Introduzione
I file di dati sono oggetti fisici che costituiscono la parte più importante del sistema di database poiché contengono dati effettivi. Puoi pensare a un database come a una raccolta di file di dati. Un'istanza fornisce i mezzi per montare e accedere a tali file.
Qui, la gestione dei file di dati significa capire come monitorare e ridimensionare i file di dati esistenti e come aggiungere o rimuovere i file di dati da un database.
I codici T-SQL per queste operazioni sono presenti nella documentazione Microsoft. Tuttavia, in questo articolo, vorremmo discutere le tattiche relative alla gestione di questi file per quelli di noi che eseguono ancora installazioni locali di SQL Server.
Tipi di file di dati e possibili problemi
Per ogni nuovo database creato in SQL Server, dobbiamo avere almeno due file creati:un file di dati primario e un file di registro.
- Il file di dati principale ha l'estensione .MDF.
- Il file di registro ha l'estensione .LDF.
- Quando aggiungiamo file di dati a un database di SQL Server, in genere utilizziamo l'estensione .NDF.
Nota :È possibile creare i file di dati in SQL Server senza alcuna estensione, ma non è la migliore pratica. L'uso di .mdf, .ndf e .ldf serve a distinguere questi file quando li visualizziamo a livello di sistema operativo.
Ovviamente, i file di dati vengono creati quando si crea un database. Puoi farlo con CREA DATABASE comando. Anche se sembra così facile, dovresti essere consapevole di possibili problemi.
A seconda della dimensione del database e dei file di dati associati, potresti dover affrontare problemi di frammentazione e altri problemi con il tempo di backup e lo spostamento dei dati. Succede che i file di dati non siano dimensionati correttamente.
Dai un'occhiata all'illustrazione qui sotto. Mostra il risultato dell'esecuzione di CREATE DATABASE e fornisce il nome del database (MyDB).
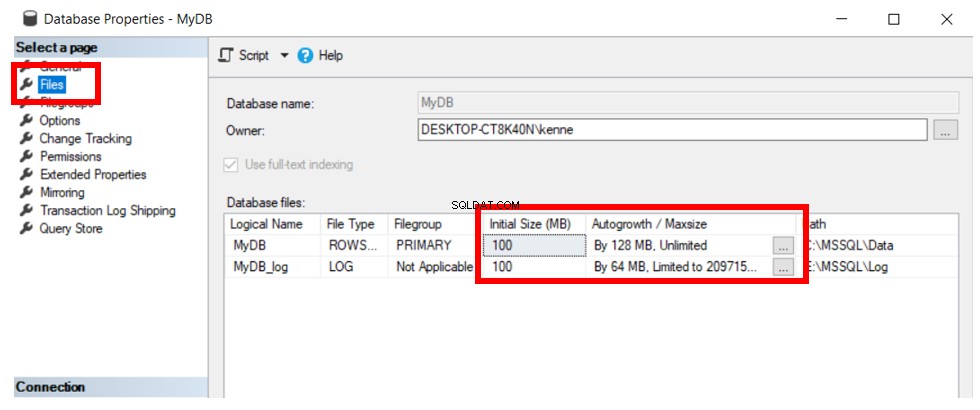
Il Listato 1 mostra i dettagli del database creato:
-- Listing 1: Create Database Script
USE [master]
GO
/****** Object: Database [MyDB] Script Date: 29/11/2020 10:38:18 pm ******/
CREATE DATABASE [MyDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'MyDB', FILENAME = N'C:\MSSQL\Data\MyDB.mdf' , SIZE = 102400KB , MAXSIZE = UNLIMITED, FILEGROWTH = 131072KB )
LOG ON
( NAME = N'MyDB_log', FILENAME = N'E:\MSSQL\Log\MyDB_log.ldf' , SIZE = 102400KB , MAXSIZE = 2048GB , FILEGROWTH = 65536KB )
GO
IF (1 = FULLTEXTSERVICEPROPERTY('IsFullTextInstalled'))
begin
EXEC [MyDB].[dbo].[sp_fulltext_database] @action = 'enable'
end
GO
Potresti chiederti da dove SQL Server ha ottenuto tutte queste opzioni, dal momento che tutto ciò che abbiamo fatto è stato emettere CREATE DATABASE MyDB.
SQL Server utilizza le impostazioni del database del modello come valori predefiniti per qualsiasi nuovo database creato in tale istanza. In questo caso vediamo la dimensione del file iniziale di 100 MB. La crescita automatica è rispettivamente di 12 MB e 64 MB per i file di dati e di registro.
I problemi che ne conseguono
Le implicazioni delle impostazioni evidenziate nella Figura 1 sono:
- Il file di dati primario inizia dalla dimensione di 100 MB. È una piccola dimensione. Pertanto, a seconda del livello di attività nel database, dovrà crescere molto presto.
- Ogni volta che è necessario crescere automaticamente il file di dati, il server SQL deve acquisire 128 MB dallo spazio disponibile sul sistema operativo. Di nuovo, è piccolo, il che implica che il database crescerà automaticamente spesso . La crescita del database è un'operazione costosa che può influire sulle prestazioni se si verifica troppo spesso. Inoltre, la crescita frequente dei database può causare un fenomeno chiamato frammentazione che, a sua volta, ha il vantaggio di causare un grave degrado delle prestazioni dei database. L'altro estremo dell'impostazione dell'incremento su un valore elevato può comportare che le operazioni di crescita richiedano molto tempo per essere completate, a seconda delle prestazioni del sistema di storage sottostante.
- I file di database possono crescere indefinitamente. Significa che, con un tempo sufficiente consentito, questi file possono consumare tutto lo spazio sul volume in cui si trovano. Per spostarli, è necessario un volume della loro dimensione o più. Un'altra opzione è aggiungere spazio di archiviazione al volume quando questi file sono archiviati.
Questi sono problemi chiave associati alla dipendenza dai valori predefiniti per la creazione di database.
Pre-assegnazione
Dato l'impatto della crescita sulle prestazioni, sarebbe più sensato dimensionare correttamente il database all'inizio del progetto. In questo modo soddisfiamo i requisiti delle soluzioni per il prossimo futuro.
Supponiamo di sapere che il nostro database alla fine avrà una dimensione di 1 GB. Potremmo allocare 1 GB di spazio di archiviazione all'avvio del progetto. Quindi, il database non ha mai bisogno di crescere. Elimina i problemi di frammentazione causati dalla crescita del database.
Il Listato 2 mostra lo script applicabile a questa pre-allocazione:
-- Listing 2: Create Database Script with Pre-allocation
USE [master]
GO
/****** Object: Database [MyDB] Script Date: 29/11/2020 10:38:18 pm ******/
CREATE DATABASE [MyDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'MyDB', FILENAME = N'C:\MSSQL\Data\MyDB.mdf' , SIZE = 1024MB , MAXSIZE = 2048MB, FILEGROWTH = 512MB )
LOG ON
( NAME = N'MyDB_log', FILENAME = N'E:\MSSQL\Log\MyDB_log.ldf' , SIZE = 512MB , MAXSIZE = 2048GB , FILEGROWTH = 512MB )
GO
IF (1 = FULLTEXTSERVICEPROPERTY('IsFullTextInstalled'))
begin
EXEC [MyDB].[dbo].[sp_fulltext_database] @action = 'enable'
end
GO
Citiamo 1 GB di spazio a scopo dimostrativo. In genere, un database di produzione può richiedere 1 TB. Il punto è:allocare lo spazio necessario all'inizio. Quindi elimini o riduci significativamente la necessità di crescita.
Ora, dobbiamo chiederci se vogliamo davvero un singolo file da 1 TB seduto sul nostro volume. Sarebbe saggio scomporlo in pezzi più piccoli. Quando si verificano operazioni parallele, come i backup, ogni file verrà indirizzato da un singolo thread della CPU per un sistema multiprocessore. Con un singolo file, non andrebbe bene.
Ancora una volta, modifichiamo il nostro script per soddisfare questo requisito nel Listato 3:
-- Listing 3: Create Database Script with Pre-allocation and
USE [master]
GO
/****** Object: Database [MyDB] Script Date: 29/11/2020 10:38:18 pm ******/
CREATE DATABASE [MyDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'MyDB01', FILENAME = N'C:\MSSQL\Data\MyDB01.mdf' , SIZE = 256MB , MAXSIZE = 512MB, FILEGROWTH = 512MB ) ,
( NAME = N'MyDB02', FILENAME = N'C:\MSSQL\Data\MyDB02.ndf' , SIZE = 256MB , MAXSIZE = 512MB, FILEGROWTH = 512MB )
( NAME = N'MyDB03', FILENAME = N'C:\MSSQL\Data\MyDB03.ndf' , SIZE = 256MB , MAXSIZE = 512MB, FILEGROWTH = 512MB ) ,
( NAME = N'MyDB04', FILENAME = N'C:\MSSQL\Data\MyDB04.ndf' , SIZE = 256MB , MAXSIZE = 512MB, FILEGROWTH = 512MB ) ,
( NAME = N'MyDB05', FILENAME = N'C:\MSSQL\Data\MyDB05.ndf' , SIZE = 256MB , MAXSIZE = 512MB, FILEGROWTH = 512MB )
LOG ON
( NAME = N'MyDB_log', FILENAME = N'E:\MSSQL\Log\MyDB_log.ldf' , SIZE = 512MB , MAXSIZE = 2048GB , FILEGROWTH = 512MB )
GO
IF (1 = FULLTEXTSERVICEPROPERTY('IsFullTextInstalled'))
begin
EXEC [MyDB].[dbo].[sp_fulltext_database] @action = 'enable'
end
GO
Informazioni aggiuntive
Dovremmo anche ricordare che non c'è alcun valore nell'usare questo approccio per i file di registro. Il fatto è che SQL Server scrive sempre nei file di registro in sequenza. Inoltre, abbiamo utilizzato l'estensione .ndf per i nuovi file che stiamo aggiungendo.
La clausola MAXSIZE garantisce che i nostri file di dati non crescano indefinitamente. Abbiamo assegnato a ciascun file un nome logico e fisico diverso:la clausola NAME specifica il nome logico del file e la clausola FILENAME specifica il nome fisico.
La creazione di un database con file di dati più grandi richiederà più tempo che altrimenti. Potrebbe essere più ragionevole creare prima un database di piccole dimensioni, quindi manipolarlo con i comandi appropriati per ridimensionare e aggiungere file, fino a stabilire una struttura di database ideale.
Creando il database con opzioni esplicite, abbiamo affrontato le tre preoccupazioni sollevate in precedenza in questo articolo. La figura 2 mostra il risultato di questo approccio:
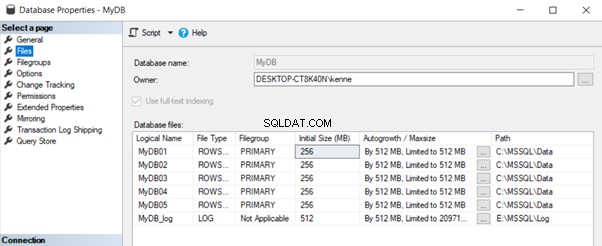
Ora abbiamo un database configurato correttamente per accogliere la crescita dei dati per un periodo prolungato senza la necessità di una crescita del file di dati. Elimina i rischi di frammentazione e aiuta a garantire una migliore gestione dei file di dati.
Gestione dei file di dati
Invece di creare quattro o cinque file di dati nell'istruzione CREATE DATABASE, possiamo utilizzare le clausole MODIFY e ADD dell'istruzione T-SQL ALTER DATABASE.
Ancora una volta, iniziamo con l'affermazione mostrata nel Listato 4 di seguito. Crea un unico database con il file di dati da 100 MB e un file di registro di accompagnamento. Il nostro obiettivo è garantire la pre-allocazione estendendo questo file e quindi aggiungendo altri file.
-- Listing 4: Create Database Script
USE [master]
GO
IF EXISTS (SELECT * FROM sys.databases WHERE name='MyDB')
DROP DATABASE MyDB;
/****** Object: Database [MyDB] Script Date: 29/11/2020 10:38:18 pm ******/
CREATE DATABASE [MyDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'MyDB', FILENAME = N'C:\MSSQL\Data\MyDB.mdf' , SIZE = 102400KB , MAXSIZE = UNLIMITED, FILEGROWTH = 131072KB )
LOG ON
( NAME = N'MyDB_log', FILENAME = N'E:\MSSQL\Log\MyDB_log.ldf' , SIZE = 102400KB , MAXSIZE = 2048GB , FILEGROWTH = 65536KB )
GO
IF (1 = FULLTEXTSERVICEPROPERTY('IsFullTextInstalled'))
begin
EXEC [MyDB].[dbo].[sp_fulltext_database] @action = 'enable'
end
GO
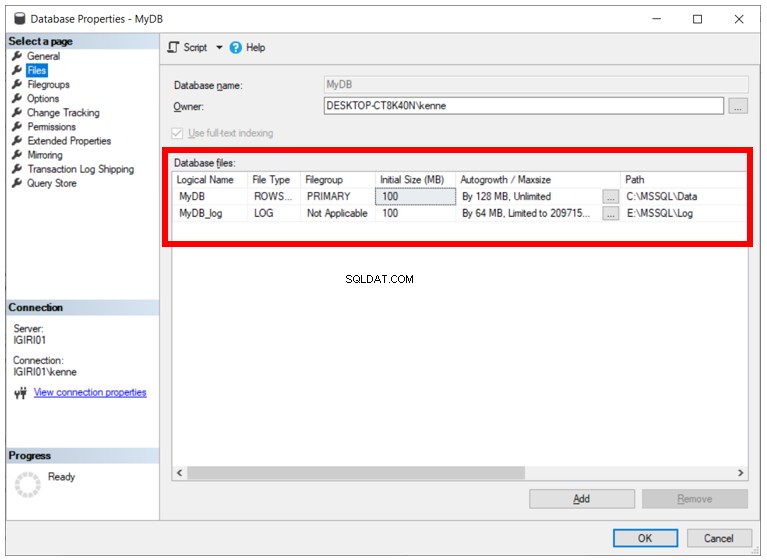
Estendi i file di dati
L'istruzione T-SQL che estende un file di dati è mostrata nel Listato 5. Specifica il nome del database, il nome del file e la dimensione iniziale e l'incremento desiderati. In questo caso, impostiamo SQL Server per allocare 1 GB all'avvio e quindi allocare 512 MB per tutte le successive espansioni automatiche.
-- Listing 5: Extend the Primary Datafile
USE [master]
GO
ALTER DATABASE [MyDB] MODIFY FILE ( NAME = N'MyDB', SIZE = 1048576KB , FILEGROWTH = 524288KB )
GO
Il Listato 6 mostra come sarebbe il codice se specifichiamo il MAXSIZE di 2GB:
-- Listing 6: Extend the Primary Datafile with Maximum Size
USE [master]
GO
ALTER DATABASE [MyDB] MODIFY FILE ( NAME = N'MyDB', SIZE = 1048576KB , MAXSIZE = 2097152KB , FILEGROWTH = 524288KB )
GO
Se impostiamo la clausola FILEGROWTH su 0, impostiamo il nostro SQL Server NON per aumentare automaticamente il file di dati . In questo caso, dobbiamo emettere esplicitamente comandi per aumentare il file di dati o aggiungere altri file.
Aggiunta di file di dati
Il Listato 7 mostra il codice che utilizziamo per aggiungere un nuovo file di dati al database. Nota che dobbiamo specificare nuovamente il nome del file logico e il nome del file fisico che include un percorso completo.
Inoltre, possiamo posizionare il file fisico su un volume diverso. Per questo, dobbiamo solo cambiare il percorso.
-- Listing 7: Add Data Files to the Primary Filegroup
USE [master]
GO
ALTER DATABASE [MyDB] ADD FILE ( NAME = N'MyDB01', FILENAME = N'C:\MSSQL\Data\MyDB01.ndf' , SIZE = 1048576KB , FILEGROWTH = 524288KB ) TO FILEGROUP [PRIMARY]
GO
L'estensione e l'aggiunta di file di dati si applicano anche allo scenario in cui scegliamo di disabilitare la crescita automatica per i nostri database (vedere la figura 4).
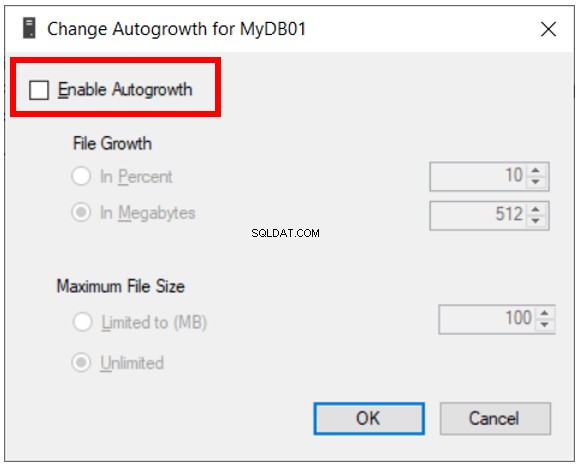
Quindi dobbiamo estendere manualmente il database utilizzando i codici sopra riportati dai Listing 5 o 6, oppure aggiungere file come nel Listing 7.
Utilizzo dei filegroup
I filegroup ci consentono di gestire insieme le raccolte di file di dati. Possiamo raggruppare logicamente alcuni file di dati archiviati su dischi diversi o volumi diversi in un gruppo di file. Quel filegroup crea un livello di astrazione tra le tabelle e gli indici e i file fisici effettivi che memorizzano i dati.
Pertanto, se creiamo una tabella su un filegroup, i dati in questa tabella vengono distribuiti su tutti i file di dati assegnati al filegroup.
Fino a questo punto, abbiamo avuto a che fare solo con il filegroup PRIMARY. Il Listato 8 mostra come possiamo aggiungere un nuovo file MyDB02 a un filegroup, diverso dal filegroup principale.
La prima istruzione dopo aver impostato il contesto del database su master crea il nuovo filegroup FG01. L'istruzione successiva aggiunge quindi il file a questo nuovo filegroup con opzioni simili a quelle usate nel Listato 7.
-- Listing 8: Add Data Files to the Primary Filegroup
USE [master]
GO
ALTER DATABASE [MyDB] ADD FILEGROUP [FG01]
GO
ALTER DATABASE [MyDB] ADD FILE ( NAME = N'MyDB02', FILENAME = N'C:\MSSQL\Data\MyDB02.ndf' , SIZE = 102400KB , MAXSIZE = 2097152KB , FILEGROWTH = 524288KB ) TO FILEGROUP [FG01]
GO
Eliminazione dei file di dati
La figura 5 mostra l'esito delle operazioni finora eseguite. Abbiamo tre file di dati. Due di loro si trovano nel filegroup PRIMARY e il terzo nel filegroup FG01.
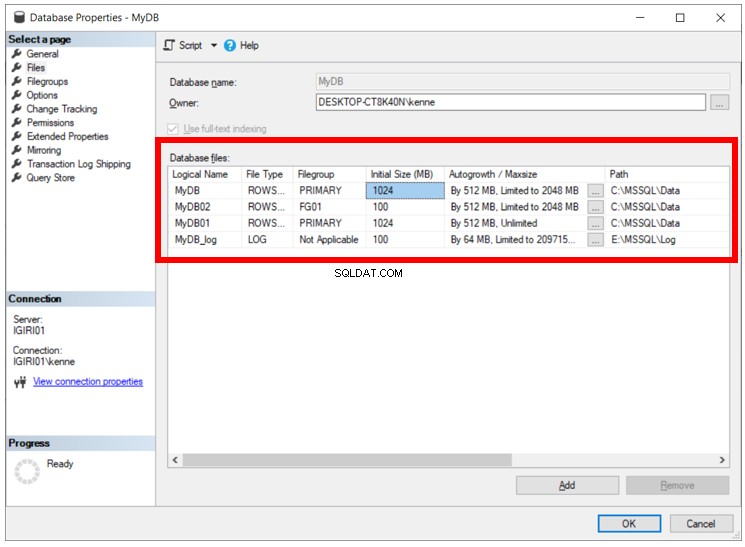
Supponiamo di aver fatto qualcosa di sbagliato, ad esempio, impostare la dimensione del file errata. Quindi, possiamo eliminare il filegroup utilizzando il seguente codice nel Listato 9:
-- Listing 9: Drop Data Files
USE [MyDB]
GO
ALTER DATABASE [MyDB] REMOVE FILE [MyDB02]
GO
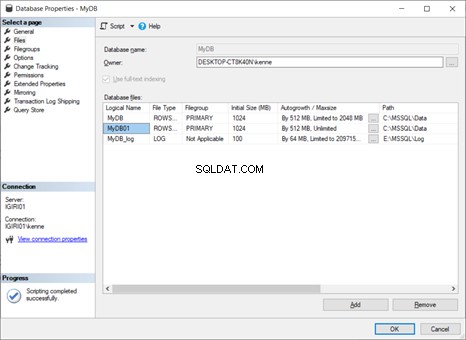
Conclusione
Questo articolo ha esplorato i tipi di file di database, le possibili complicazioni causate dalla crescita dei file di dati e le modalità per risolvere il problema. Inoltre, abbiamo esaminato i codici T-SQL per estendere i file di dati e aggiungere nuovi file di dati a un database. Abbiamo anche toccato l'uso dei filegroup.
Il nostro obiettivo è garantire che quando distribuiamo i database, lo prepariamo per archiviare tutti i dati di cui avrà bisogno per una particolare applicazione.
Riferimenti
- File di database e filegroup