L'elevata disponibilità è un must di questi tempi poiché la maggior parte delle organizzazioni non può permettersi di perdere i propri dati. L'alta disponibilità, tuttavia, ha sempre un prezzo (che può variare molto). Qualsiasi configurazione che richieda un'azione quasi immediata richiederebbe in genere un ambiente costoso che rispecchierebbe esattamente l'impostazione di produzione. Ma ci sono altre opzioni che possono essere meno costose. Questi potrebbero non consentire il passaggio immediato a un cluster di ripristino di emergenza, ma consentiranno comunque la continuità aziendale (e non prosciugheranno il budget).
Un esempio di questo tipo di configurazione è un ambiente DR "cold-standby". Ti consente di ridurre le tue spese pur essendo in grado di creare un nuovo ambiente in un luogo esterno in caso di disastro. In questo post del blog dimostreremo come creare una tale configurazione.
La configurazione iniziale
Supponiamo di avere una configurazione di replica MySQL Master/Slave abbastanza standard nel nostro datacenter. È una configurazione ad alta disponibilità con ProxySQL e Keepalived per la gestione di IP virtuali. Il rischio principale è che il datacenter non sia disponibile. È un piccolo controller di dominio, forse è solo un ISP senza BGP in atto. E in questa situazione, assumeremo che se ci vogliono ore per ripristinare il database, è ok purché sia possibile ripristinarlo.
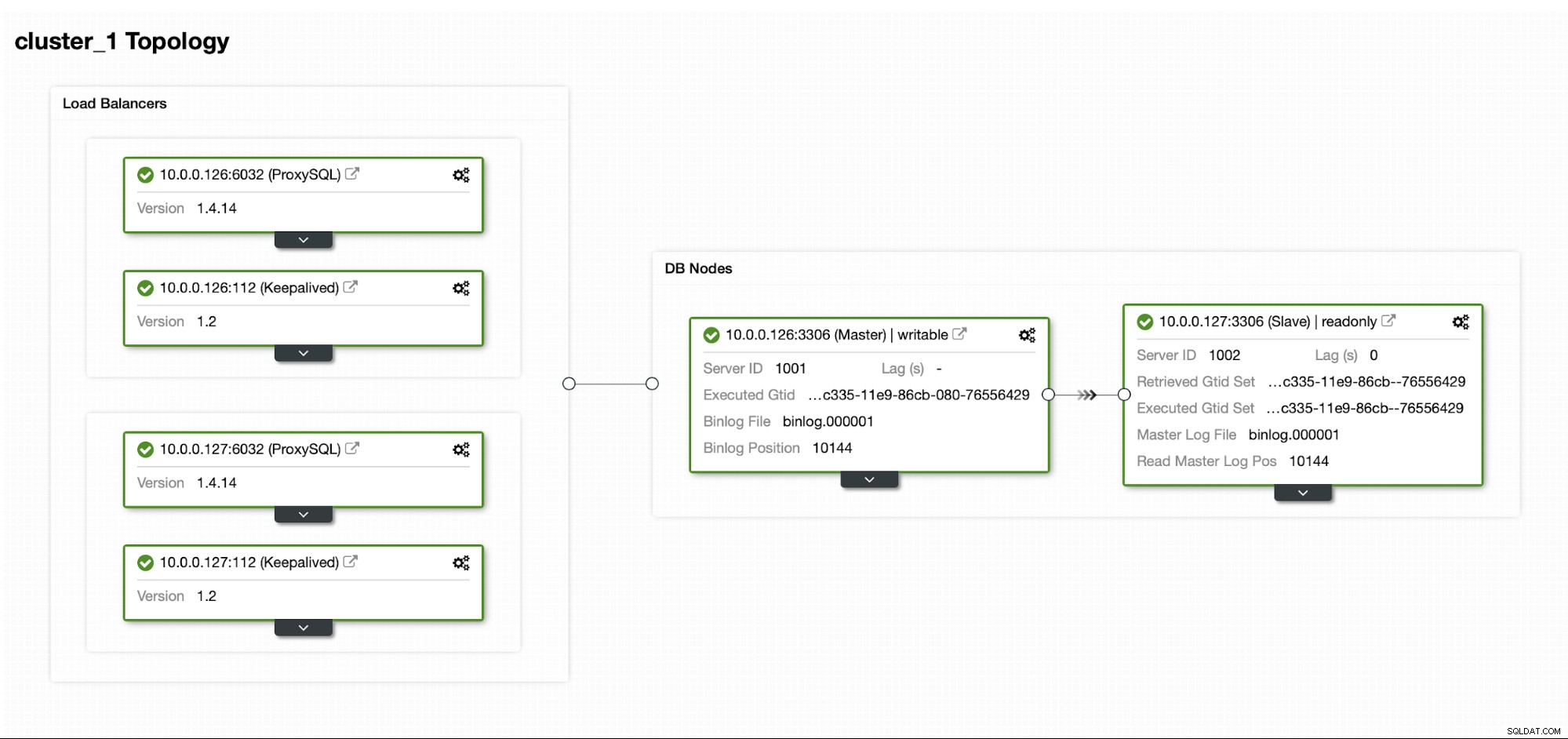
Per distribuire questo cluster abbiamo utilizzato ClusterControl, che puoi scaricare gratuitamente. Per il nostro ambiente DR utilizzeremo EC2 (ma potrebbe anche essere qualsiasi altro provider cloud.)
La sfida
Il problema principale che dobbiamo affrontare è come dovremmo assicurarci di avere nuovi dati per ripristinare il nostro database nell'ambiente di ripristino di emergenza? Ovviamente, idealmente avremmo uno slave di replica attivo e funzionante in EC2... ma poi dobbiamo pagarlo. Se il budget è limitato, potremmo cercare di aggirare il problema con i backup. Questa non è la soluzione perfetta poiché, nel peggiore dei casi, non saremo mai in grado di recuperare tutti i dati.
Per "scenario peggiore" intendiamo una situazione in cui non avremo accesso ai server di database originali. Se fossimo in grado di raggiungerli, i dati non sarebbero andati persi.
La soluzione
Utilizzeremo ClusterControl per impostare una pianificazione di backup per ridurre la possibilità che i dati vadano persi. Utilizzeremo anche la funzione ClusterControl per caricare i backup nel cloud. Se il datacenter non sarà disponibile, possiamo sperare che il provider cloud che abbiamo scelto sia raggiungibile.
Impostazione della pianificazione del backup in ClusterControl
In primo luogo, dovremo configurare ClusterControl con le nostre credenziali cloud.
Possiamo farlo usando "Integrazioni" dal menu a sinistra.
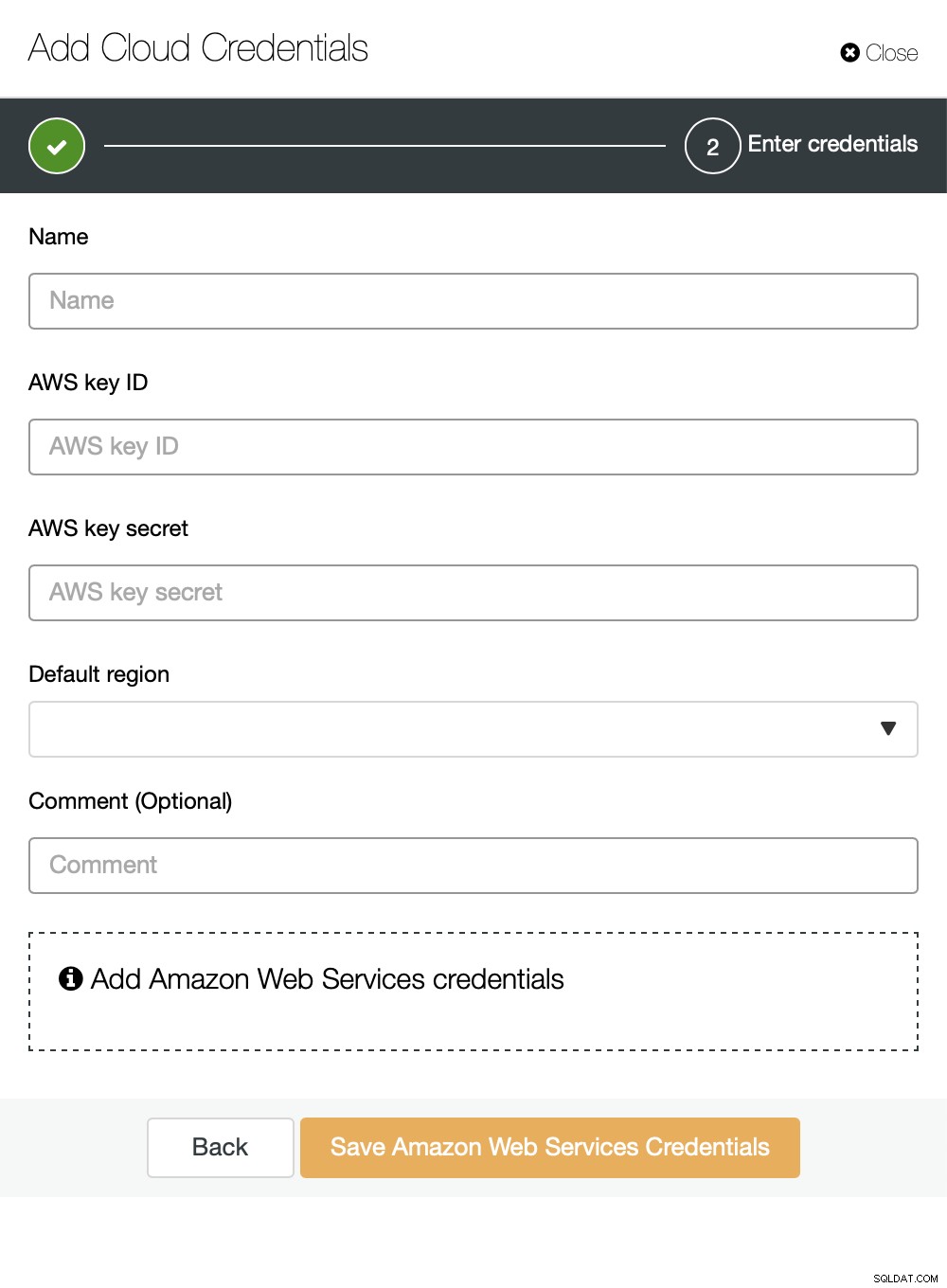
Puoi scegliere Amazon Web Services, Google Cloud o Microsoft Azure come cloud in cui si desidera che ClusterControl carichi i backup. Andremo avanti con AWS in cui ClusterControl utilizzerà S3 per archiviare i backup.
Dobbiamo quindi passare l'ID chiave e il segreto della chiave, scegliere la regione predefinita e scegli un nome per questo set di credenziali.
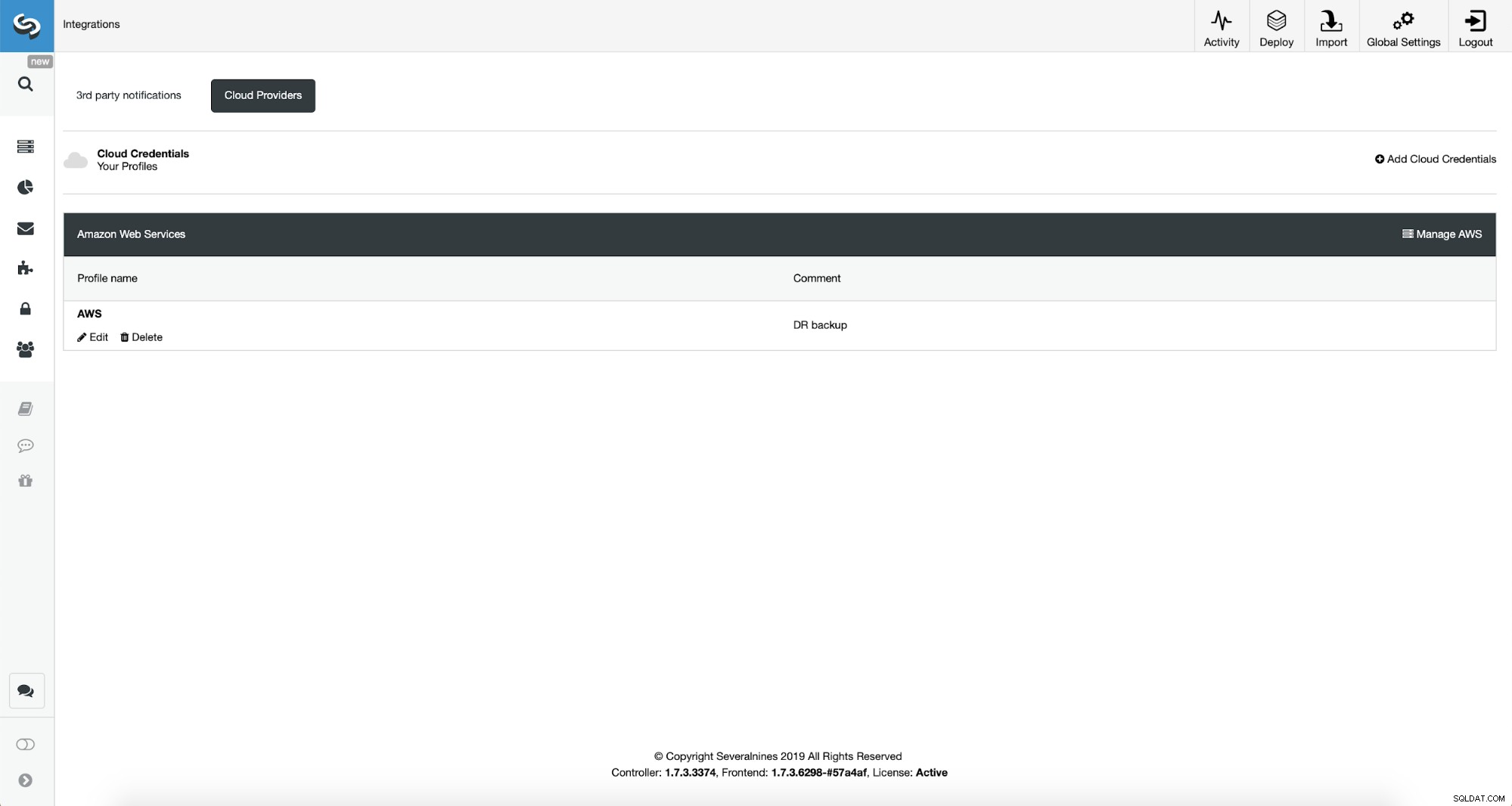
Una volta fatto, possiamo vedere le credenziali che abbiamo appena aggiunto elencate in ClusterControl.
Ora, procederemo con l'impostazione della pianificazione del backup.
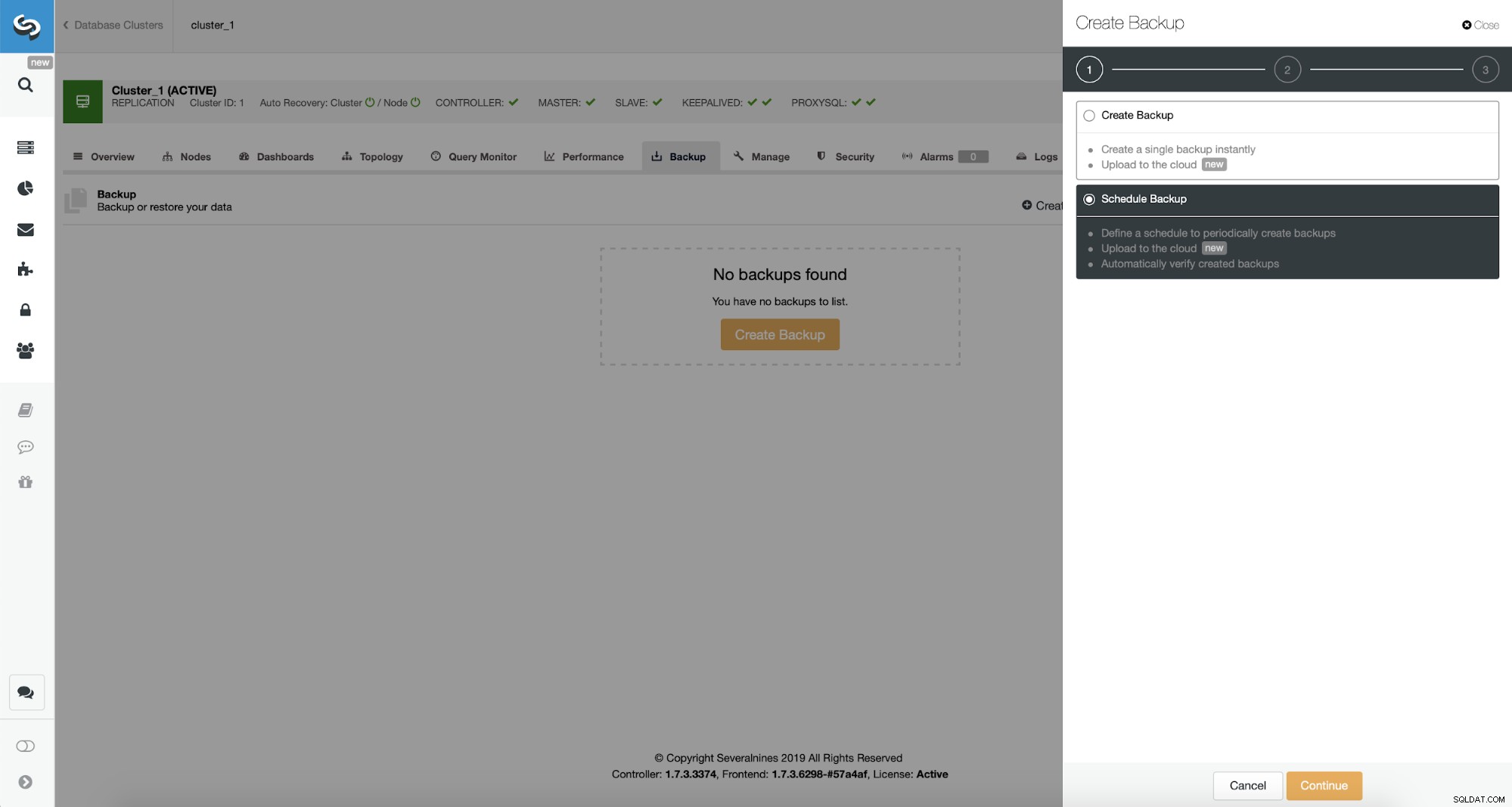
ClusterControl consente di creare backup immediatamente o pianificarlo. Andremo con la seconda opzione. Quello che vogliamo è creare una pianificazione seguente:
- Backup completo creato una volta al giorno
- Backup incrementali creati ogni 10 minuti.
L'idea qui è la seguente. Nel peggiore dei casi perderemo solo 10 minuti di traffico. Se il datacenter non sarà più disponibile dall'esterno ma funzionerebbe internamente, potremmo cercare di evitare qualsiasi perdita di dati attendendo 10 minuti, copiando l'ultimo backup incrementale su alcuni laptop e quindi possiamo inviarlo manualmente al nostro database DR utilizzando anche il tethering del telefono e una connessione cellulare per aggirare il guasto dell'ISP. Se non saremo in grado di estrarre i dati dal vecchio datacenter per un po' di tempo, questo ha lo scopo di ridurre al minimo la quantità di transazioni che dovremo unire manualmente nel database DR.
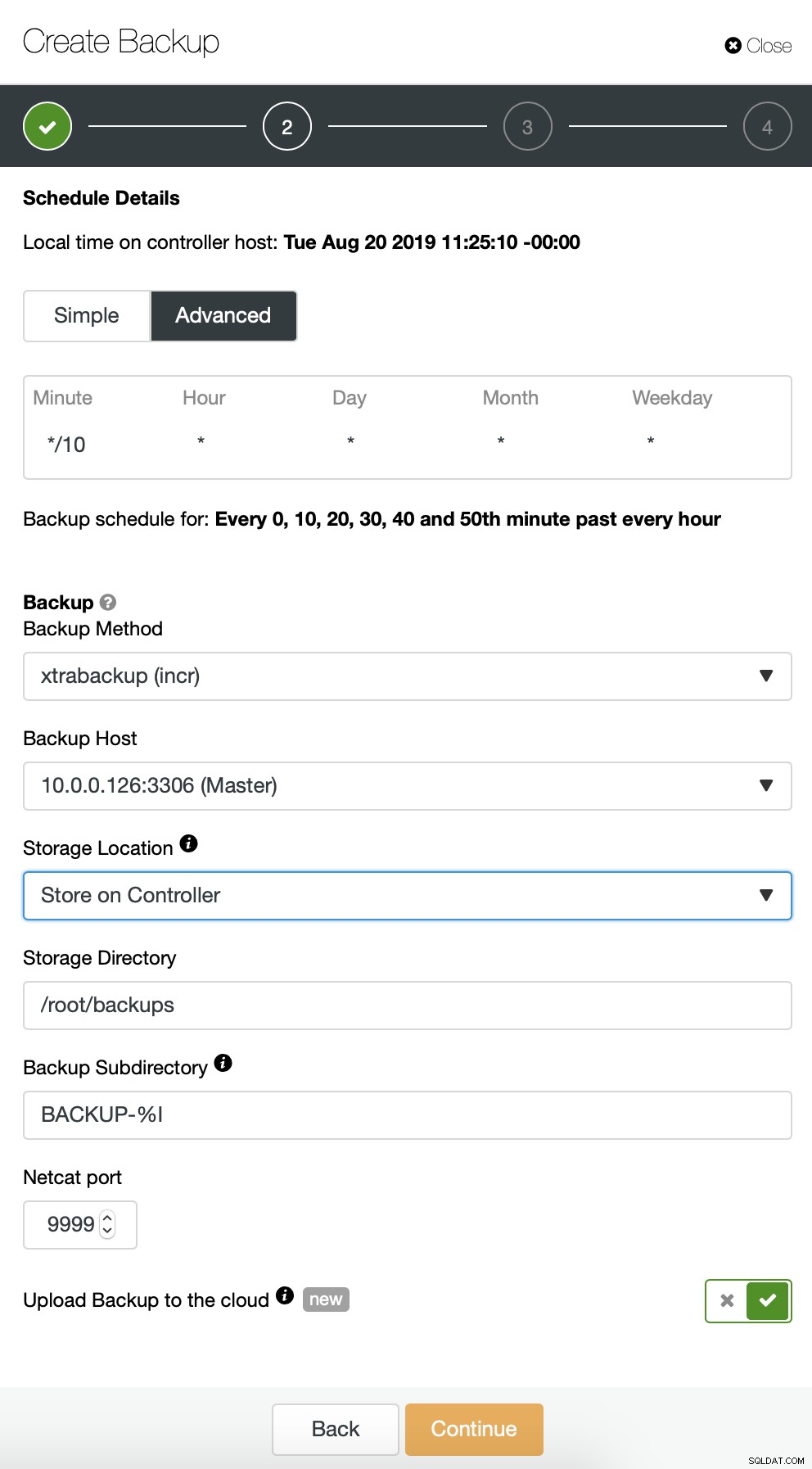
Iniziamo con il backup completo che avverrà ogni giorno alle 2:00 del mattino. Useremo il master da cui prelevare il backup, lo memorizzeremo sul controller nella directory /root/backups/. Abiliteremo anche l'opzione "Carica backup nel cloud".
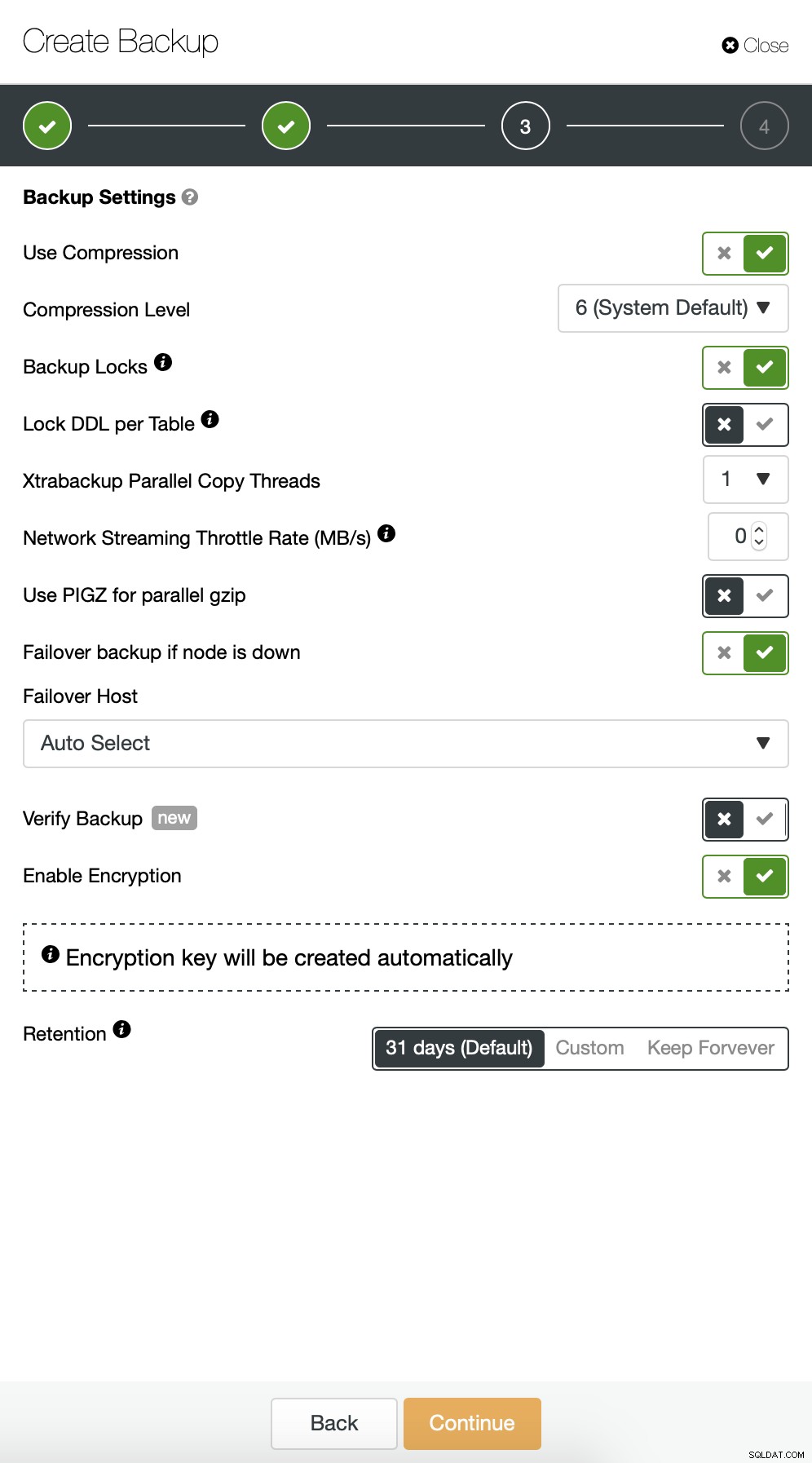
In seguito, vogliamo apportare alcune modifiche alla configurazione predefinita. Abbiamo deciso di utilizzare l'host di failover selezionato automaticamente (nel caso in cui il nostro master non fosse disponibile, ClusterControl utilizzerà qualsiasi altro nodo disponibile). Volevamo anche abilitare la crittografia poiché invieremo i nostri backup sulla rete.
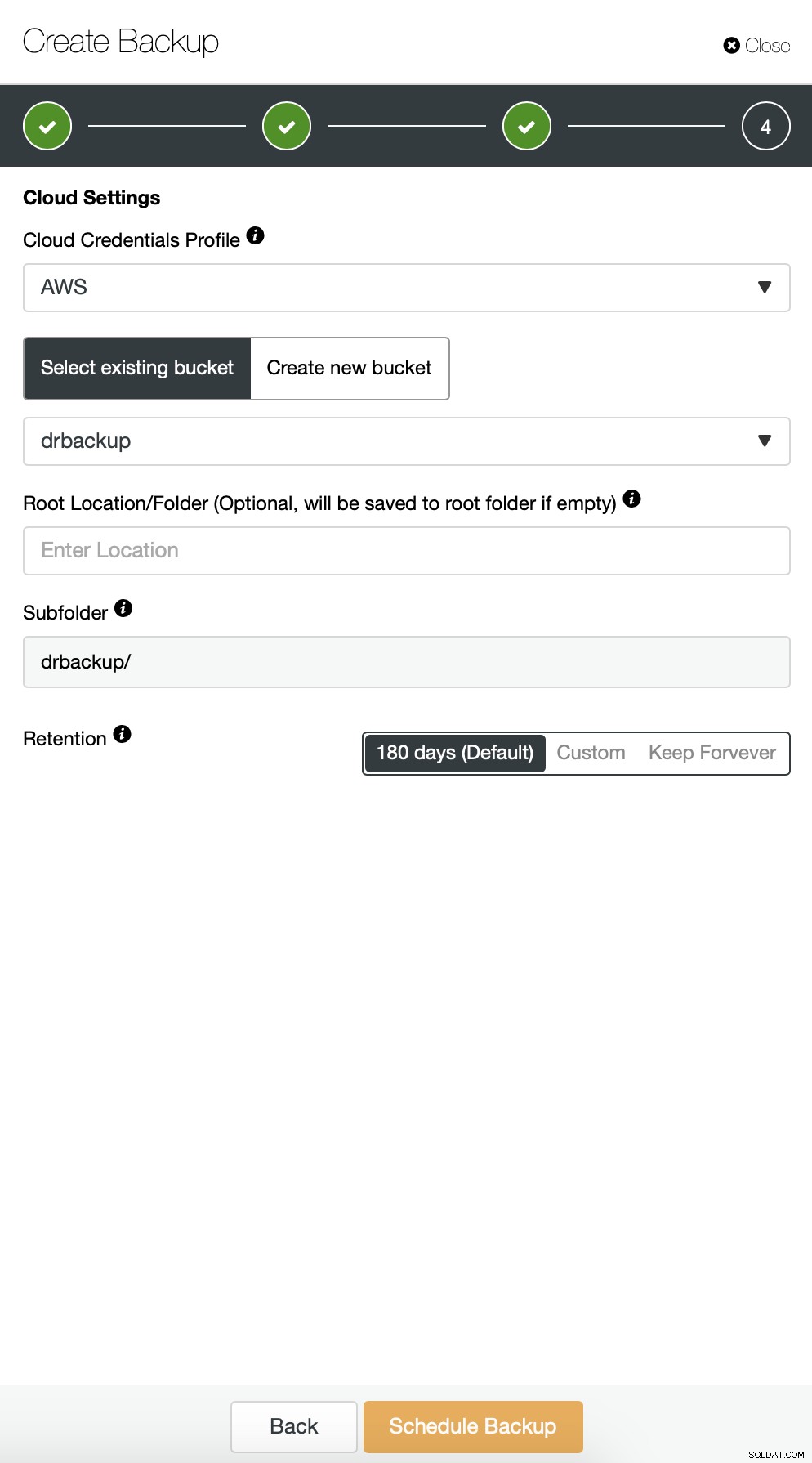
Quindi dobbiamo scegliere le credenziali, selezionare il bucket S3 esistente o creare un nuovo se necessario.
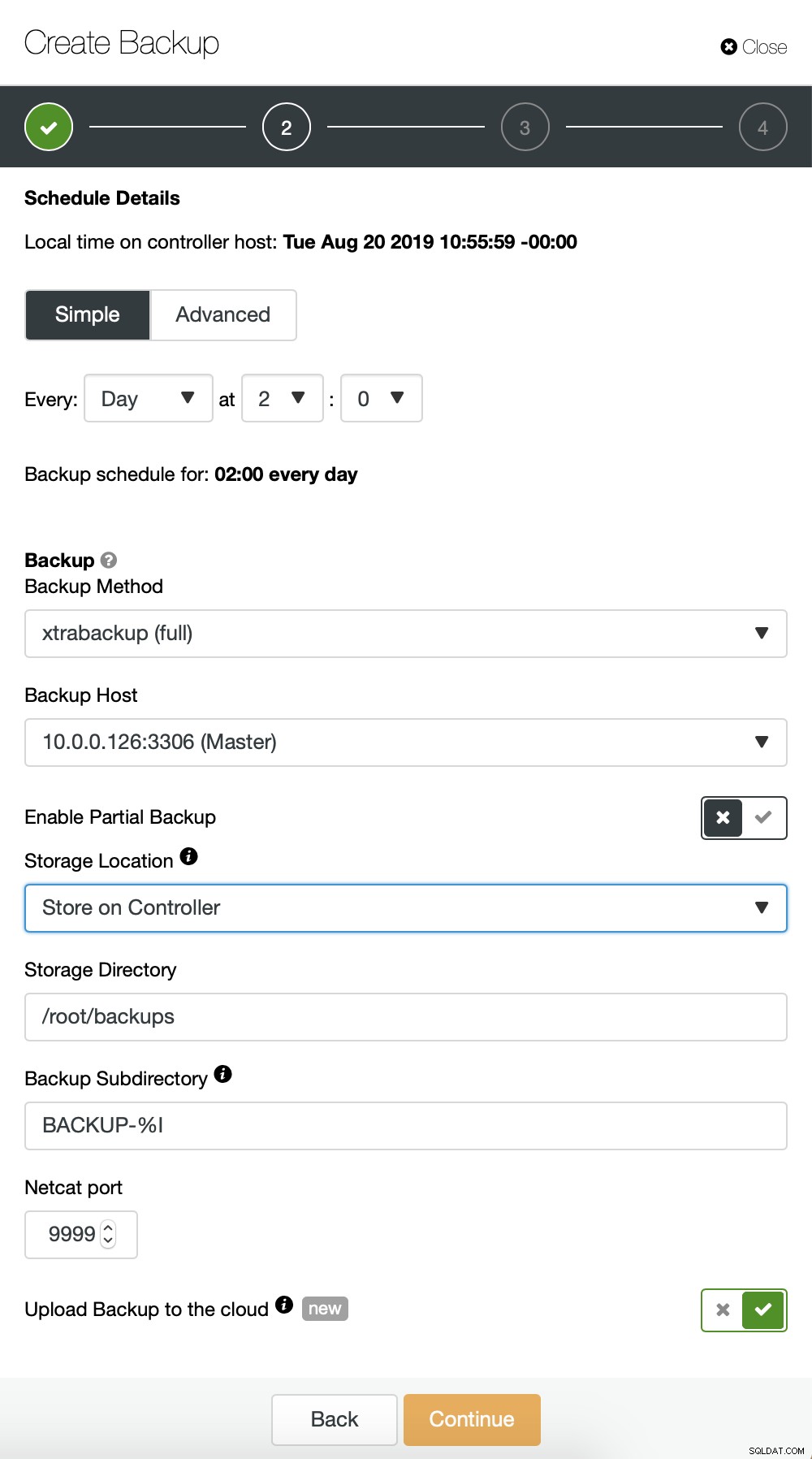
Stiamo sostanzialmente ripetendo il processo per il backup incrementale, questa volta abbiamo utilizzato la finestra di dialogo "Avanzate" per eseguire i backup ogni 10 minuti.
Il resto delle impostazioni è simile, possiamo anche riutilizzare il bucket S3.
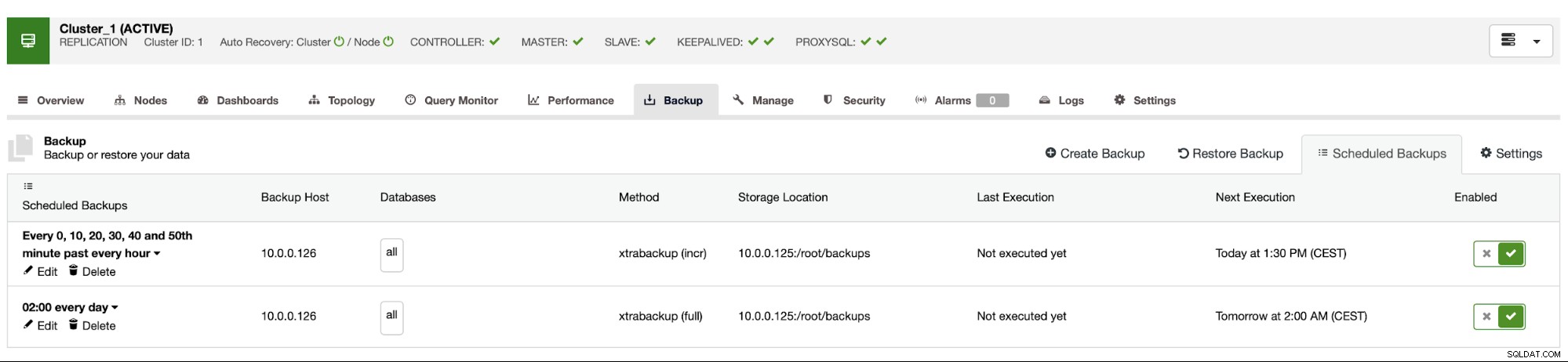
La pianificazione del backup appare come sopra. Non è necessario avviare manualmente il backup completo, ClusterControl eseguirà il backup incrementale come pianificato e se rileva che non è disponibile un backup completo, eseguirà un backup completo anziché quello incrementale.
Con tale configurazione possiamo essere sicuri di poter recuperare i dati su qualsiasi sistema esterno con una granularità di 10 minuti.
Ripristino backup manuale
Se ti capita di dover ripristinare il backup sull'istanza di ripristino di emergenza, devi eseguire un paio di passaggi. Ti consigliamo vivamente di testare questo processo di tanto in tanto, assicurandoti che funzioni correttamente e che tu sia esperto nell'eseguirlo.
Per prima cosa, dobbiamo installare lo strumento a riga di comando AWS sul nostro server di destinazione:
example@sqldat.com:~# apt install python3-pip
example@sqldat.com:~# pip3 install awscli --upgrade --userQuindi dobbiamo configurarlo con le credenziali appropriate:
example@sqldat.com:~# ~/.local/bin/aws configure
AWS Access Key ID [None]: yourkeyID
AWS Secret Access Key [None]: yourkeySecret
Default region name [None]: us-west-1
Default output format [None]: jsonOra possiamo verificare se abbiamo accesso ai dati nel nostro bucket S3:
example@sqldat.com:~# ~/.local/bin/aws s3 ls s3://drbackup/
PRE BACKUP-1/
PRE BACKUP-2/
PRE BACKUP-3/
PRE BACKUP-4/
PRE BACKUP-5/
PRE BACKUP-6/
PRE BACKUP-7/Ora dobbiamo scaricare i dati. Creeremo una directory per i backup - ricorda, dobbiamo scaricare l'intero set di backup - partendo da un backup completo fino all'ultimo incrementale che vogliamo applicare.
example@sqldat.com:~# mkdir backups
example@sqldat.com:~# cd backups/Ora ci sono due opzioni. Possiamo scaricare i backup uno per uno:
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-1/ BACKUP-1 --recursive
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
Completed 30.4 MiB/36.2 MiB (4.9 MiB/s) with 1 file(s) remaining
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-2/ BACKUP-2 --recursive
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256Possiamo anche, soprattutto se hai un programma di rotazione serrato, sincronizzare tutti i contenuti del bucket con ciò che abbiamo localmente sul server:
example@sqldat.com:~/backups# ~/.local/bin/aws s3 sync s3://drbackup/ .
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-4/cmon_backup.metadata to BACKUP-4/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/cmon_backup.metadata to BACKUP-3/cmon_backup.metadata
download: s3://drbackup/BACKUP-6/cmon_backup.metadata to BACKUP-6/cmon_backup.metadata
download: s3://drbackup/BACKUP-5/cmon_backup.metadata to BACKUP-5/cmon_backup.metadata
download: s3://drbackup/BACKUP-7/cmon_backup.metadata to BACKUP-7/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 to BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256
download: s3://drbackup/BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256 to BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256 to BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256 to BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256 to BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256Come ricordi, i backup sono crittografati. È necessario disporre di una chiave di crittografia archiviata in ClusterControl. Assicurati di avere la sua copia archiviata in un luogo sicuro, al di fuori del datacenter principale. Se non riesci a raggiungerlo, non sarai in grado di decrittografare i backup. La chiave si trova nella configurazione di ClusterControl:
example@sqldat.com:~# grep backup_encryption_key /etc/cmon.d/cmon_1.cnf
backup_encryption_key='aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM='È codificato utilizzando base64, quindi dobbiamo prima decodificarlo e archiviarlo nel file prima di poter iniziare a decifrare il backup:
eco "aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM=" | openssl enc -base64 -d> passa
Ora possiamo riutilizzare questo file per decrittografare i backup. Per ora, diciamo che faremo un backup completo e due incrementali.
mkdir 1
mkdir 2
mkdir 3
cat BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/1/
cat BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/2/
cat BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/3/Abbiamo i dati decrittografati, ora dobbiamo procedere con la configurazione del nostro server MySQL. Idealmente, questa dovrebbe essere esattamente la stessa versione dei sistemi di produzione. Useremo Percona Server per MySQL:
cd ~
wget https://repo.percona.com/apt/percona-release_latest.generic_all.deb
sudo dpkg -i percona-release_latest.generic_all.deb
apt-get update
apt-get install percona-server-5.7Niente di complesso, solo installazione regolare. Una volta che è attivo e pronto, dobbiamo fermarlo e rimuovere il contenuto della sua directory di dati.
service mysql stop
rm -rf /var/lib/mysql/*Per ripristinare il backup avremo bisogno di Xtrabackup:uno strumento utilizzato da CC per crearlo (almeno per Perona e Oracle MySQL, MariaDB utilizza MariaBackup). È importante che questo strumento sia installato nella stessa versione dei server di produzione:
apt install percona-xtrabackup-24Questo è tutto ciò che dobbiamo preparare. Ora possiamo iniziare a ripristinare il backup. Con i backup incrementali è importante tenere presente che è necessario prepararli e applicarli in aggiunta al backup di base. Anche il backup di base deve essere preparato. È fondamentale eseguire la preparazione con l'opzione "--apply-log-only" per impedire a xtrabackup di eseguire la fase di rollback. Altrimenti non potrai applicare il prossimo backup incrementale.
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/ --incremental-dir=/root/backups/2/
xtrabackup --prepare --target-dir=/root/backups/1/ --incremental-dir=/root/backups/3/Nell'ultimo comando abbiamo consentito a xtrabackup di eseguire il rollback delle transazioni non completate:in seguito non verranno applicati altri backup incrementali. Ora è il momento di popolare la directory dei dati con il backup, avviare MySQL e vedere se tutto funziona come previsto:
example@sqldat.com:~/backups# mv /root/backups/1/* /var/lib/mysql/
example@sqldat.com:~/backups# chown -R mysql.mysql /var/lib/mysql
example@sqldat.com:~/backups# service mysql start
example@sqldat.com:~/backups# mysql -ppass
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6
Server version: 5.7.26-29 Percona Server (GPL), Release '29', Revision '11ad961'
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show schemas;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| proxydemo |
| sbtest |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> select count(*) from sbtest.sbtest1;
+----------+
| count(*) |
+----------+
| 10506 |
+----------+
1 row in set (0.01 sec)Come puoi vedere, va tutto bene. MySQL è stato avviato correttamente e siamo stati in grado di accedervi (e i dati sono lì!). Siamo riusciti a riportare il nostro database attivo e funzionante in una posizione separata. Il tempo totale richiesto dipende strettamente dalla dimensione dei dati:abbiamo dovuto scaricare i dati da S3, decrittografarli e decomprimerli e infine preparare il backup. Tuttavia, questa è un'opzione molto economica (devi pagare solo per i dati S3) che ti offre un'opzione per la continuità aziendale in caso di disastro.