Se stai utilizzando SQLcl per eseguire query su Oracle Database, puoi utilizzare SPOOL comando per esportare i risultati della query in un file CSV.
Esempio
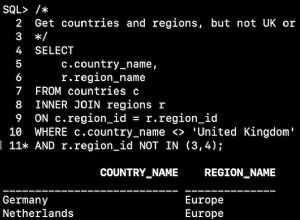
Ecco un esempio che esporta un'intera tabella:
SET SQLFORMAT csv
SPOOL '/Users/barney/data/countries.csv';
SELECT * FROM countries;
SPOOL off;
SET SQLFORMAT ansiconsoleEcco cosa ha fatto, riga per riga:
- La mia prima riga imposta
SQLFORMATacsv. Ciò garantisce che l'output sia effettivamente separato da virgole. Se non lo facessi, potrei finire con un file con un.csvestensione, ma con contenuti non separati da virgole. - La seconda riga è dove usiamo il
SPOOLcomando per specificare dove verrà scritto il file di output. Assicurati di modificare il/Users/barney/data/countries.csvparte in una posizione sul tuo sistema. - Sulla terza riga, ho eseguito la query SQL, i risultati per i quali sto esportando. In questo caso, ho esportato tutti i
countriestabella. - Successivamente ho girato
SPOOLspento. - Infine, ho finito impostando
SQLFORMATtorna aansiconsole(che era quello che stavo usando prima di impostarlo sucsv).
Ecco come appare il file risultante:
"COUNTRY_ID","COUNTRY_NAME","REGION_ID" "AR","Argentina",2 "AU","Australia",3 "BE","Belgium",1 "BR","Brazil",2 "CA","Canada",2 "CH","Switzerland",1 "CN","China",3 "DE","Germany",1 "DK","Denmark",1 "EG","Egypt",4 "FR","France",1 "HK","HongKong",3 "IL","Israel",4 "IN","India",3 "IT","Italy",1 "JP","Japan",3 "KW","Kuwait",4 "MX","Mexico",2 "NG","Nigeria",4 "NL","Netherlands",1 "SG","Singapore",3 "UK","United Kingdom",1 "US","United States of America",2 "ZM","Zambia",4 "ZW","Zimbabwe",4 25 rows selected.
Rimuovi le intestazioni delle colonne
Puoi rimuovere le intestazioni di colonna con SET HEADING off :
SET SQLFORMAT csv
SET HEADING off
SPOOL '/Users/barney/data/countries.csv';
SELECT * FROM countries;
SPOOL off;
SET SQLFORMAT ansiconsole
SET HEADING onRisultato:
"AR","Argentina",2 "AU","Australia",3 "BE","Belgium",1 "BR","Brazil",2 "CA","Canada",2 "CH","Switzerland",1 "CN","China",3 "DE","Germany",1 "DK","Denmark",1 "EG","Egypt",4 "FR","France",1 "HK","HongKong",3 "IL","Israel",4 "IN","India",3 "IT","Italy",1 "JP","Japan",3 "KW","Kuwait",4 "MX","Mexico",2 "NG","Nigeria",4 "NL","Netherlands",1 "SG","Singapore",3 "UK","United Kingdom",1 "US","United States of America",2 "ZM","Zambia",4 "ZW","Zimbabwe",4 25 rows selected.
In questo caso, ho girato HEADINGS di nuovo dopo aver esportato il file.
Rimuovi feedback
Puoi rimuovere il X rows selected con SET FEEDBACK off :
SET SQLFORMAT csv
SET HEADING off
SET FEEDBACK off
SPOOL '/Users/barney/data/countries.csv';
SELECT * FROM countries;
SPOOL off;
SET SQLFORMAT ansiconsole
SET HEADING on
SET FEEDBACK onRisultato:
"AR","Argentina",2 "AU","Australia",3 "BE","Belgium",1 "BR","Brazil",2 "CA","Canada",2 "CH","Switzerland",1 "CN","China",3 "DE","Germany",1 "DK","Denmark",1 "EG","Egypt",4 "FR","France",1 "HK","HongKong",3 "IL","Israel",4 "IN","India",3 "IT","Italy",1 "JP","Japan",3 "KW","Kuwait",4 "MX","Mexico",2 "NG","Nigeria",4 "NL","Netherlands",1 "SG","Singapore",3 "UK","United Kingdom",1 "US","United States of America",2 "ZM","Zambia",4 "ZW","Zimbabwe",4
Qui, ho girato FEEDBACK riattivare dopo aver esportato il file.
Tabelle multiple
In questo esempio, esporto i risultati di una query leggermente più complessa che unisce due tabelle:
SET SQLFORMAT csv
SET HEADING off
SET FEEDBACK off
SPOOL '/Users/barney/data/employees_jobs.csv';
SELECT
e.employee_id,
e.first_name,
e.last_name,
e.salary,
j.job_title
FROM employees e
INNER JOIN jobs j
ON e.job_id = j.job_id
WHERE e.salary BETWEEN 12000 AND 15000
ORDER BY SALARY DESC;
SPOOL off;
SET SQLFORMAT ansiconsole
SET HEADING on
SET FEEDBACK onFile risultante:
145,"John","Russell",14000,"Sales Manager" 146,"Karen","Partners",13500,"Sales Manager" 201,"Michael","Hartstein",13000,"Marketing Manager" 147,"Alberto","Errazuriz",12000,"Sales Manager" 205,"Shelley","Higgins",12000,"Accounting Manager" 108,"Nancy","Greenberg",12000,"Finance Manager"
Aggiungi i risultati
Per impostazione predefinita, SPOOL utilizza REPLACE , che sostituisce il file se esiste già.
Tuttavia, possiamo usare il APPEND argomento per aggiungere i risultati al file.
SET SQLFORMAT csv
SET HEADING off
SET FEEDBACK off
SPOOL '/Users/barney/data/employees_jobs.csv' APPEND;
SELECT
e.employee_id,
e.first_name,
e.last_name,
e.salary,
j.job_title
FROM employees e
INNER JOIN jobs j
ON e.job_id = j.job_id
WHERE e.salary BETWEEN 11000 AND 11999
ORDER BY SALARY DESC;
SPOOL off;
SET SQLFORMAT ansiconsole
SET HEADING on
SET FEEDBACK onFile risultante:
145,"John","Russell",14000,"Sales Manager" 146,"Karen","Partners",13500,"Sales Manager" 201,"Michael","Hartstein",13000,"Marketing Manager" 147,"Alberto","Errazuriz",12000,"Sales Manager" 205,"Shelley","Higgins",12000,"Accounting Manager" 108,"Nancy","Greenberg",12000,"Finance Manager" 168,"Lisa","Ozer",11500,"Sales Representative" 174,"Ellen","Abel",11000,"Sales Representative" 114,"Den","Raphaely",11000,"Purchasing Manager" 148,"Gerald","Cambrault",11000,"Sales Manager"
Questo esempio ha aggiunto i risultati al file che è stato creato (e popolato) nell'esempio precedente.