A volte capita di dover elaborare un file di testo o CSV molto grande, ma prima si desidera creare file più piccoli di quel file di grandi dimensioni. Perché un file di grandi dimensioni potrebbe richiedere troppo tempo per l'elaborazione o l'apertura. Quindi sto fornendo un esempio di seguito per dividere file di testo/CSV di grandi dimensioni in più file in PL SQL utilizzando la procedura memorizzata.
Devi solo passare due parametri a questa procedura PL SQL, il primo è il nome dell'oggetto della directory del database, dove risiedono i file di testo e il secondo è il nome del file di origine (il file che vuoi dividere).
Se l'oggetto directory Oracle non esiste per la posizione dei file di testo, puoi crearlo come mostrato di seguito:
For windows: CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS 'D:\plsql\text_files';
For Linux/Unix (due to difference in path): CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS '/plsql/text_files';
Cambia il percorso sopra in base alla posizione dei tuoi file. Quindi crea la procedura seguente eseguendo il suo script:
CREATE OR REPLACE PROCEDURE split_file (p_db_dir IN VARCHAR2, p_file_name IN VARCHAR2) IS read_file UTL_FILE.file_type; write_file UTL_FILE.file_type; v_string VARCHAR2 (32767); j NUMBER := 1; BEGIN read_file := UTL_FILE.fopen (p_db_dir, p_file_name, 'r'); WHILE j > 0 LOOP write_file := UTL_FILE.fopen (p_db_dir, j || '_' || p_file_name, 'w'); FOR i IN 1 .. 100 LOOP -- example to dividing into 100 rows for each file.. you can increase the number as per your requirement UTL_FILE.get_line (read_file, v_string); UTL_FILE.put_line (write_file, v_string); END LOOP; UTL_FILE.fclose (write_file); j := J + 1; END LOOP; EXCEPTION WHEN OTHERS THEN -- this will handle if reading source file contents finish UTL_FILE.fclose (read_file); UTL_FILE.fclose (write_file); END;
Questa procedura divide 100 righe per ogni file, che puoi modificare secondo le tue esigenze. Ora esegui questa procedura come mostrato di seguito passando il nome dell'oggetto della directory del database e il nome del file:
BEGIN
split_file ('CSV_FILE_DIR', 'text_file.csv');
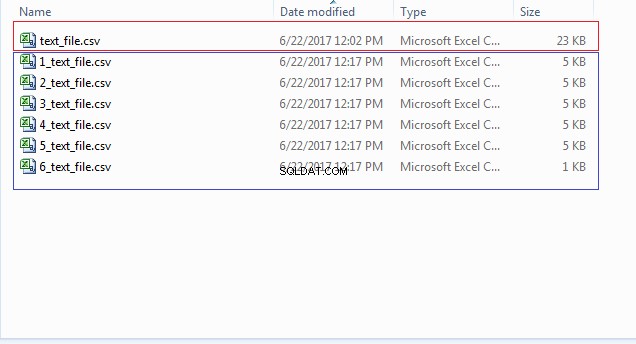
END; Puoi controllare la posizione del tuo file (CSV_FILE_DIR) per i file multipli che iniziano con numeri come 1_text_file.csv, 2_text_file.csv e così via, come mostrato nell'immagine seguente: