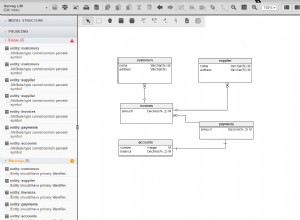
Per impostazione predefinita, MySQL Cluster partiziona i dati sulla CHIAVE PRIMARIA. È tuttavia possibile utilizzare il partizionamento definito dall'utente e la partizione su parte della CHIAVE PRIMARIA. Ciò è estremamente utile per raggruppare i dati correlati e per garantire la localizzazione dei dati all'interno di una partizione. Poiché i dati correlati vengono quindi conservati in una partizione, è quindi possibile scalare da 2 a 48 nodi di dati senza sacrificare le prestazioni:sarà costante. Maggiori dettagli su https://dev.mysql.com/doc/refman/5.5/en/partitioning-key.html
Per impostazione predefinita, l'API calcolerà un hash (utilizzando l'algoritmo LH3*, che utilizza md5) sulla CHIAVE PRIMARIA (o la parte definita utilizzata della chiave primaria) per determinare quale partizione inviare una query. L'hash calcolato è 128 bit e 64 bit determinano la partizione e 64 bit determinano la posizione in un indice hash sulla partizione. Come utente non hai la comprensione esatta di quale nodo contiene i dati (o chi memorizzerà i dati), ma in pratica non importa.
Per quanto riguarda la domanda originale sulla distribuzione di un cluster MySQL su 2 cloud e il partizionamento dei dati. I nodi di dati necessitano di un accesso affidabile a bassa latenza l'uno all'altro, quindi non vorrai distribuire i nodi a meno che non si trovino a meno di 50-100 miglia l'uno dall'altro.