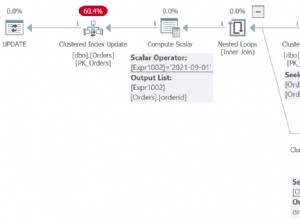
Non sono proprio sicuro di quale sia la tua domanda. Sì, secondo questi due piani di esecuzione, in questo caso, il metodo subquery ha un costo previsto inferiore. Non sembra troppo sorprendente, poiché può utilizzare l'indice per individuare molto rapidamente la riga esatta che ti interessa. Nello specifico, in questo caso, la sottoquery deve solo eseguire una scansione molto rapida dell'indice PK. La situazione potrebbe essere diversa se la sottoquery coinvolgesse colonne che non facevano parte dell'indice.
La query che utilizza rank() deve ottenere tutte le righe corrispondenti e classificarle. Non credo che l'ottimizzatore abbia una logica di cortocircuito per riconoscere che questa è una query top-n e quindi evitare un ordinamento completo, anche se tutto ciò che ti interessa davvero è la riga più alta.
Potresti anche provare questo modulo, che l'ottimizzatore dovrebbe riconoscere come una query top-n. Mi aspetto nel tuo caso che richieda solo una scansione di un singolo intervallo sull'indice seguita da un accesso alla tabella.
select *
from (select *
from teste_rank r
where data_mov <= trunc(sysdate)
and codigo = 1
order by data_mov desc)
where rownum=1;