I back-tick sono una cosa MySQL non standard. Usa le virgolette canoniche per citare gli identificatori (possibile anche in MySQL). Cioè, se la tua tabella in effetti si chiama "MY_TABLE" (tutto maiuscolo). Se (più saggiamente) l'hai chiamato my_table (tutto minuscolo), quindi puoi rimuovere le virgolette doppie o utilizzare le lettere minuscole.
Inoltre, uso ct invece di count come alias, perché è una cattiva pratica usare nomi di funzione come identificatori.
Caso semplice
Funzionerebbe con PostgreSQL 9.1 :
SELECT *, count(id) ct
FROM my_table
GROUP BY primary_key_column(s)
ORDER BY ct DESC;
Richiede la/e colonna/e della chiave primaria in GROUP BY clausola. I risultati sono identici a una query MySQL, ma ct sarebbe sempre 1 (o 0 se id IS NULL ) - inutile trovare duplicati.
Raggruppa per colonne chiave diverse da quelle primarie
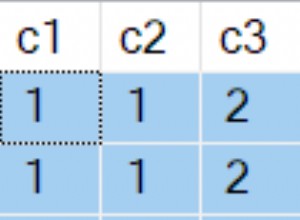
Se vuoi raggruppare per altre colonne, le cose si complicano. Questa query imita il comportamento della tua query MySQL e tu puoi usa * .
SELECT DISTINCT ON (1, some_column)
count(*) OVER (PARTITION BY some_column) AS ct
,*
FROM my_table
ORDER BY 1 DESC, some_column, id, col1;
Funziona perché DISTINCT ON (Specifico per PostgreSQL), come DISTINCT (SQL-Standard), vengono applicati dopo la funzione della finestra count(*) OVER (...) . Funzioni della finestra
(con il OVER clausola) richiedono PostgreSQL 8.4 o versioni successive e non sono disponibili in MySQL.
Funziona con qualsiasi tabella, indipendentemente dai vincoli primari o univoci.
Il 1 in DISTINCT ON e ORDER BY è solo un'abbreviazione per fare riferimento al numero ordinale dell'elemento in SELECT elenco.
SQL Fiddle per dimostrare entrambi fianco a fianco.
Maggiori dettagli in questa risposta strettamente correlata:
count(*) rispetto a count(id)
Se stai cercando duplicati, è meglio con count(*) rispetto a count(id) . C'è una sottile differenza se id può essere NULL , perché NULL i valori non vengono conteggiati - mentre count(*) conta tutte le righe. Se id è definito NOT NULL , i risultati sono gli stessi, ma count(*) è generalmente più appropriato (e anche leggermente più veloce).