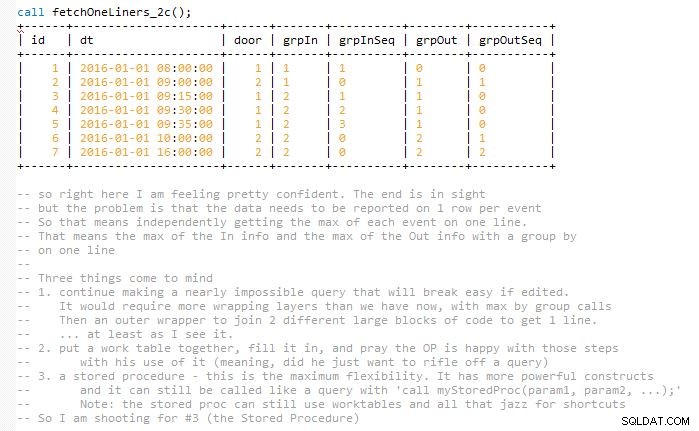
Questo si sforza di mantenere la soluzione facilmente gestibile senza finire la query finale tutto in un colpo che avrebbe quasi raddoppiato le sue dimensioni (nella mia mente). Questo perché i risultati devono essere abbinati e rappresentati su una riga con eventi In e Out abbinati. Quindi, alla fine, utilizzo alcuni tavoli da lavoro. Viene implementato in una procedura memorizzata.
La procedura memorizzata utilizza diverse variabili che vengono introdotte con un cross join . Pensa al cross join solo come un meccanismo per inizializzare le variabili. Le variabili sono mantenute in modo sicuro, quindi credo, nello spirito di questo documento
spesso referenziato nelle query variabili. Le parti importanti del riferimento sono la gestione sicura delle variabili su una riga forzandone l'impostazione prima che altre colonne le utilizzino. Ciò si ottiene tramite greatest() e least() funzioni che hanno una precedenza maggiore rispetto alle variabili impostate senza l'uso di tali funzioni. Nota anche che coalesce() è spesso usato per lo stesso scopo. Se il loro uso sembra strano, come prendere il massimo di un numero noto per essere maggiore di 0 o 0, beh, è deliberato. Deliberato nel forzare l'ordine di precedenza delle variabili impostate.
Le colonne nella query denominavano cose come dummy2 etc sono colonne in cui l'output non è stato utilizzato, ma sono state utilizzate per impostare variabili all'interno, ad esempio, di greatest() oppure un'altra. Questo è stato menzionato sopra. L'output come 7777 era un segnaposto nel terzo slot, poiché era necessario un valore per if() quello è stato usato. Quindi ignora tutto questo.
Ho incluso diverse schermate del codice mentre procedeva strato dopo strato per aiutarti a visualizzare l'output. E come queste iterazioni di sviluppo vengono lentamente ripiegate nella fase successiva per espandere la precedente.
Sono sicuro che i miei colleghi potrebbero migliorare questo in una query. Avrei potuto finirlo in quel modo. Ma credo che avrebbe provocato un pasticcio confuso che si sarebbe rotto se toccato.
Schema:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
Procedura archiviata:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
Test:
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
Questa è la fine della risposta. Quanto segue è per la visualizzazione da parte di uno sviluppatore dei passaggi che hanno portato al completamento della procedura memorizzata.
Versioni di sviluppo che hanno portato fino alla fine. Si spera che questo aiuti nella visualizzazione invece di eliminare semplicemente un blocco di codice confuso di medie dimensioni.
Fase A
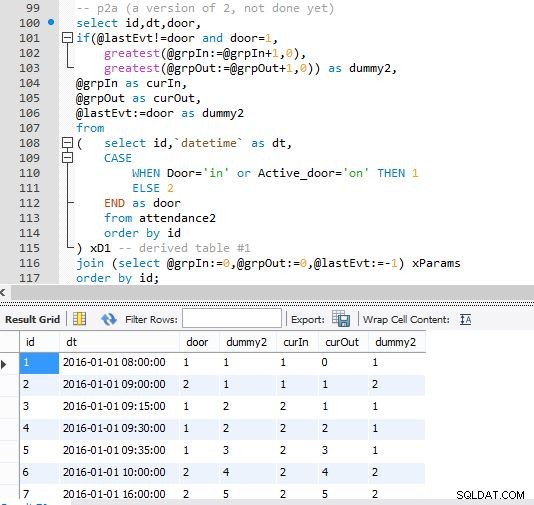
Fase B
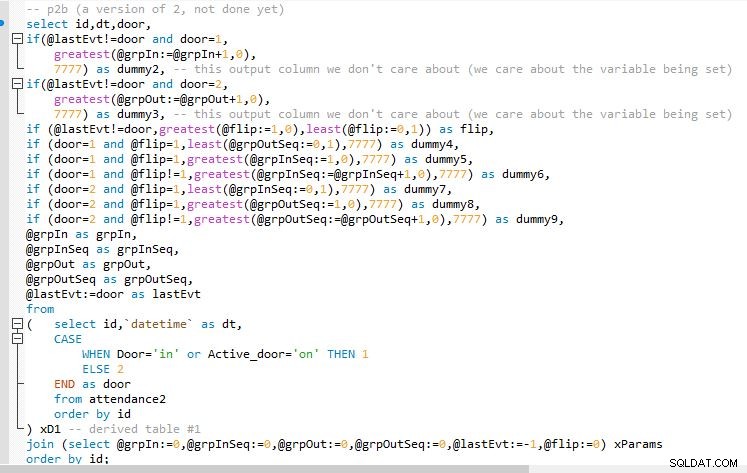
Uscita del passaggio B

Fase C
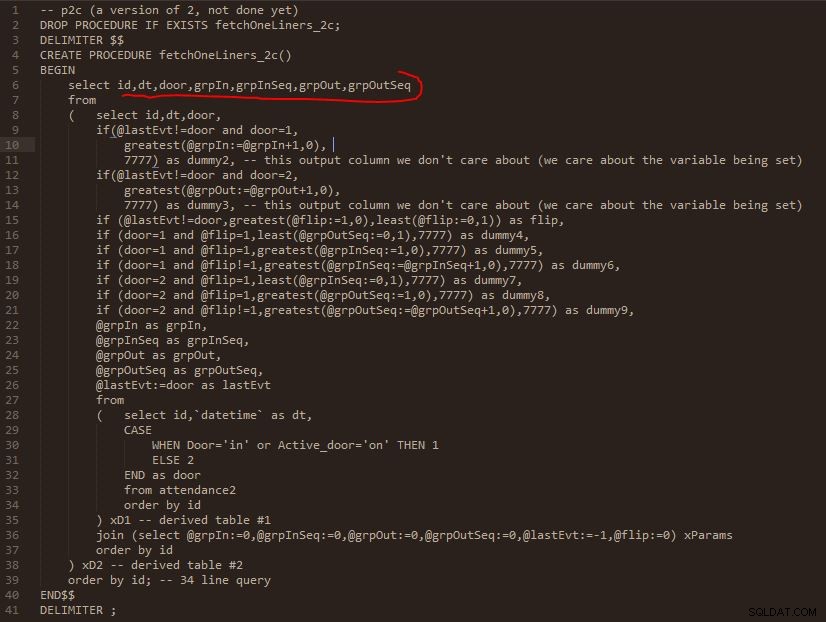
Uscita del passaggio C