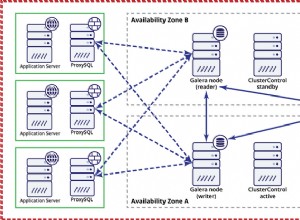
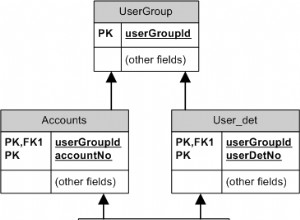
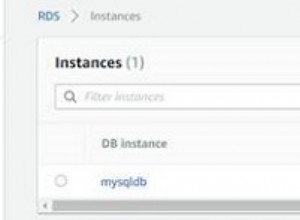
Ci sono probabilmente ragioni per non utilizzare le funzioni analitiche, ma utilizzare le funzioni analitiche da sole :
select am, rf, rfm, rownum_rf2, rownum_rfm
from
(
-- the 3nd level takes the subproduct ranks, and for each equally ranked
-- subproduct, it produces the product ranking
select am, rf, rfm, rownum_rfm,
row_number() over (partition by rownum_rfm order by rownum_rf) rownum_rf2
from
(
-- the 2nd level ranks (without ties) the products within
-- categories, and subproducts within products simultaneosly
select am, rf, rfm,
row_number() over (partition by am order by count_rf desc) rownum_rf,
row_number() over (partition by am, rf order by count_rfm desc) rownum_rfm
from
(
-- inner most query counts the records by subproduct
-- using regular group-by. at the same time, it uses
-- the analytical sum() over to get the counts by product
select tg.am, ttc.rf, ttc.rfm,
count(*) count_rfm,
sum(count(*)) over (partition by tg.am, ttc.rf) count_rf
from tg inner join ttc on tg.value = ttc.value
group by tg.am, ttc.rf, ttc.rfm
) X
) Y
-- at level 3, we drop all but the top 5 subproducts per product
where rownum_rfm <= 5 -- top 5 subproducts
) Z
-- the filter on the final query retains only the top 10 products
where rownum_rf2 <= 10 -- top 10 products
order by am, rownum_rf2, rownum_rfm;
Ho usato rownum invece di rank in modo da non ottenere mai pareggi, o in altre parole, i pareggi verranno decisi casualmente. Anche questo non funziona se i dati non sono sufficientemente densi (meno di 5 sottoprodotti in uno dei primi 10 prodotti - potrebbero invece mostrare sottoprodotti di altri prodotti). Ma se i dati sono densi (database consolidato di grandi dimensioni), la query dovrebbe funzionare correttamente.
Quanto segue effettua due passaggi dei dati, ma restituisce risultati corretti in ogni caso. Anche in questo caso, questa è una query di rango senza legami.
select am, rf, rfm, count_rf, count_rfm, rownum_rf, rownum_rfm
from
(
-- next join the top 10 products to the data again to get
-- the subproduct counts
select tg.am, tg.rf, ttc.rfm, tg.count_rf, tg.rownum_rf, count(*) count_rfm,
ROW_NUMBER() over (partition by tg.am, tg.rf order by 1 desc) rownum_rfm
from (
-- first rank all the products
select tg.am, tg.value, ttc.rf, count(*) count_rf,
ROW_NUMBER() over (order by 1 desc) rownum_rf
from tg
inner join ttc on tg.value = ttc.value
group by tg.am, tg.value, ttc.rf
order by count_rf desc
) tg
inner join ttc on tg.value = ttc.value and tg.rf = ttc.rf
-- filter the inner query for the top 10 products only
where rownum_rf <= 10
group by tg.am, tg.rf, ttc.rfm, tg.count_rf, tg.rownum_rf
) X
-- filter where the subproduct rank is in top 5
where rownum_rfm <= 5
order by am, rownum_rf, rownum_rfm;
colonne:
count_rf : count of sales by product
count_rfm : count of sales by subproduct
rownum_rf : product rank within category (rownumber - without ties)
rownum_rfm : subproduct rank within product (without ties)