Dal tuo commento alla risposta di @PrzemyslawKruglej
Il problema principale è con la query interna con connect by , genera un'incredibile quantità di righe
La quantità di righe generate può essere ridotta con il seguente approccio:
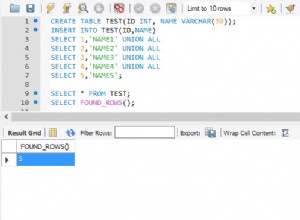
/* test table populated with sample data from your question */
SQL> create table t1(str) as(
2 select 'a;b;c' from dual union all
3 select 'b;c;d' from dual union all
4 select 'a;c;d' from dual
5 );
Table created
-- number of rows generated will solely depend on the most longest
-- string.
-- If (say) the longest string contains 3 words (wont count separator `;`)
-- and we have 100 rows in our table, then we will end up with 300 rows
-- for further processing , no more.
with occurrence(ocr) as(
select level
from ( select max(regexp_count(str, '[^;]+')) as mx_t
from t1 ) t
connect by level <= mx_t
)
select count(regexp_substr(t1.str, '[^;]+', 1, o.ocr)) as generated_for_3_rows
from t1
cross join occurrence o;
Risultato:Per tre righe in cui la più lunga è composta da tre parole, genereremo 9 righe :
GENERATED_FOR_3_ROWS
--------------------
9
Domanda finale:
with occurrence(ocr) as(
select level
from ( select max(regexp_count(str, '[^;]+')) as mx_t
from t1 ) t
connect by level <= mx_t
)
select res
, count(res) as cnt
from (select regexp_substr(t1.str, '[^;]+', 1, o.ocr) as res
from t1
cross join occurrence o)
where res is not null
group by res
order by res;
Risultato:
RES CNT
----- ----------
a 2
b 2
c 3
d 2
Dimostrazione SQLFIddle
Scopri di più sulle funzioni di espressione regolare regexp_count()(11g e superiori) e regexp_substr().
Nota: Le funzioni di espressione regolare sono relativamente costose da calcolare e, quando si tratta di elaborare una grande quantità di dati, potrebbe valere la pena considerare di passare a un semplice PL/SQL. Ecco un esempio.