Ho già provato a farlo in precedenza e può diventare molto lento a seconda di quanti filtri consenti e quanti hotel elenchi, per non parlare di come gestisci gli hotel duplicati.
Alla fine, avrai pochissime opzioni di filtro
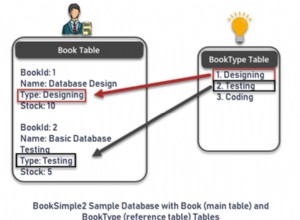
- Tipo di proprietà:normalizzalo in una tabella separata
- Camere da letto:memorizzalo come tinyint o smallint (non firmato), non riesco a immaginare che ci siano proprietà superiori a 255 camere da letto e sicuramente non superiori a 65k
- Posizione:normalizzalo in una tabella separata, idealmente in un formato ad albero per garantire che le relazioni siano annotate
- Classificazione a stelle:può essere memorizzata come tinyint non firmato
Ora il tuo problema qui è che se qualcuno applica un filtro per 3 camere da letto in su, dovresti comunque ottenere valori per 2 camere da letto, 1 camera da letto, poiché la modifica del filtro su quello produrrà risultati.
Alla fine della giornata ho affrontato questo problema utilizzando una tabella di memoria molto grande, una logica per creare istruzioni WHERE e JOIN e una query individuale che conta i record all'interno di un gruppo di set. Questo è stato per fare in modo simile ai risultati di ricerca delle vacanze degli utenti, e in quanto tali i dati sono stati considerati del tutto transitori. Per i tuoi scopi è probabile che sia accettabile una tabella di memoria molto più piccola, tuttavia il principio è simile.