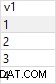
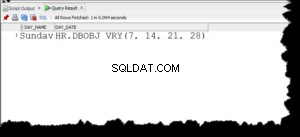
Questa query, utilizzando l'analitica lead() fa il lavoro. Colonna note mostra se la riga proviene dai tuoi dati o se manca uno spazio vuoto:
select id, d1, d2, case dir when 3 then 'GAP' end note
from (
select id,
case when dir = 2
and lead(dir) over (partition by id order by dt) = 1
and lead(dt) over (partition by id order by dt) <> dt + 1
then dt + 1
else dt
end d1,
case when dir = 2
and lead(dir) over (partition by id order by dt) = 1
and lead(dt) over (partition by id order by dt) <> dt + 1
then 3
else dir
end dir,
case when lead(dir) over (partition by id order by dt) = 1
then lead(dt) over (partition by id order by dt) - 1
else lead(dt) over (partition by id order by dt)
end d2
from (
select * from a unpivot (dt for dir in (validfrom as 1, validto as 2)) union
select * from b unpivot (dt for dir in (validfrom as 1, validto as 2)) ) )
where dir in (1, 3)
All'inizio i dati non sono pivot solo per avere tutte le date in una colonna, è più facile per ulteriori analisi. L'unione rimuove i valori duplicati. Colonna dir informa se questo è from o to Data. Quindi lead viene applicata la logica, a seconda del tipo di questa direzione. Penso che possa essere un po' semplificato :)