Lo fa, almeno a volte. Ho testato il comportamento di MySQL Connector/J versione 5.1.37 utilizzando Wireshark. Per la tavola...
CREATE TABLE lorem (
id INT AUTO_INCREMENT PRIMARY KEY,
tag VARCHAR(7),
text1 VARCHAR(255),
text2 VARCHAR(255)
)
... con dati di prova ...
id tag text1 text2
--- ------- --------------- ---------------
0 row_000 Lorem ipsum ... Lorem ipsum ...
1 row_001 Lorem ipsum ... Lorem ipsum ...
2 row_002 Lorem ipsum ... Lorem ipsum ...
...
999 row_999 Lorem ipsum ... Lorem ipsum ...
(where both `text1` and `text2` actually contain 255 characters in each row)
... e il codice ...
try (Statement s = conn.createStatement(java.sql.ResultSet.TYPE_FORWARD_ONLY, java.sql.ResultSet.CONCUR_READ_ONLY)) {
s.setFetchSize(Integer.MIN_VALUE);
String sql = "SELECT * FROM lorem ORDER BY id";
try (ResultSet rs = s.executeQuery(sql)) {
... immediatamente dopo s.executeQuery(sql) – cioè prima di rs.next() viene anche chiamato:MySQL Connector/J ha recuperato le prime ~140 righe dalla tabella.
Infatti, quando si interroga solo il tag colonna
String sql = "SELECT tag FROM lorem ORDER BY id";
MySQL Connector/J ha immediatamente recuperato tutte le 1000 righe come mostrato dall'elenco Wireshark dei frame di rete:
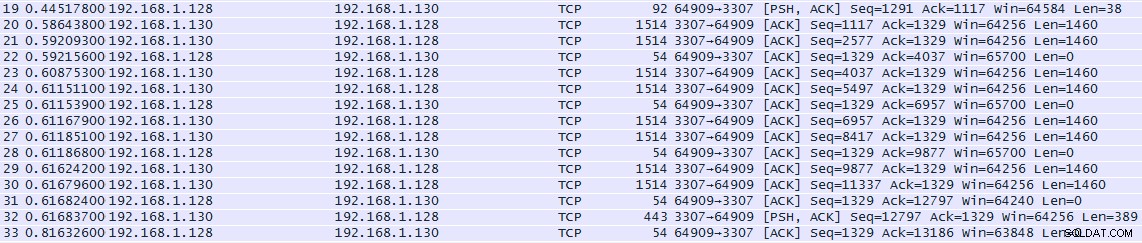
Il frame 19, che ha inviato la query al server, si presentava così:

Il server MySQL ha risposto con il frame 20, che è iniziato con ...
... ed è stato subito seguito dal frame 21, che iniziava con ...

... e così via fino a quando il server non ha inviato il frame 32, che è terminato con
Poiché l'unica differenza era la quantità di informazioni restituite per ogni riga, possiamo concludere che MySQL Connector/J decide una dimensione del buffer appropriata in base alla lunghezza massima di ciascuna riga restituita e alla quantità di memoria libera disponibile.
MySQL Connector/J inizialmente recupera il primo fetchSize gruppo di righe, quindi come rs.next() si sposta attraverso di essi, alla fine recupererà il gruppo di righe successivo. Questo vale anche per setFetchSize(1) che, per inciso, è il modo per davvero ottenere solo una riga alla volta.
(Nota che setFetchSize(n) per n>0 richiede useCursorFetch=true nell'URL di connessione. Apparentemente non è richiesto per setFetchSize(Integer.MIN_VALUE) .)