Ecco un'implementazione approssimativa del coefficiente di correlazione del campione come descritto in:
Wikipedia - Correlazione e dipendenza
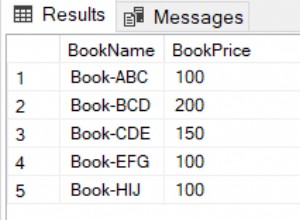
create table sample( x float not null, y float not null );
insert into sample values (1, 10), (2, 4), (3, 5), (6,17);
select @ax := avg(x),
@ay := avg(y),
@div := (stddev_samp(x) * stddev_samp(y))
from sample;
select sum( ( x - @ax ) * (y - @ay) ) / ((count(x) -1) * @div) from sample;
+---------------------------------------------------------+
| sum( ( x - @ax ) * (y - @ay) ) / ((count(x) -1) * @div) |
+---------------------------------------------------------+
| 0.700885077729073 |
+---------------------------------------------------------+