L'uso del cluster Galera è un ottimo modo per creare un ambiente a disponibilità elevata per MySQL o MariaDB. È un ambiente cluster senza condivisione che può essere ridimensionato anche oltre 12-15 nodi. Galera ha alcune limitazioni, però. Brilla in ambienti a bassa latenza e anche se può essere utilizzato su WAN, le prestazioni sono limitate dalla latenza di rete. Le prestazioni di Galera possono anche essere influenzate se uno dei nodi inizia a comportarsi in modo errato. Ad esempio, un carico eccessivo su uno dei nodi può rallentarlo, determinando una gestione più lenta delle scritture e che avrà un impatto su tutti gli altri nodi del cluster. D'altra parte, è del tutto impossibile gestire un'attività senza analizzare i dati. Tale analisi, in genere, richiede l'esecuzione di query pesanti, che è abbastanza diversa da un carico di lavoro OLTP. In questo post del blog, discuteremo di un modo semplice per eseguire query analitiche per i dati archiviati in Galera Cluster per MySQL o MariaDB, in modo che non influisca sulle prestazioni del cluster principale.
Come eseguire query analitiche su Galera Cluster?
Come abbiamo affermato, eseguire query di lunga durata direttamente su un cluster Galera è fattibile, ma forse non è una buona idea. Dipendente dall'hardware, questa può essere una soluzione accettabile (se si utilizza un hardware potente e non si esegue un carico di lavoro analitico multi-thread), ma anche se l'utilizzo della CPU non sarà un problema, il fatto che uno dei nodi avrà un carico di lavoro misto ( OLTP e OLAP) porranno da sole alcune sfide in termini di prestazioni. Le query OLAP elimineranno i dati necessari per il carico di lavoro OLTP dal pool di buffer e ciò rallenterà le query OLTP. Fortunatamente, esiste un modo semplice ma efficiente per separare il carico di lavoro analitico dalle query regolari:uno slave di replica asincrono.
Lo slave di replica è una soluzione molto semplice:tutto ciò di cui hai bisogno è solo un altro host di cui è possibile eseguire il provisioning e la replica asincrona deve essere configurata da Galera Cluster a quel nodo. Con la replica asincrona, lo slave non influirà in alcun modo sul resto del cluster. Non importa se è caricato pesantemente, utilizza hardware diverso (meno potente), continuerà semplicemente a replicarsi dal cluster principale. Lo scenario peggiore è che lo slave di replica inizi a rimanere indietro, ma poi spetta a te implementare la replica multi-thread o, eventualmente, aumentare la scalabilità dello slave di replica.
Una volta che lo slave di replica è attivo e funzionante, dovresti eseguire le query più pesanti su di esso e scaricare il cluster Galera. Questo può essere fatto in diversi modi, a seconda della configurazione e dell'ambiente. Se si utilizza ProxySQL, è possibile indirizzare facilmente le query allo slave analitico in base all'host di origine, all'utente, allo schema o persino alla query stessa. In caso contrario, spetterà alla tua applicazione inviare query analitiche all'host corretto.
Configurare uno slave di replica non è molto complesso, ma può comunque essere complicato se non si è esperti con MySQL e strumenti come xtrabackup. L'intero processo consisterebbe nella creazione del repository su un nuovo server e nell'installazione del database MySQL. Quindi dovrai eseguire il provisioning di quell'host utilizzando i dati del cluster Galera. Puoi usare xtrabackup per questo, ma anche altri strumenti come mydumper/myloader o anche mysqldump funzioneranno (purché tu li esegua correttamente). Una volta che i dati sono lì, dovrai impostare la replica tra un nodo Galera master e lo slave di replica. Infine, dovresti riconfigurare il tuo livello proxy per includere il nuovo slave e indirizzare il traffico verso di esso o apportare modifiche al modo in cui la tua applicazione si connette al database per reindirizzare parte del carico allo slave di replica.
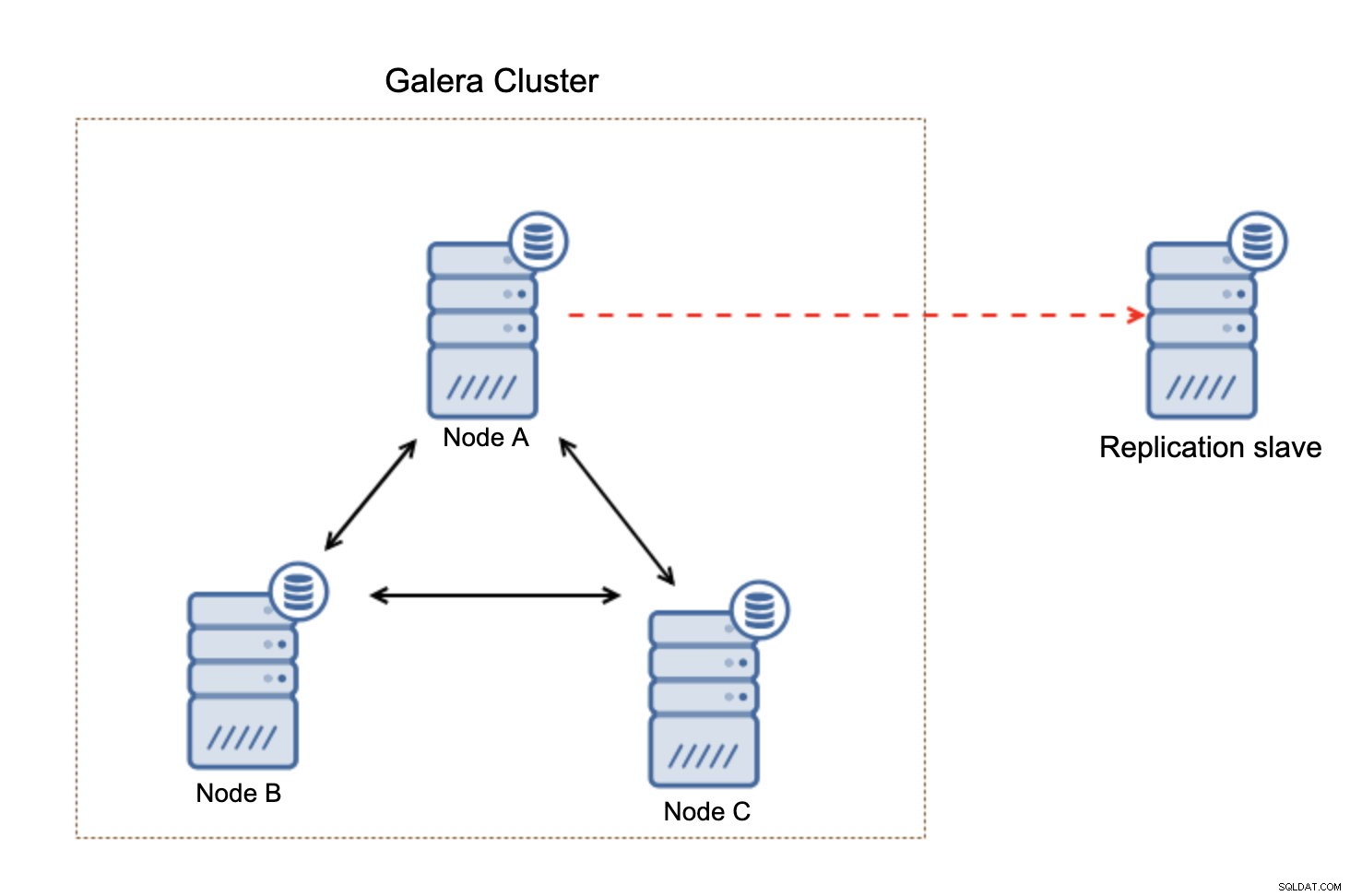
Ciò che è importante tenere a mente, questa configurazione non è resiliente. Se il nodo Galera "master" si interrompe, il collegamento di replica verrà interrotto e sarà necessaria un'azione manuale per asservire la replica a un altro nodo master nel cluster Galera.
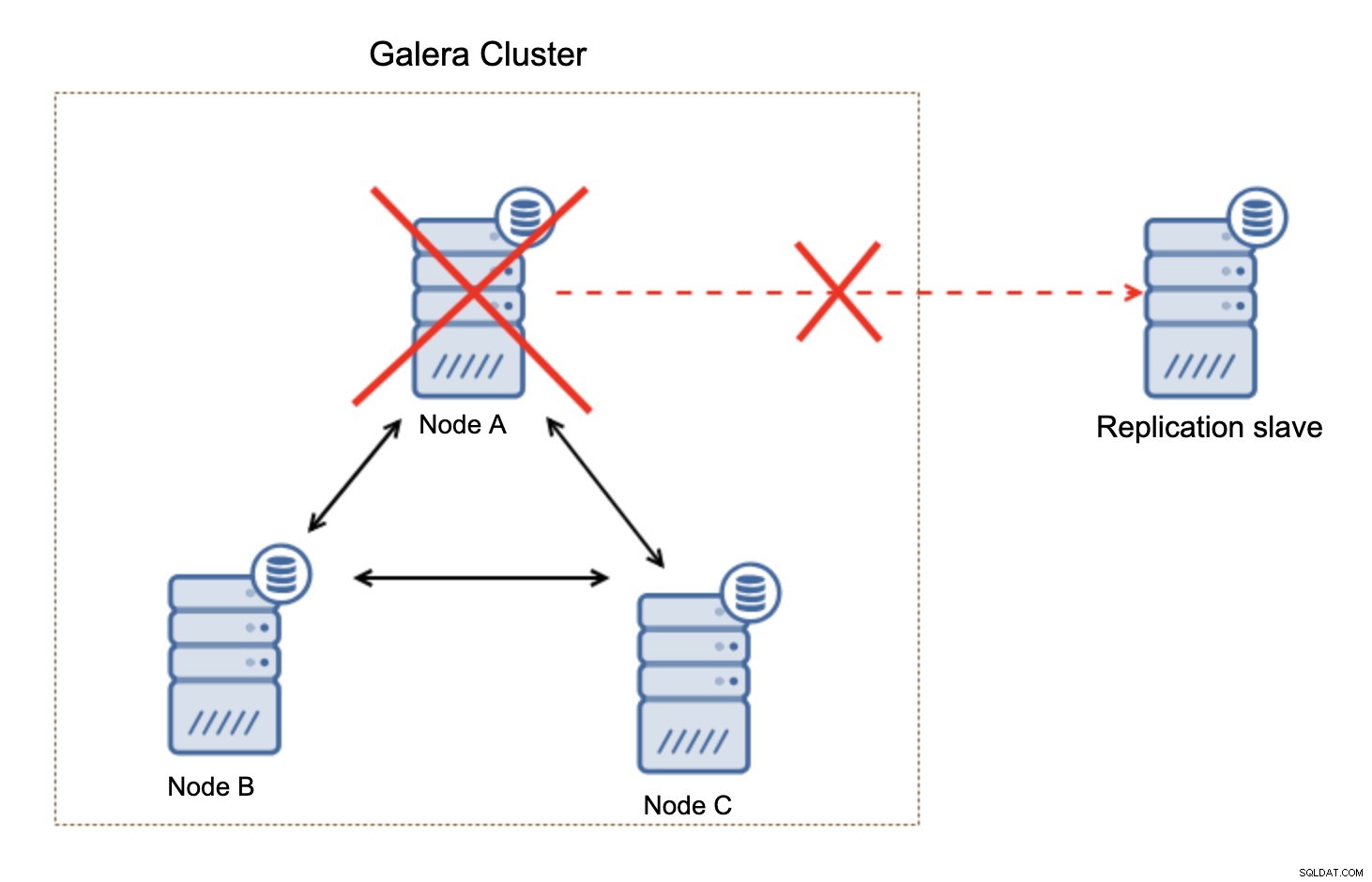
Questo non è un grosso problema, soprattutto se utilizzi la replica con GTID (Global Transaction ID), ma devi identificare che la replica è interrotta e quindi intraprendere l'azione manuale.
Come configurare lo slave asincrono su Galera Cluster utilizzando ClusterControl?
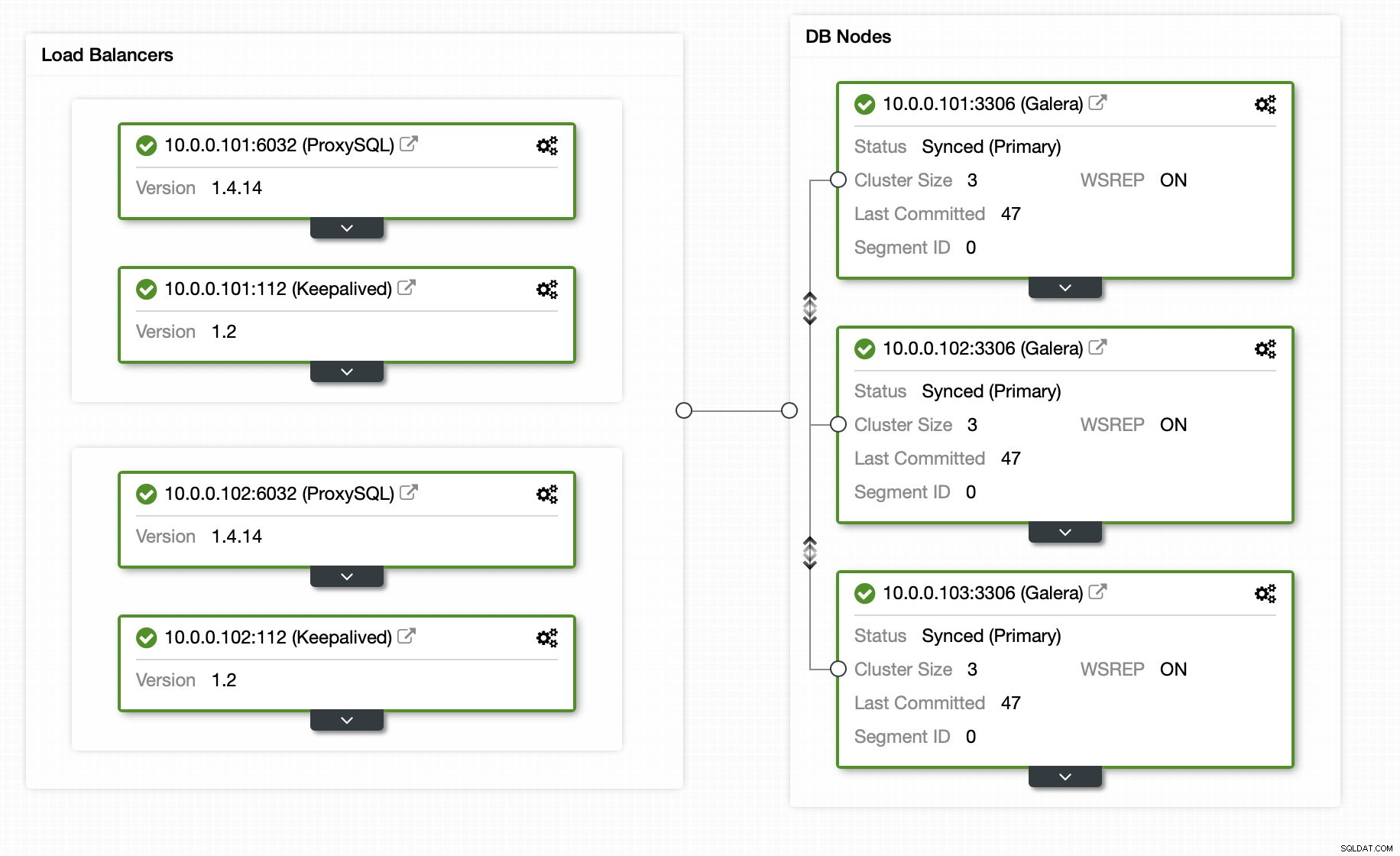
Fortunatamente, se utilizzi ClusterControl, l'intero processo può essere automatizzato e richiede solo una manciata di clic. Lo stato iniziale è già stato impostato utilizzando ClusterControl:un cluster Galera a 3 nodi con 2 nodi ProxySQL e 2 nodi Keepalived per un'elevata disponibilità sia del database che del livello proxy.
L'aggiunta dello slave di replica è a portata di clic:
La replica, ovviamente, richiede l'abilitazione dei log binari. Se non hai binlog abilitati sui tuoi nodi Galera, puoi farlo anche da ClusterControl. Tieni presente che l'abilitazione dei log binari richiederà il riavvio del nodo per applicare le modifiche alla configurazione.
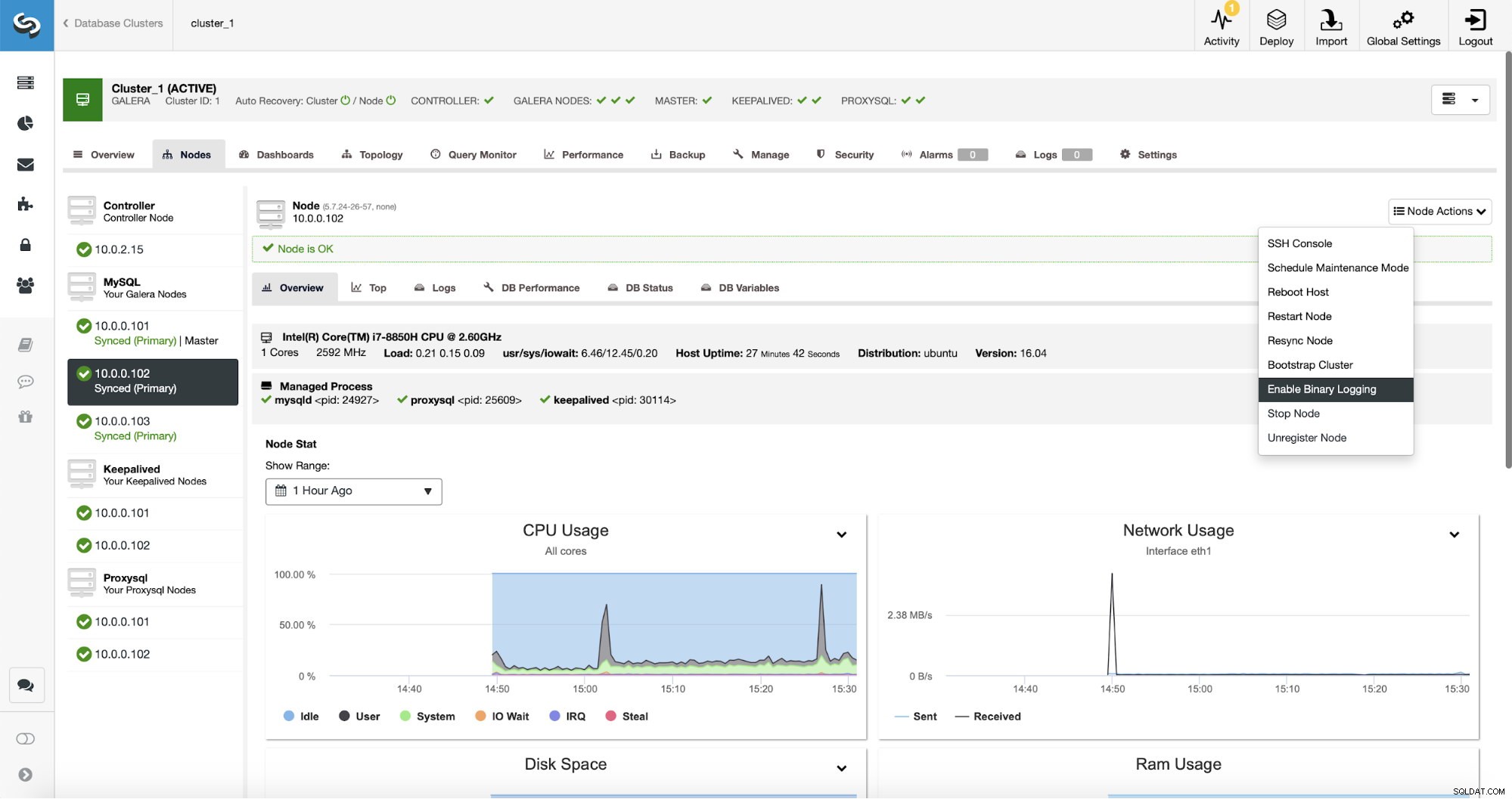
Anche se un nodo nel cluster ha i log binari abilitati (contrassegnati come "Master" nella schermata sopra), è comunque opportuno abilitare il log binario su almeno un altro nodo. ClusterControl può eseguire automaticamente il failover dello slave di replica dopo aver rilevato che il nodo Galera master si è arrestato in modo anomalo, ma per questo è necessario un altro nodo master con log binari abilitati o non avrà nulla su cui eseguire il failover.
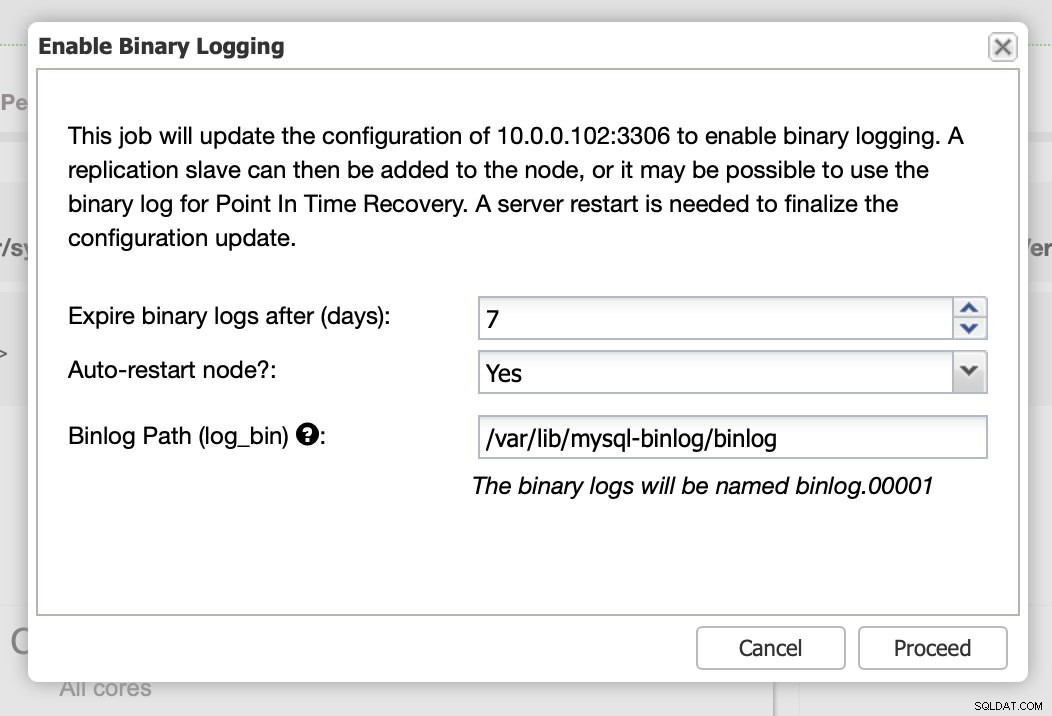
Come abbiamo affermato, l'abilitazione dei log binari richiede il riavvio. Puoi eseguirlo immediatamente o semplicemente apportare le modifiche alla configurazione ed eseguire il riavvio in un altro momento.
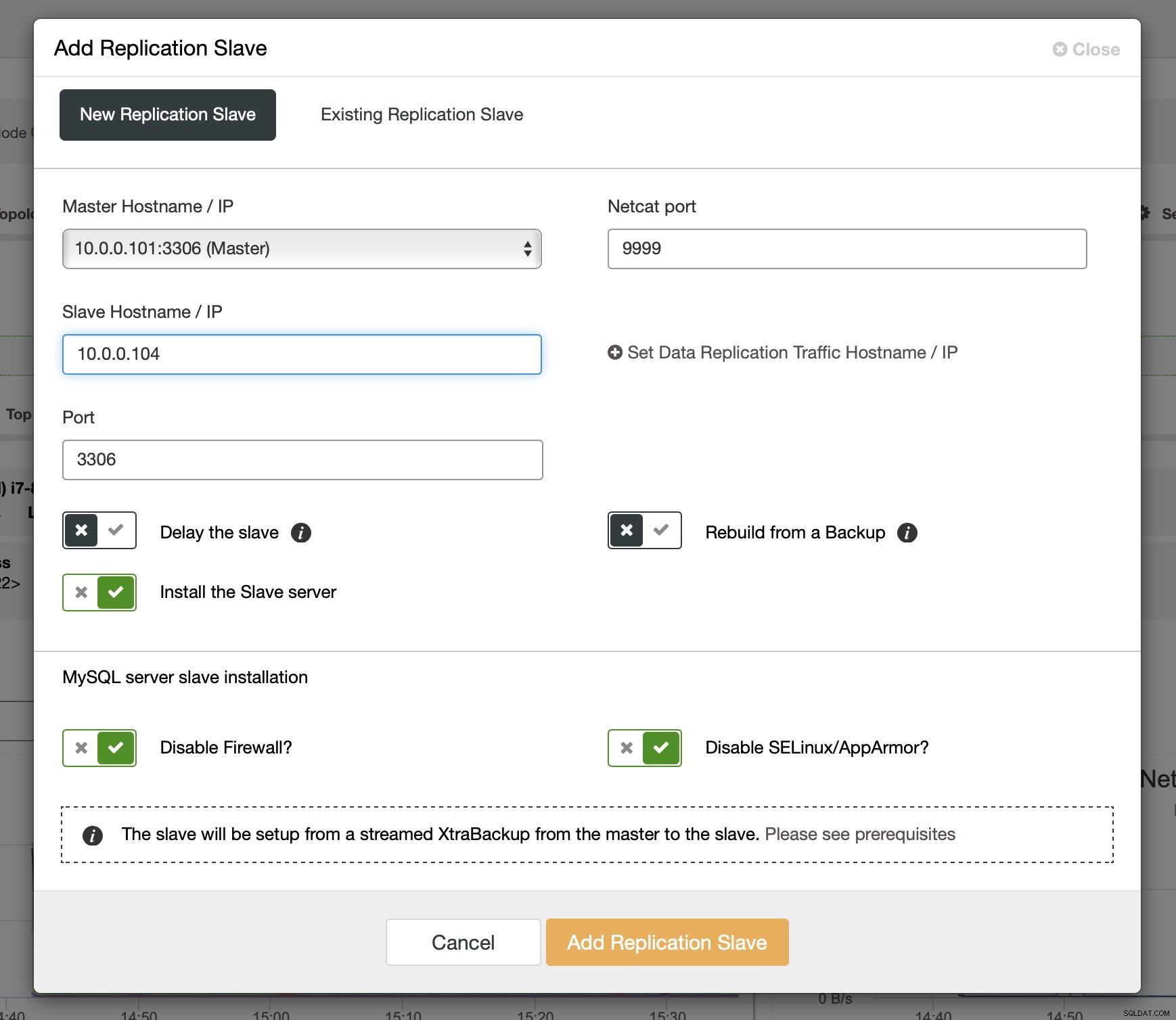
Dopo che i binlog sono stati abilitati su alcuni nodi Galera, puoi procedere con l'aggiunta dello slave di replica. Nella finestra di dialogo devi selezionare l'host master, passare il nome host o l'indirizzo IP dello slave. Se hai backup recenti a portata di mano (cosa che dovresti fare), puoi usarne uno per eseguire il provisioning dello slave. In caso contrario, ClusterControl eseguirà il provisioning utilizzando xtrabackup:tutti i dati master recenti verranno trasmessi allo slave e quindi verrà configurata la replica.
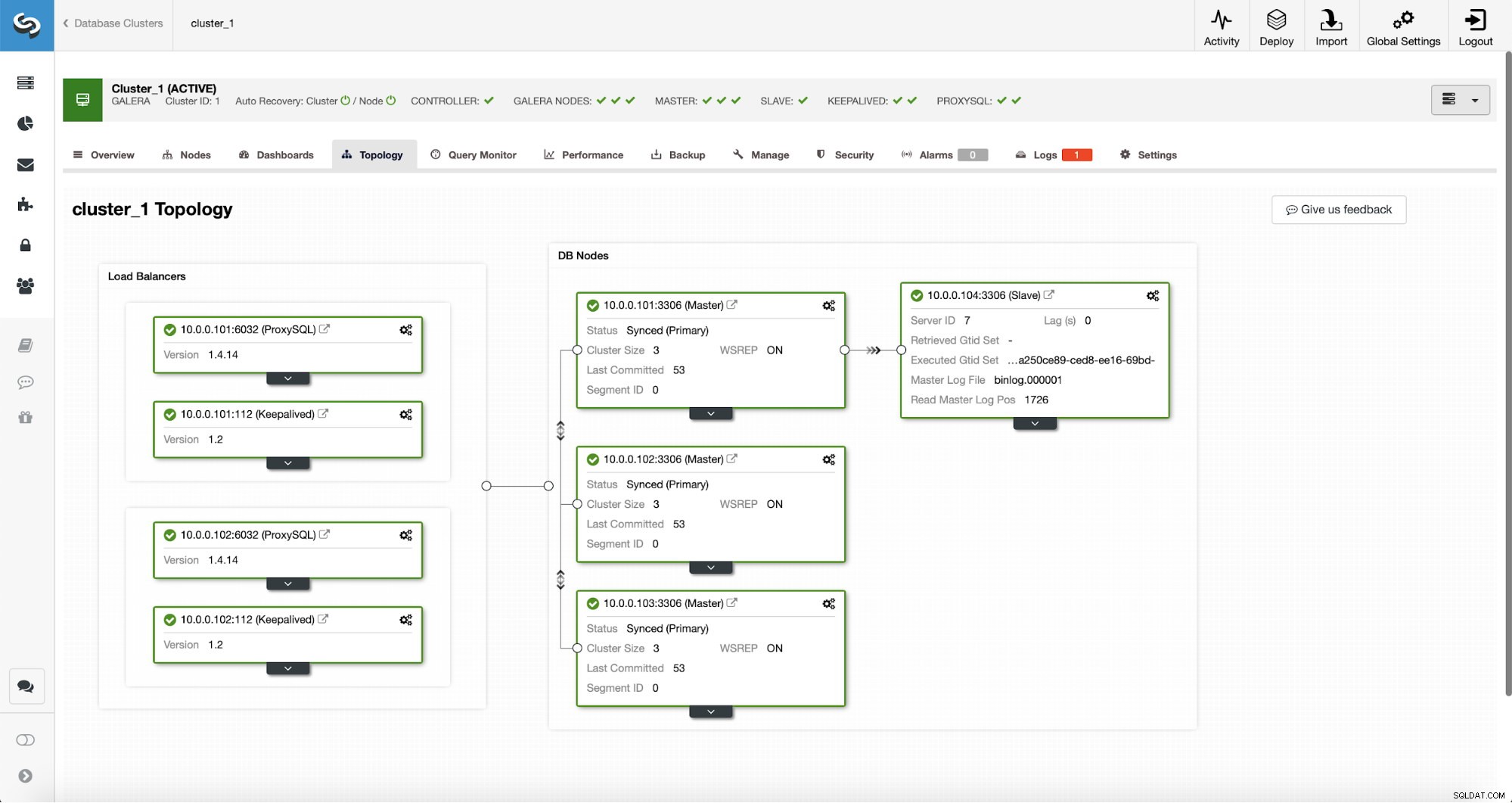
Dopo il completamento del lavoro, uno slave di replica è stato aggiunto al cluster. Come affermato in precedenza, se il 10.0.0.101 dovesse morire, un altro host nel cluster Galera verrà scelto come master e ClusterControl eseguirà automaticamente lo slave 10.0.0.104 di un altro nodo.
Poiché utilizziamo ProxySQL, dobbiamo configurarlo. Aggiungeremo un nuovo server in ProxySQL.
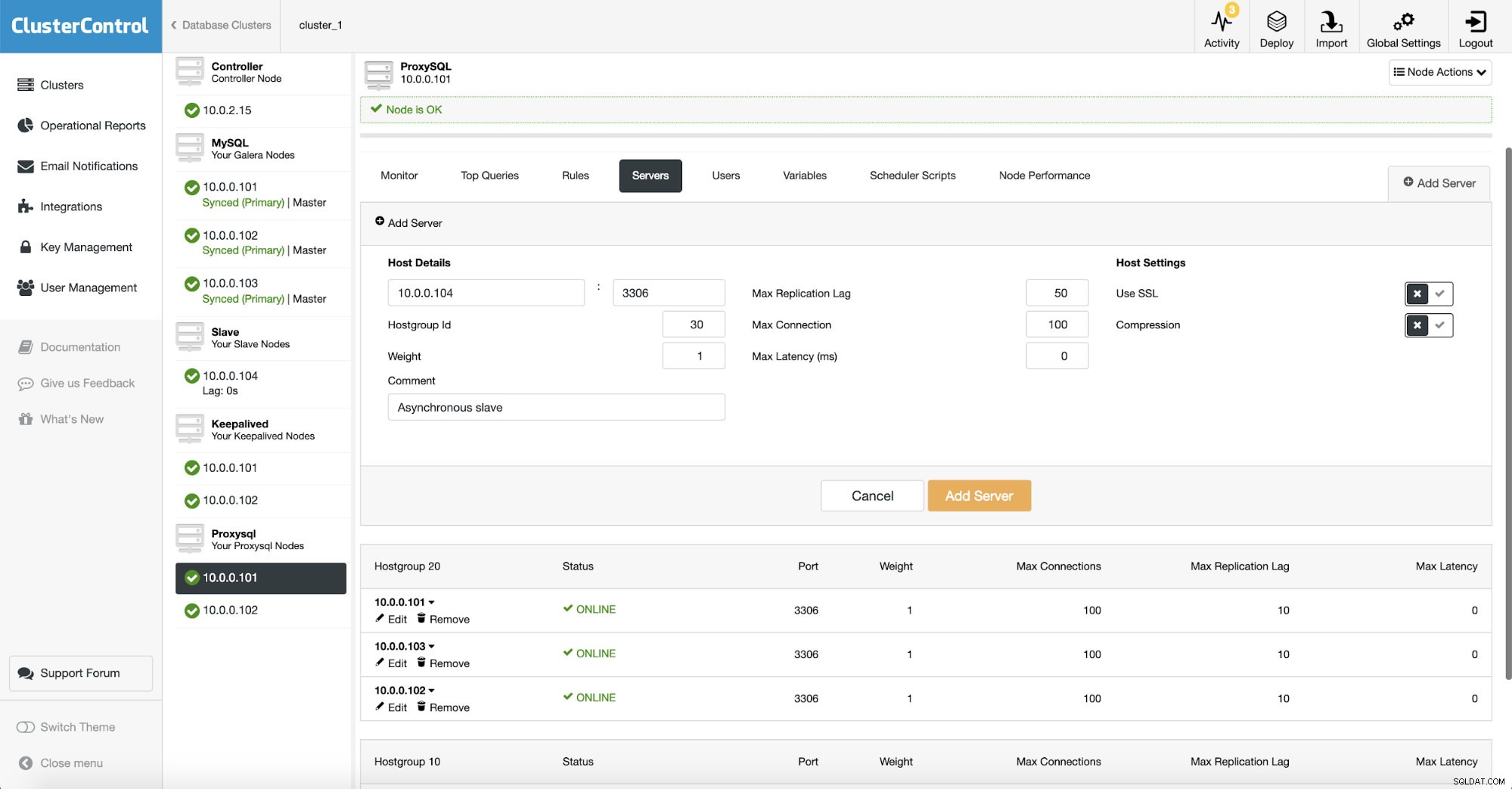
Abbiamo creato un altro hostgroup (30) dove mettiamo il nostro slave asincrono. Abbiamo anche aumentato "Max Replication Lag" a 50 secondi dal valore predefinito 10. Dipende dai requisiti aziendali quanto gravemente lo slave di analisi possa essere in ritardo prima che diventi un problema.
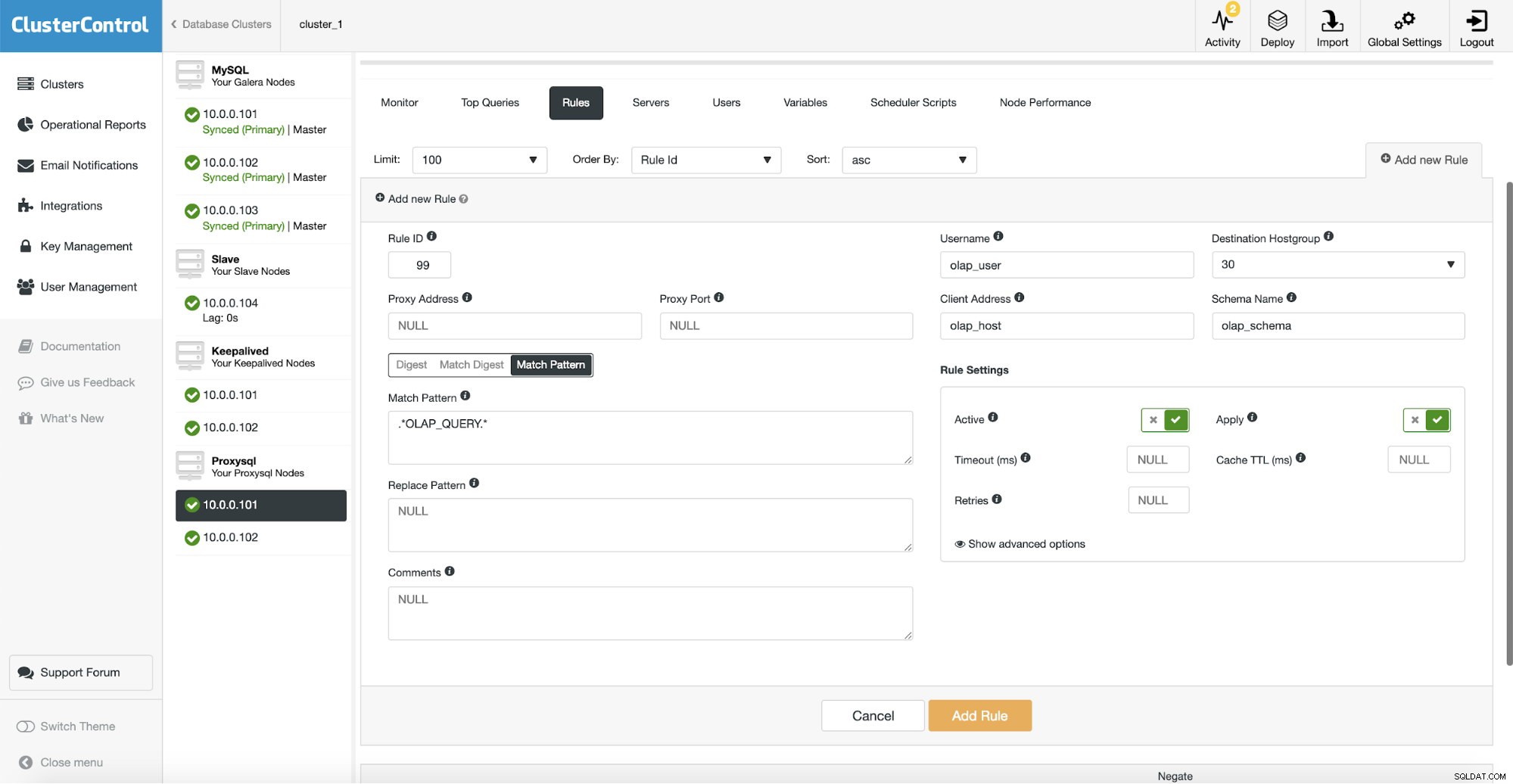
Dopodiché dobbiamo configurare una regola di query che corrisponda al nostro traffico OLAP e lo instrada al gruppo host OLAP (30). Nello screenshot sopra abbiamo riempito diversi campi:questo non è obbligatorio. In genere dovrai usarne uno, due al massimo. Lo screenshot sopra serve come esempio, così possiamo facilmente vedere che puoi abbinare le query usando schema (se hai uno schema separato con dati analitici), nome host/IP (se le query OLAP vengono eseguite da un host particolare), utente (se l'applicazione utilizza utente specifico per query analitiche. Puoi anche abbinare le query direttamente passando una query completa o contrassegnandole con commenti SQL e lasciare che ProxySQL instrada tutte le query con una stringa "OLAP_QUERY" al nostro gruppo host analitico.
Come puoi vedere, grazie a ClusterControl siamo stati in grado di implementare uno slave di replica su Galera Cluster in un paio di clic. Alcuni potrebbero obiettare che MySQL non è il database più adatto per il carico di lavoro analitico e tendiamo ad essere d'accordo. È possibile estendere facilmente questa configurazione utilizzando ClickHouse e impostando una replica da slave asincrono al datastore colonnare ClickHouse per prestazioni molto migliori delle query analitiche. Abbiamo descritto questa configurazione in uno dei post precedenti del blog.



