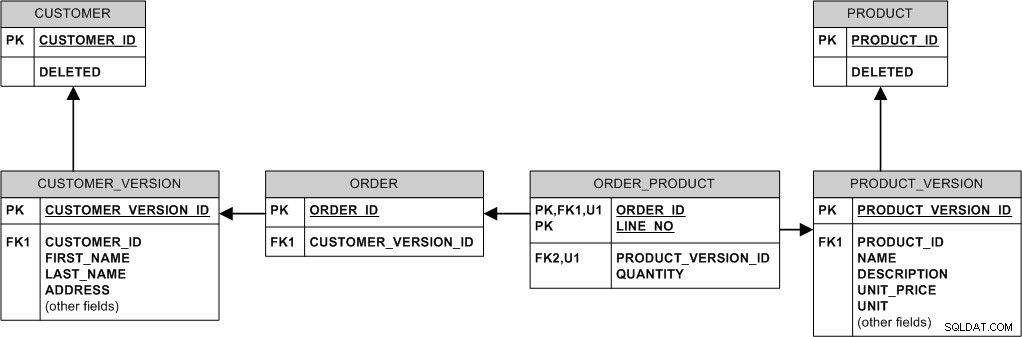
Ecco un modo per farlo:
In sostanza, non modifichiamo o cancelliamo mai i dati esistenti. Lo "modifichiamo" creando una nuova versione. Lo "cancelliamo" impostando il flag DELETED.
Ad esempio:
- Se il prodotto cambia il prezzo, inseriamo una nuova riga in PRODUCT_VERSION mentre i vecchi ordini vengono mantenuti collegati alla vecchia PRODUCT_VERSION e al vecchio prezzo.
- Quando l'acquirente cambia l'indirizzo, inseriamo semplicemente una nuova riga in CUSTOMER_VERSION e colleghiamo i nuovi ordini a quella, mantenendo i vecchi ordini collegati alla vecchia versione.
- Se il prodotto viene eliminato, in realtà non lo eliminiamo:impostiamo semplicemente il flag PRODUCT.DELETED, in modo che tutti gli ordini effettuati storicamente per quel prodotto rimangano nel database.
- Se il cliente viene eliminato (ad es. perché ha chiesto di annullare la registrazione), imposta il flag CLIENTE.DELETED.
Avvertenze:
- Se il nome del prodotto deve essere univoco, non è possibile applicarlo in modo dichiarativo nel modello precedente. Dovrai "promuovere" il NAME da PRODUCT_VERSION a PRODUCT, renderlo una chiave lì e rinunciare alla capacità di "evolvere" il nome del prodotto, oppure imporre l'unicità solo all'ultimo PRODUCT_VER (probabilmente tramite trigger).
- C'è un potenziale problema con la privacy del cliente. Se un cliente viene eliminato dal sistema, potrebbe essere desiderabile rimuovere fisicamente i suoi dati dal database e la semplice impostazione di CUSTOMER.DELETED non lo farà. Se questo è un problema, oscura i dati sensibili alla privacy in tutte le versioni del cliente o, in alternativa, disconnetti gli ordini esistenti dal cliente reale e ricollegali a uno speciale cliente "anonimo", quindi elimina fisicamente tutte le versioni del cliente.
Questo modello utilizza molte relazioni di identificazione. Ciò porta a chiavi esterne "grasse" e potrebbe essere un po' un problema di archiviazione poiché MySQL non supporta la compressione dell'indice all'avanguardia (a differenza, ad esempio, di Oracle), ma d'altra parte InnoDB sempre raggruppa i dati su PK e questo clustering può essere vantaggioso per le prestazioni. Inoltre, le JOIN sono meno necessarie.
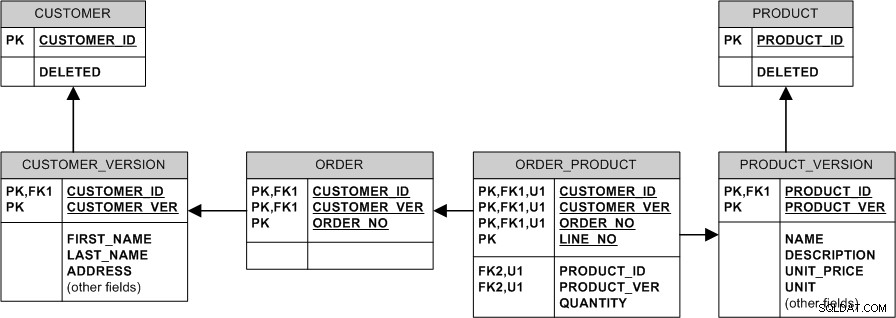
Il modello equivalente con relazioni non identificative e chiavi surrogate sarebbe simile al seguente: