Oggi i database che si estendono su più cloud sono abbastanza comuni. Promettono alta disponibilità e possibilità di implementare facilmente procedure di ripristino di emergenza. Sono anche un metodo per evitare il vendor lock-in:se si progetta il proprio ambiente di database in modo che possa operare su più provider cloud, molto probabilmente non si è vincolati a funzionalità e implementazioni specifiche di un particolare provider. Ciò semplifica l'aggiunta di un altro provider di infrastruttura al tuo ambiente, che si tratti di un altro cloud o di una configurazione in loco. Tale flessibilità è molto importante data la forte concorrenza tra i fornitori di servizi cloud e la migrazione dall'uno all'altro potrebbe essere abbastanza fattibile se fosse supportata da una riduzione delle spese.
L'estensione della tua infrastruttura su più datacenter (dello stesso provider o meno, non importa) comporta seri problemi da risolvere. Come si può progettare l'intera infrastruttura in modo che i dati siano al sicuro? Come affrontare le sfide che devi affrontare mentre lavori in un ambiente multi-cloud? In questo blog daremo un'occhiata a uno, ma probabilmente il più serio:il potenziale di un cervello diviso. Cosa significa? Analizziamo un po' cos'è lo split brain.
Cos'è il "cervello diviso"?
Il cervello diviso è una condizione in cui un ambiente composto da più nodi subisce il partizionamento della rete ed è stato suddiviso in più segmenti che non hanno contatti tra loro. Il caso più semplice sarà simile a questo:
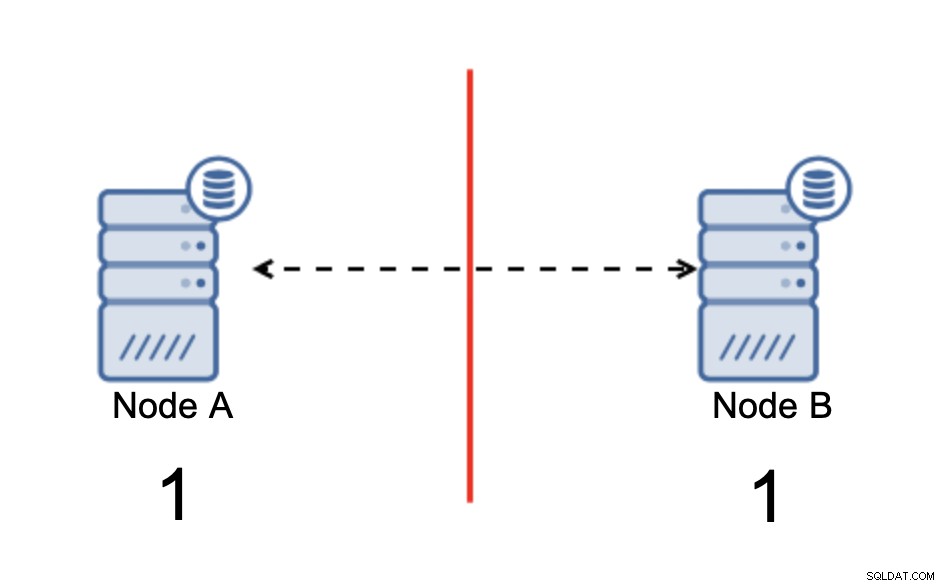
Abbiamo due nodi, A e B, collegati in rete tramite bi -replica asincrona direzionale. Quindi la connessione di rete viene interrotta tra quei nodi. Di conseguenza, entrambi i nodi non possono connettersi tra loro e qualsiasi modifica eseguita sul nodo A non può essere trasmessa al nodo B e viceversa. Entrambi i nodi, A e B, sono attivi e accettano connessioni, semplicemente non possono scambiare dati. Ciò può causare seri problemi poiché l'applicazione può apportare modifiche su entrambi i nodi aspettandosi di vedere lo stato completo del database mentre, in realtà, opera solo su uno stato di dati parzialmente noto. Di conseguenza, l'applicazione potrebbe intraprendere azioni errate, presentare risultati errati all'utente e così via. Pensiamo che sia chiaro che il cervello diviso è potenzialmente una condizione molto pericolosa e una delle priorità sarebbe affrontarlo in una certa misura. Cosa si può fare al riguardo?
Come evitare il cervello diviso
In breve, dipende. Il problema principale da affrontare è il fatto che i nodi sono attivi e funzionanti ma non hanno connettività tra di loro, quindi non sono a conoscenza dello stato dell'altro nodo. In generale, la replica asincrona di MySQL non ha alcun tipo di meccanismo che risolva internamente il problema dello split-brain. Puoi provare a implementare alcune soluzioni che ti aiutano a evitare lo split brain, ma hanno dei limiti o non risolvono ancora completamente il problema.
Quando ci allontaniamo dalla replica asincrona, le cose sembrano diverse. MySQL Group Replication e MySQL Galera Cluster sono tecnologie che traggono vantaggio dalla consapevolezza del cluster build-it. Entrambe queste soluzioni mantengono la comunicazione tra i nodi e assicurano che il cluster sia a conoscenza dello stato dei nodi. Implementano un meccanismo di quorum che determina se i cluster possono essere operativi o meno.
Discutiamo queste due soluzioni (replica asincrona e cluster basati su quorum) in modo più dettagliato.
Raggruppamento basato su quorum
Non discuteremo delle differenze di implementazione tra MySQL Galera Cluster e MySQL Group Replication, ci concentreremo sull'idea di base dietro l'approccio basato sul quorum e su come è progettato per risolvere il problema del split-brain nel tuo cluster.
La linea di fondo è che:il cluster, per funzionare, richiede che la maggior parte dei suoi nodi sia disponibile. Con questo requisito possiamo essere certi che la minoranza non potrà mai realmente influenzare il resto del cluster perché la minoranza non dovrebbe essere in grado di compiere alcuna azione. Ciò significa anche che, per poter gestire un errore di un nodo, un cluster deve avere almeno tre nodi. Se hai solo due nodi:
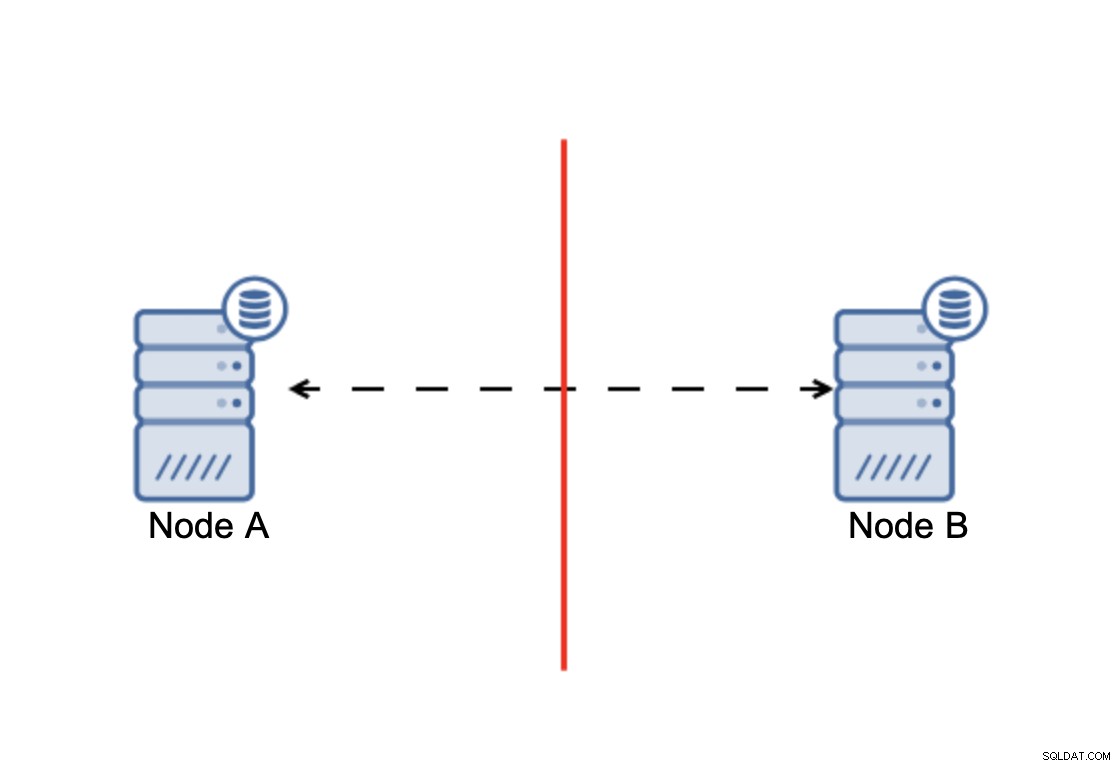
Quando c'è una divisione della rete, ti ritroverai con due parti del cluster, ciascuno costituito esattamente dal 50% dei nodi totali nel cluster. Nessuna di queste parti ha la maggioranza. Se hai tre nodi, però, le cose sono diverse:
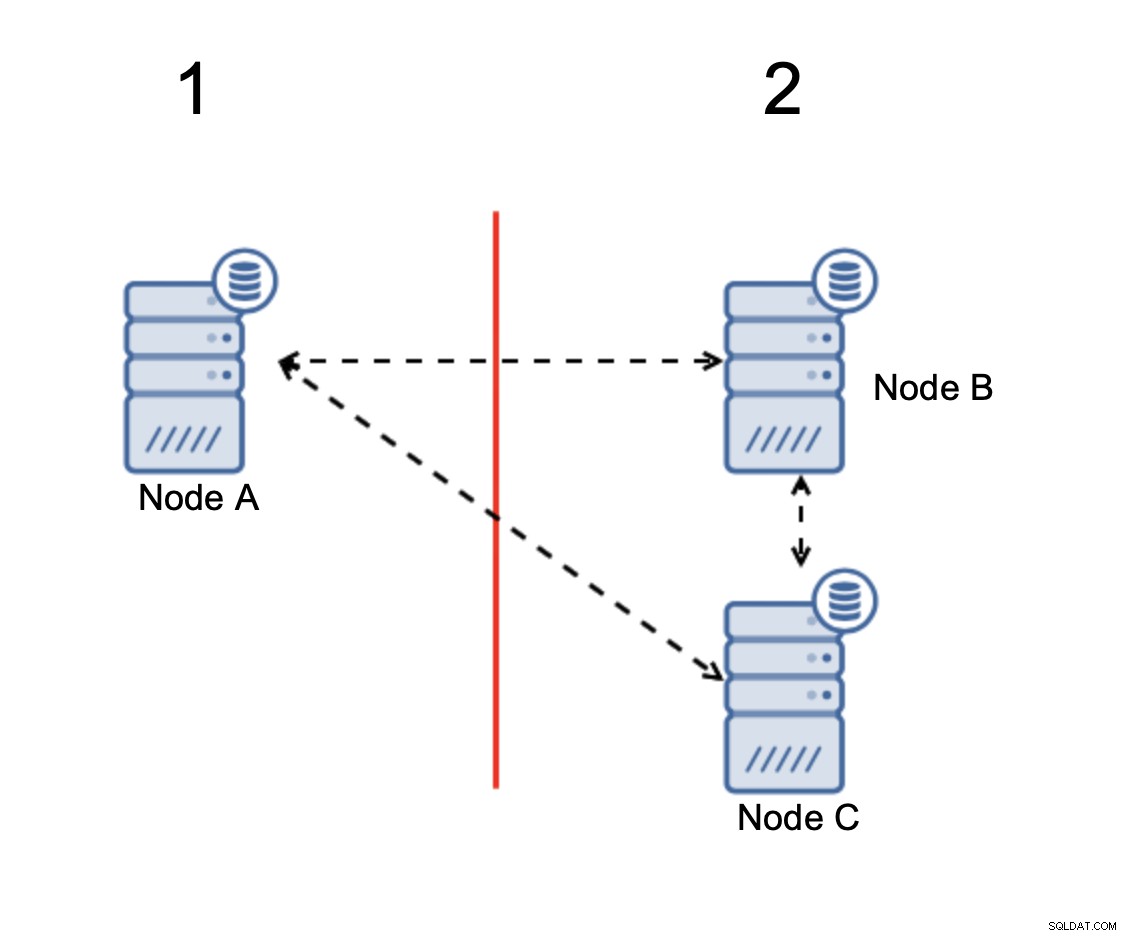
I nodi B e C hanno la maggioranza:quella parte è composta da due nodi fuori di tre così può continuare a funzionare. D'altra parte, il nodo A rappresenta solo il 33% dei nodi nel cluster, quindi non ha la maggioranza e cesserà di gestire il traffico per evitare lo split brain.
Con tale implementazione, è molto improbabile che accada lo split-brain (dovrebbe essere introdotto attraverso alcuni stati di rete strani e inaspettati, condizioni di gara o semplicemente bug nel codice di clustering. Anche se non impossibile da incontrare tali condizioni, l'utilizzo di una delle soluzioni basate sul quorum è l'opzione migliore per evitare il cervello diviso che esiste in questo momento.
Replica asincrona
Sebbene non sia la scelta ideale quando si tratta di affrontare il cervello diviso, la replica asincrona è ancora un'opzione praticabile. Ci sono diverse cose che dovresti considerare prima di implementare un database multi-cloud con replica asincrona.
Primo, failover. La replica asincrona viene fornita con un writer:solo il master deve essere scrivibile e gli altri nodi devono servire solo il traffico di sola lettura. La sfida è come affrontare il fallimento principale?
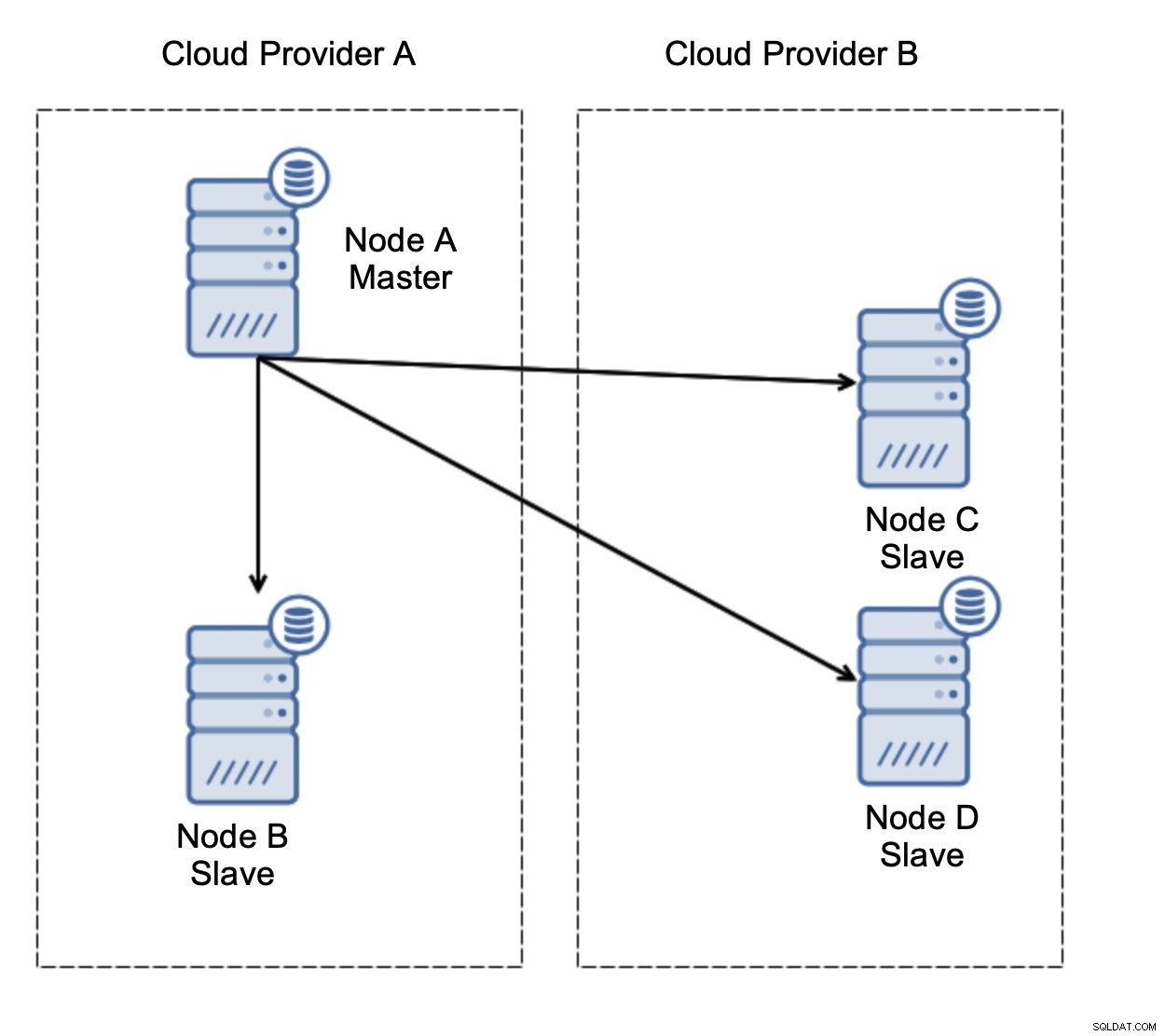
Consideriamo la configurazione come nel diagramma sopra. Abbiamo due provider cloud, due nodi ciascuno. Il provider A ospita anche il master. Cosa dovrebbe succedere se il master fallisce? Uno degli schiavi dovrebbe essere promosso per garantire che il database continui a essere operativo. Idealmente, dovrebbe essere un processo automatizzato per ridurre il tempo necessario per portare il database allo stato operativo. Cosa accadrebbe, però, se ci fosse un partizionamento di rete? Come dobbiamo verificare lo stato del cluster?
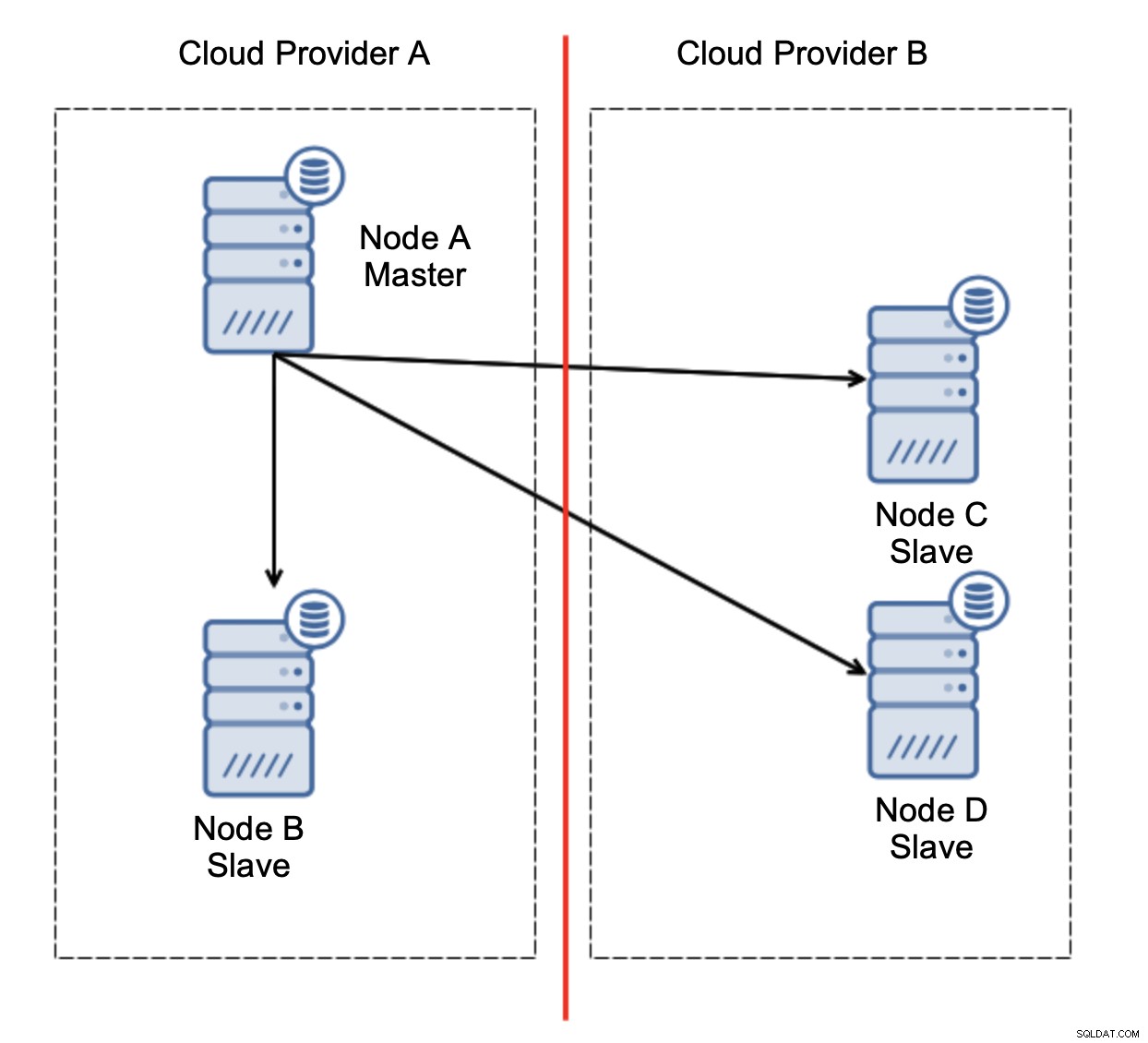
Ecco la sfida. La connettività di rete è persa tra due provider di servizi cloud. Dal punto di vista dei nodi C e D sia il nodo B che il master, il nodo A sono offline. Il nodo C o D dovrebbe essere promosso a master? Ma il vecchio master è ancora attivo:non si è bloccato, semplicemente non è raggiungibile tramite la rete. Se promuoviamo uno dei nodi situati presso il provider B, ci ritroveremo con due master scrivibili, due set di dati e un cervello diviso:
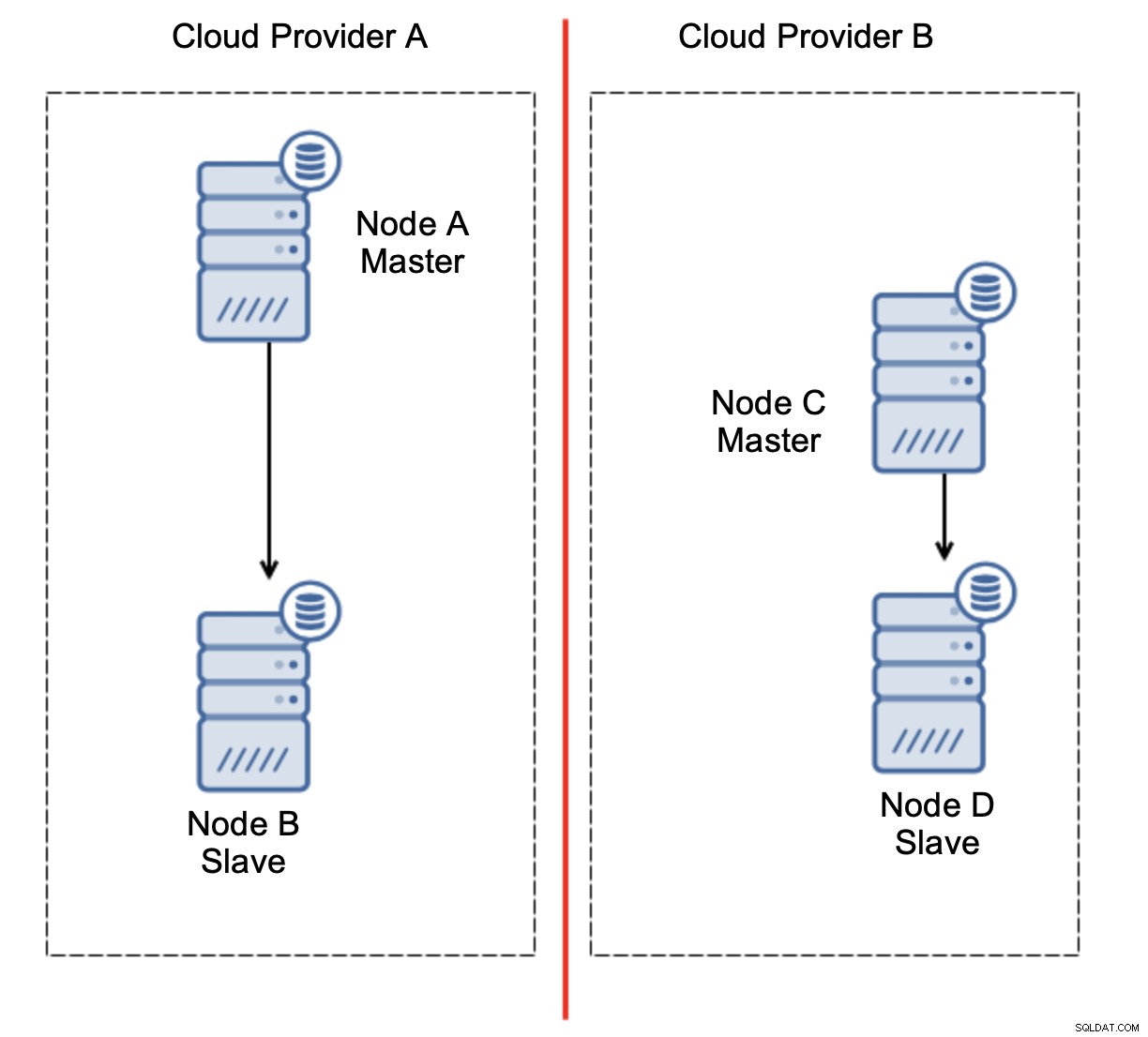
Questo non è sicuramente qualcosa che vogliamo. Ci sono un paio di opzioni qui. Innanzitutto, possiamo definire le regole di failover in modo che il failover possa avvenire solo in uno dei segmenti di rete, dove si trova il master. Nel nostro caso significherebbe che solo il nodo B potrebbe essere automaticamente promosso a master. In questo modo possiamo garantire che il failover automatico avvenga se il nodo A è inattivo, ma non verrà eseguita alcuna azione se è presente un partizionamento di rete. Alcuni degli strumenti che possono aiutarti a gestire i failover automatici (come ClusterControl) supportano whitelist e blacklist, consentendo agli utenti di definire quali nodi possono essere considerati candidati per il failover e quali non dovrebbero mai essere usati come master.
Un'altra opzione sarebbe quella di implementare una sorta di soluzione di "consapevolezza della topologia". Ad esempio, si potrebbe provare a controllare lo stato principale utilizzando servizi esterni come i bilanciatori di carico.
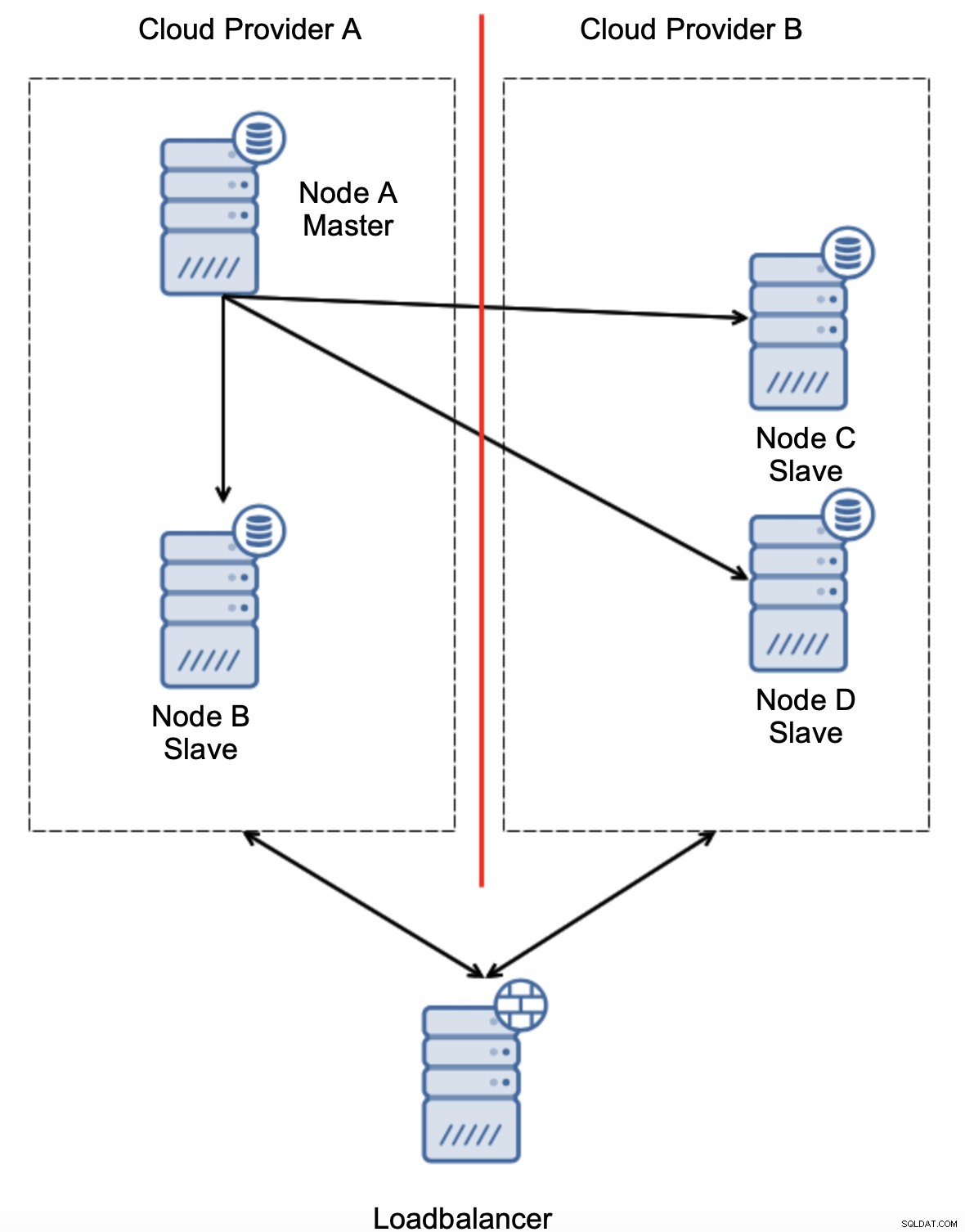
Se l'automazione del failover potesse verificare lo stato della topologia come visto dal load balancer, potrebbe essere che il load balancer, situato in una terza posizione, possa effettivamente raggiungere entrambi i data center e chiarire che i nodi nel provider cloud A non sono inattivi, semplicemente non possono essere raggiunti dal provider cloud B. Tale un ulteriore livello di controlli è implementato in ClusterControl.
Infine, qualunque sia lo strumento che utilizzi per implementare il failover automatizzato, può anche essere progettato in modo da tenere conto del quorum. Quindi, con tre nodi in tre posizioni, puoi facilmente dire quale parte dell'infrastruttura dovrebbe essere mantenuta in vita e quale no.
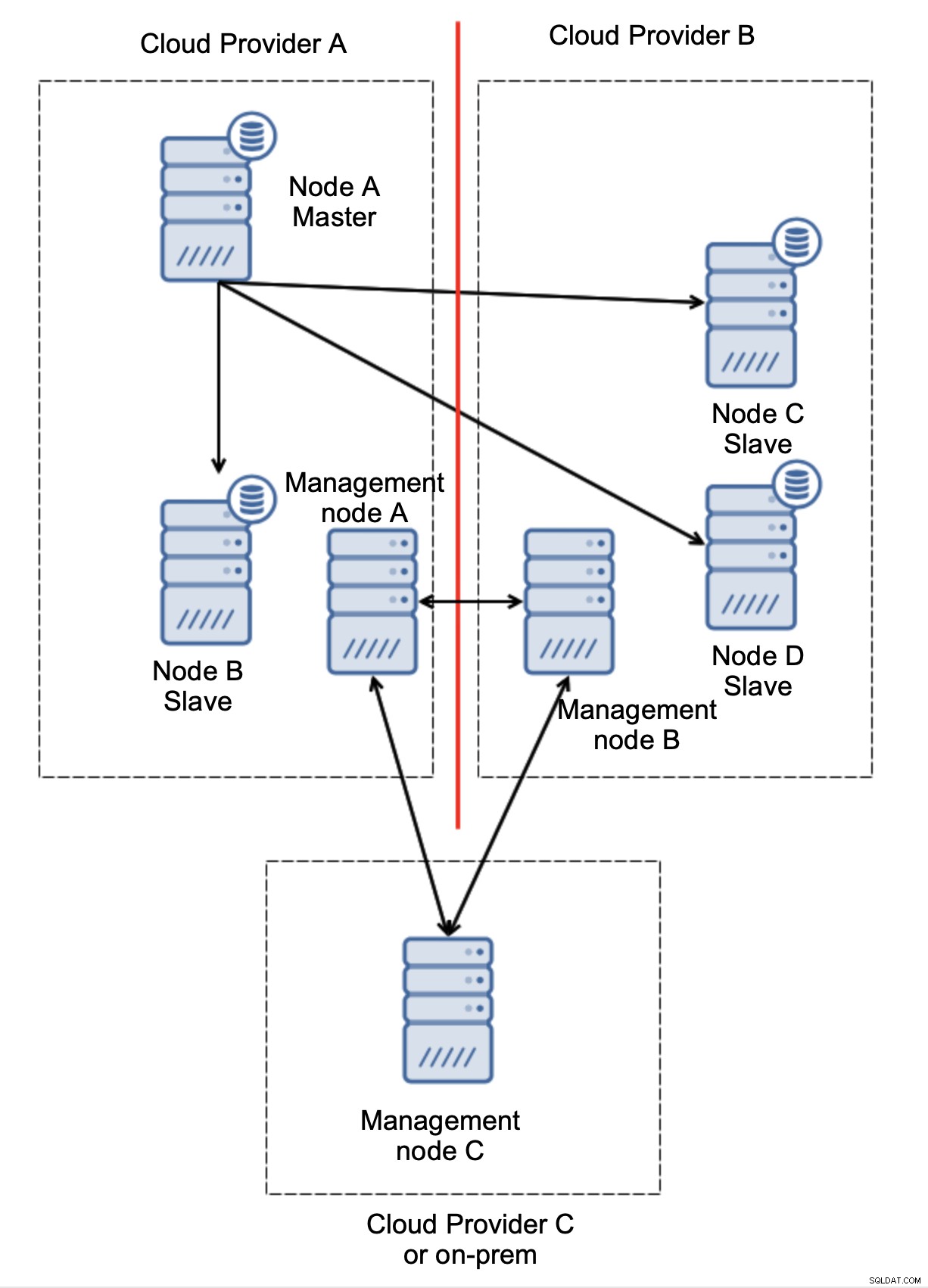
Qui possiamo vedere chiaramente che il problema è legato solo alla connettività tra i provider A e B. Il nodo di gestione C fungerà da inoltro e, di conseguenza, non dovrebbe essere avviato alcun failover. D'altra parte, se un datacenter è completamente tagliato fuori:

È anche abbastanza chiaro cosa sia successo. Il nodo di gestione A segnalerà che non può raggiungere la maggior parte del cluster mentre i nodi di gestione B e C formeranno la maggioranza. È possibile basarsi su questo e, ad esempio, scrivere script che gestiranno la topologia in base allo stato del nodo di gestione. Ciò potrebbe significare che gli script eseguiti nel provider di servizi cloud A rileverebbero che il nodo di gestione A non costituisce la maggioranza e arresteranno tutti i nodi del database per garantire che non si verifichino scritture nel provider di servizi cloud partizionato.
ClusterControl, quando distribuito in modalità High Availability può essere trattato come i nodi di gestione che abbiamo usato nei nostri esempi. Tre nodi ClusterControl, oltre al protocollo RAFT, possono aiutarti a determinare se un determinato segmento di rete è partizionato o meno.
Conclusione
Ci auguriamo che questo post del blog ti dia un'idea degli scenari a cervelli separati che potrebbero verificarsi per le implementazioni di MySQL su più piattaforme cloud.