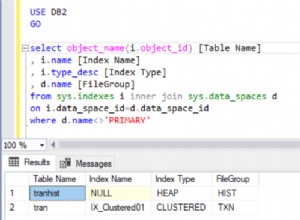
Puoi accedere agli elementi solo tramite la loro chiave primaria in una tabella hash. Questo è più veloce che con un algoritmo ad albero (O(1) invece di log(n) ), ma non puoi selezionare intervalli (tutto tra x e y ).Gli algoritmi dell'albero lo supportano in Log(n) mentre gli indici hash possono comportare una scansione completa della tabella O(n) .Inoltre, il sovraccarico costante degli indici hash è solitamente maggiore (che non è un fattore nella notazione theta, ma esiste ancora ).Anche gli algoritmi ad albero sono generalmente più facili da mantenere, crescere con i dati, scalare, ecc.
Gli indici hash funzionano con dimensioni hash predefinite, quindi ti ritroverai con alcuni "bucket" in cui sono archiviati gli oggetti. Questi oggetti vengono ripetuti nuovamente per trovare quello giusto all'interno di questa partizione.
Quindi, se disponi di dimensioni ridotte, hai un sovraccarico per i piccoli elementi, le dimensioni grandi comportano un'ulteriore scansione.
Gli algoritmi delle tabelle hash odierni di solito si ridimensionano, ma il ridimensionamento può essere inefficiente.
Tuttavia, potrebbe esserci un punto in cui il tuo indice supera una dimensione tollerabile rispetto alle dimensioni dell'hash e l'intero indice deve essere ricostruito. Di solito questo non è un problema, ma per database enormi, questo può richiedere giorni.
Il compromesso per gli algoritmi ad albero è piccolo e sono adatti a quasi tutti i casi d'uso e quindi sono predefiniti.
Tuttavia, se hai un caso d'uso molto preciso e sai esattamente cosa e solo cosa sarà necessario, puoi sfruttare gli indici di hashing.