L'elevata disponibilità è un'elevata percentuale di tempo in cui il sistema funziona e risponde in base alle esigenze aziendali. Per i sistemi di database di produzione è in genere la massima priorità mantenerlo vicino al 100%. Costruiamo cluster di database per eliminare tutti i singoli punti di errore. Se un'istanza diventa non disponibile, un altro nodo dovrebbe essere in grado di sostenere il carico di lavoro e continuare da lì. In un mondo perfetto, un cluster di database risolverebbe tutti i nostri problemi di disponibilità del sistema. Sfortunatamente, mentre tutto può sembrare buono sulla carta, la realtà è spesso diversa. Allora dove può andare storto?
I sistemi di database transazionali sono dotati di sofisticati motori di archiviazione. Mantenere i dati coerenti su più nodi rende questo compito molto più difficile. Il clustering introduce una serie di nuove variabili che dipendono fortemente dalla rete e dall'infrastruttura sottostante. Non è raro che un'istanza di database standalone che funzionava correttamente su un singolo nodo abbia improvvisamente prestazioni scadenti in un ambiente cluster.
Tra le numerose cose che possono influenzare la disponibilità del cluster, i problemi di latenza svolgono un ruolo cruciale. Tuttavia, qual è la latenza? È legato solo alla rete?
Il termine "latenza" si riferisce in realtà a diversi tipi di ritardi subiti nell'elaborazione dei dati. È il tempo impiegato da un'informazione per passare da una fase all'altra.
In questo post del blog, esamineremo le due principali soluzioni ad alta disponibilità per MySQL e MariaDB e come ciascuna di esse può essere influenzata da problemi di latenza.
Alla fine dell'articolo, diamo un'occhiata ai moderni sistemi di bilanciamento del carico e discutiamo di come possono aiutarti a risolvere alcuni tipi di problemi di latenza.
In un articolo precedente, il mio collega Krzysztof Książek ha scritto di "Trattare con reti inaffidabili quando si crea una soluzione HA per MySQL o MariaDB". Troverai suggerimenti che possono aiutarti a progettare la tua architettura HA pronta per la produzione ed evitare alcuni dei problemi descritti qui.
Replica master-slave per alta disponibilità.
La replica master-slave MySQL è probabilmente il tipo di cluster di database più popolare al mondo. Una delle cose principali che si desidera monitorare durante l'esecuzione del cluster di replica master-slave è lo slave lag. A seconda dei requisiti dell'applicazione e del modo in cui utilizzi il database, la latenza di replica (slave lag) può determinare se i dati possono essere letti o meno dal nodo slave. I dati confermati sul master ma non ancora disponibili su uno slave asincrono indicano che lo slave ha uno stato precedente. Quando non è possibile leggere da uno slave, è necessario passare al master e ciò può influire sulle prestazioni dell'applicazione. Nella peggiore delle ipotesi, il tuo sistema non sarà in grado di gestire tutto il carico di lavoro su un master.
Slave lag e dati non aggiornati
Per controllare lo stato della replica master-slave, dovresti iniziare con il comando seguente:
SHOW SLAVE STATUS\G
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.3.100
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 5101
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 809
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5101
Relay_Log_Space: 1101
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-1179
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.01 sec)Utilizzando le informazioni di cui sopra è possibile determinare quanto è buona la latenza di replica complessiva. Minore è il valore che vedi in "Seconds_Behind_Master", migliore è la velocità di trasferimento dei dati per la replica.
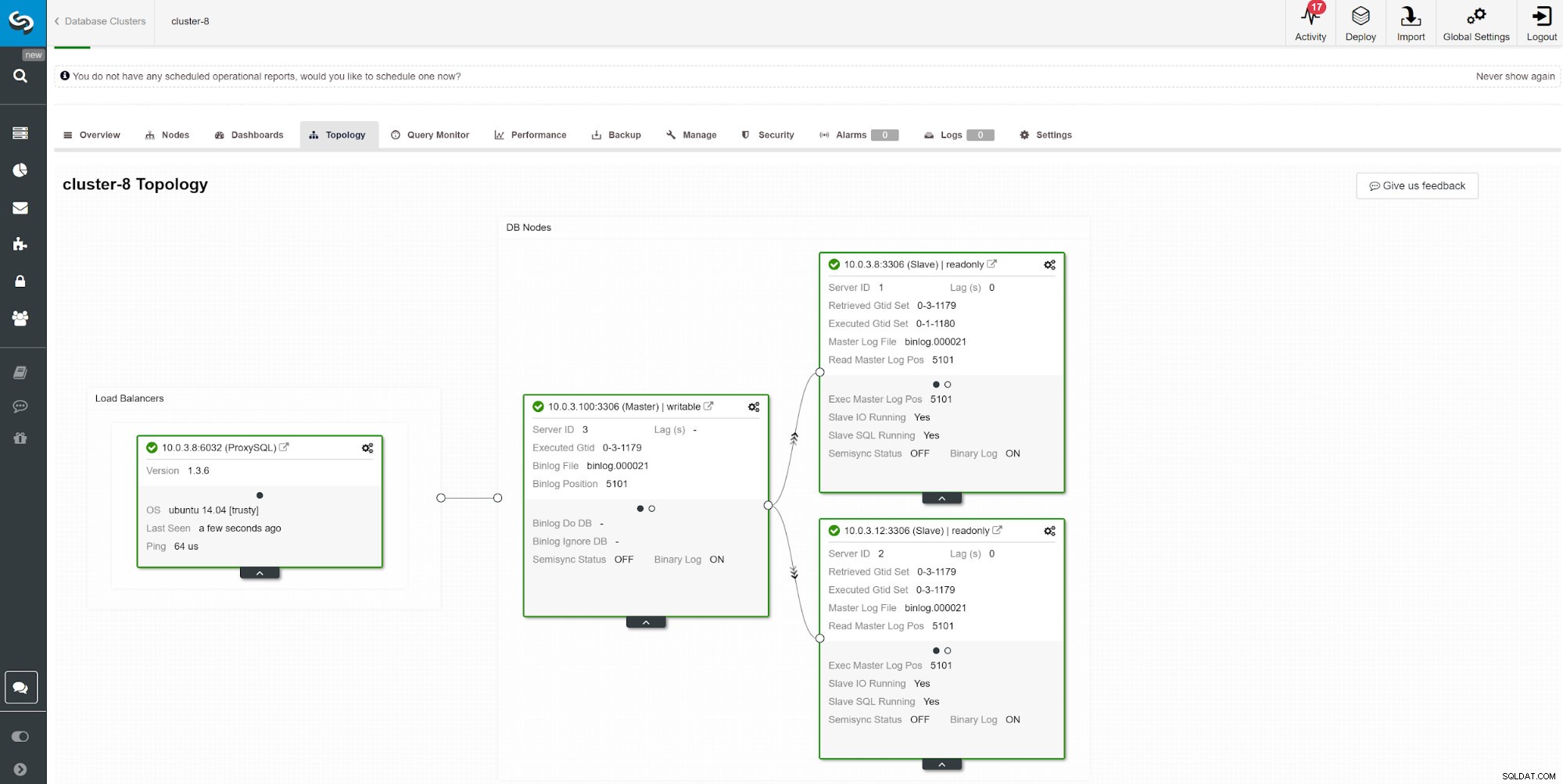 Un altro modo per monitorare lo slave lag consiste nell'utilizzare il monitoraggio della replica ClusterControl. In questo screenshot possiamo vedere lo stato di replica del Cluster Master-Slave (2x) asincrono con ProxySQL.
Un altro modo per monitorare lo slave lag consiste nell'utilizzare il monitoraggio della replica ClusterControl. In questo screenshot possiamo vedere lo stato di replica del Cluster Master-Slave (2x) asincrono con ProxySQL. Ci sono un certo numero di cose che possono influenzare il tempo di replica. Il più ovvio è il throughput della rete e la quantità di dati che puoi trasferire. MySQL viene fornito con più opzioni di configurazione per ottimizzare il processo di replica. I parametri essenziali relativi alla replica sono:
- Applicazione parallela
- Algoritmo dell'orologio logico
- Compressione
- Replica selettiva master-slave
- Modalità di replica
Applicazione parallela
Non è raro avviare l'ottimizzazione della replica con l'abilitazione dell'applicazione del processo parallelo. Il motivo è che per impostazione predefinita MySQL utilizza l'applicazione del log binario sequenziale e un tipico server di database viene fornito con diverse CPU da utilizzare.
Per aggirare l'applicazione del log sequenziale, sia MariaDB che MySQL offrono la replica parallela. L'implementazione può variare in base al fornitore e alla versione. Per esempio. MySQL 5.6 offre la replica parallela purché uno schema separi le query mentre MariaDB (a partire dalla versione 10.0) e MySQL 5.7 possono entrambi gestire la replica parallela tra schemi. Diversi fornitori e versioni sono dotati di limitazioni e funzionalità, quindi controlla sempre la documentazione.
L'esecuzione di query tramite thread slave paralleli può accelerare il flusso di replica se la scrittura è pesante. Tuttavia, in caso contrario, sarebbe meglio attenersi alla tradizionale replica a thread singolo. Per abilitare l'elaborazione parallela, modificare slave_parallel_workers con il numero di thread della CPU che si desidera coinvolgere nel processo. Si consiglia di mantenere il valore inferiore al numero di thread CPU disponibili.
La replica parallela funziona meglio con i commit di gruppo. Per verificare se si verificano commit di gruppo, esegui la seguente query.
show global status like 'binlog_%commits';Maggiore è il rapporto tra questi due valori, meglio è.
Orologio logico
slave_parallel_type=LOGICAL_CLOCK è un'implementazione di un algoritmo di clock di Lamport. Quando si utilizza uno slave multithread, questa variabile specifica il metodo utilizzato per decidere quali transazioni possono essere eseguite in parallelo sullo slave. La variabile non ha effetto sugli slave per i quali il multithreading non è abilitato, quindi assicurati che slave_parallel_workers sia impostato su un valore maggiore di 0.
Gli utenti di MariaDB dovrebbero anche controllare la modalità ottimistica introdotta nella versione 10.1.3 in quanto potrebbe anche darti risultati migliori.
GTID
MariaDB viene fornito con la propria implementazione di GTID. La sequenza di MariaDB consiste in un dominio, un server e una transazione. I domini consentono la replica multi-sorgente con ID distinto. È possibile utilizzare ID di dominio diversi per replicare la parte di dati fuori servizio (in parallelo). Se va bene per la tua applicazione, questo può ridurre la latenza di replica.
La tecnica simile si applica a MySQL 5.7 che può anche utilizzare il master multisorgente ei canali di replica indipendenti.
Compressione
La potenza della CPU sta diventando meno costosa nel tempo, quindi utilizzarla per la compressione binlog potrebbe essere una buona opzione per molti ambienti di database. Il parametro slave_compressed_protocol dice a MySQL di usare la compressione se sia master che slave la supportano. Per impostazione predefinita, questo parametro è disabilitato.
A partire da MariaDB 10.2.3, gli eventi selezionati nel log binario possono essere opzionalmente compressi, per salvare i trasferimenti di rete.
Formati di replica
MySQL offre diverse modalità di replica. La scelta del formato di replica corretto aiuta a ridurre al minimo il tempo di passaggio dei dati tra i nodi del cluster.
Replica multimaster per un'elevata disponibilità
Alcune applicazioni non possono permettersi di operare su dati obsoleti.
In questi casi, potresti voler imporre la coerenza tra i nodi con la replica sincrona. Mantenere i dati sincroni richiede un plug-in aggiuntivo e, per alcuni, la migliore soluzione sul mercato per questo è Galera Cluster.
Il cluster Galera viene fornito con l'API wsrep che è responsabile della trasmissione delle transazioni a tutti i nodi e dell'esecuzione in base a un ordinamento a livello di cluster. Ciò bloccherà l'esecuzione delle query successive finché il nodo non avrà applicato tutti i set di scritture dalla coda dell'applicatore. Sebbene sia una buona soluzione per coerenza, potresti incontrare alcune limitazioni architettoniche. I problemi di latenza comuni possono essere correlati a:
- Il nodo più lento del cluster
- Operazioni di ridimensionamento orizzontale e scrittura
- Ammassi geolocalizzati
- Ping alto
- Dimensione della transazione
Il nodo più lento del cluster
In base alla progettazione, le prestazioni di scrittura del cluster non possono essere superiori alle prestazioni del nodo più lento del cluster. Inizia la revisione del cluster controllando le risorse della macchina e verifica i file di configurazione per assicurarti che vengano eseguiti tutti con le stesse impostazioni di prestazioni.
Parallelizzazione
I thread paralleli non garantiscono prestazioni migliori, ma possono velocizzare la sincronizzazione di nuovi nodi con il cluster. Lo stato wsrep_cert_deps_distance ci dice il possibile grado di parallelizzazione. E' il valore della distanza media tra i valori seqno più alti e più bassi che possono essere eventualmente applicati in parallelo. Puoi utilizzare la variabile di stato wsrep_cert_deps_distance per determinare il numero massimo di thread slave possibili.
Ridimensionamento orizzontale
Aggiungendo più nodi nel cluster, abbiamo meno punti che potrebbero non riuscire; tuttavia, le informazioni devono passare attraverso più istanze fino a quando non vengono impegnate, il che moltiplica i tempi di risposta. Se hai bisogno di scritture scalabili, considera un'architettura basata sullo sharding. Una buona soluzione può essere un motore di archiviazione Spider.
In alcuni casi, per ridurre le informazioni condivise tra i nodi del cluster, puoi considerare di avere un writer alla volta. È relativamente facile da implementare durante l'utilizzo di un sistema di bilanciamento del carico. Quando lo fai manualmente, assicurati di avere una procedura per modificare il valore DNS quando il tuo nodo di scrittura si interrompe.
Ammassi geolocalizzati
Sebbene Galera Cluster sia sincrono, è possibile distribuire un Galera Cluster tra i data center. La replica sincrona come MySQL Cluster (NDB) implementa un commit a due fasi, in cui i messaggi vengono inviati a tutti i nodi in un cluster in una fase di "preparazione" e un altro insieme di messaggi viene inviato in una fase di "commit". Questo approccio di solito non è adatto a nodi geograficamente disparati, a causa delle latenze nell'invio di messaggi tra nodi.
Ping alto
Galera Cluster con le impostazioni predefinite non gestisce una latenza di rete molto elevata. Se disponi di una rete con un nodo che mostra un tempo di ping elevato, valuta la possibilità di modificare i parametri evs.send_window ed evs.user_send_window. Queste variabili definiscono il numero massimo di pacchetti di dati in replica alla volta. Per le configurazioni WAN, la variabile può essere impostata su un valore considerevolmente superiore al valore predefinito di 2. È comune impostarla su 512. Questi parametri fanno parte di wsrep_provider_options.
--wsrep_provider_options="evs.send_window=512;evs.user_send_window=512"Dimensione della transazione
Una delle cose che devi considerare durante l'esecuzione di Galera Cluster è la dimensione della transazione. Trovare l'equilibrio tra la dimensione della transazione, le prestazioni e il processo di certificazione Galera è qualcosa che devi stimare nella tua domanda. Puoi trovare maggiori informazioni a riguardo nell'articolo Come migliorare le prestazioni di Galera Cluster per MySQL o MariaDB di Ashraf Sharif.
Lettura della coerenza causale del bilanciamento del carico
Anche con il rischio minimo di problemi di latenza dei dati, la replica asincrona MySQL standard non può garantire la coerenza. È ancora possibile che i dati non siano ancora replicati su slave mentre l'applicazione li sta leggendo da lì. La replica sincrona può risolvere questo problema, ma presenta limitazioni dell'architettura e potrebbe non soddisfare i requisiti dell'applicazione (ad esempio, scritture di massa intensive). Allora come superarlo?
Il primo passaggio per evitare la lettura di dati obsoleti consiste nel rendere l'applicazione consapevole del ritardo di replica. Di solito è programmato nel codice dell'applicazione. Fortunatamente, esistono moderni sistemi di bilanciamento del carico del database con il supporto dell'instradamento adattivo delle query basato sul tracciamento GTID. I più popolari sono ProxySQL e Maxscale.
ProxySQL 2.0
ProxySQL Binlog Reader consente a ProxySQL di sapere in tempo reale quale GTID è stato eseguito su ogni server MySQL, slave e master stesso. Grazie a ciò, quando un client esegue una lettura che deve fornire letture di coerenza causale, ProxySQL sa immediatamente su quale server può essere eseguita la query. Se per qualsiasi motivo le scritture non sono state ancora eseguite su nessuno slave, ProxySQL saprà che lo scrittore è stato eseguito su master e invierà la lettura lì.
Scala massima 2,3
MariaDB ha introdotto letture casuali in Maxscale 2.3.0. Il modo in cui funziona è simile a ProxySQL 2.0. Fondamentalmente, quando le letture causali sono abilitate, tutte le letture successive eseguite sui server slave verranno eseguite in modo da evitare che il ritardo di replica influisca sui risultati. Se lo slave non ha raggiunto il master entro il tempo configurato, la richiesta verrà ripetuta sul master.