La replica master-slave MySQL è abbastanza facile e semplice da configurare. Questo è il motivo principale per cui le persone scelgono questa tecnologia come primo passo per ottenere una migliore disponibilità del database. Tuttavia, ha il prezzo della complessità nella gestione e nella manutenzione; spetta all'amministratore mantenere l'integrità dei dati, in particolare durante il failover, il failback, la manutenzione, l'aggiornamento e così via.
Sono disponibili molti articoli che descrivono come eseguire l'operazione di failover per l'impostazione della replica. Abbiamo anche trattato questo argomento in questo post del blog, Introduzione al failover per la replica di MySQL - il blog 101. In questo post del blog tratteremo le attività successive al disastro durante il ripristino della topologia originale, ovvero l'esecuzione dell'operazione di failback.
Perché abbiamo bisogno di un failback?
Il leader della replica (master) è il nodo più critico in una configurazione di replica. Richiede buone specifiche hardware per garantire che possa elaborare scritture, generare eventi di replica, elaborare letture critiche e così via in modo stabile. Quando è necessario il failover durante il ripristino di emergenza o la manutenzione, potrebbe non essere raro trovarci a promuovere un nuovo leader con hardware di qualità inferiore. Questa situazione potrebbe andare temporaneamente bene, tuttavia, per un lungo periodo, il master designato deve essere riportato per guidare la replica dopo che è stato ritenuto integro.
Contrariamente al failover, l'operazione di failback di solito avviene in un ambiente controllato tramite il passaggio, ma raramente si verifica in modalità panico. Questo dà al team operativo un po' di tempo per pianificare attentamente e provare l'esercizio per una transizione graduale. L'obiettivo principale è semplicemente riportare il buon vecchio master allo stato più recente e ripristinare la configurazione della replica alla sua topologia originale. Tuttavia, ci sono alcuni casi in cui il failback è fondamentale, ad esempio quando il master appena promosso non ha funzionato come previsto e ha influito sull'intero servizio di database.
Come eseguire il failback in modo sicuro?
Dopo il failover, il vecchio master sarebbe fuori dalla catena di replica per manutenzione o ripristino. Per eseguire il passaggio, è necessario effettuare le seguenti operazioni:
- Riporta il vecchio padrone allo stato corretto, rendendolo lo schiavo più aggiornato.
- Interrompi l'applicazione.
- Verifica che tutti gli schiavi siano stati raggiunti.
- Promuovi il vecchio maestro come nuovo leader.
- Reindirizza tutti gli slave al nuovo master.
- Avvia l'applicazione scrivendo al nuovo master.
Considera la seguente configurazione di replica:
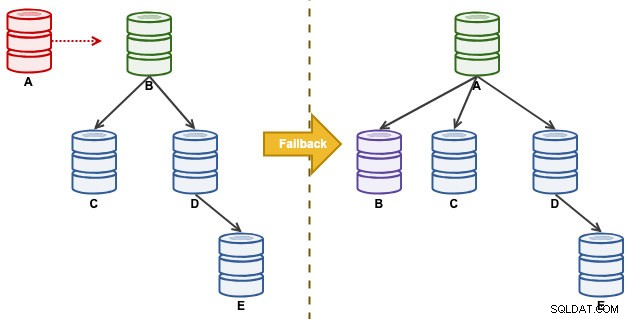
"A" era un master fino a quando un evento di disco pieno ha causato il caos nella catena di replica. Dopo un evento di failover, la nostra topologia di replica è stata guidata da B e si replica su C fino a E. L'esercizio di failback riporterà A come leader e ripristinerà la topologia originale prima del disastro. Tieni presente che tutti i nodi sono in esecuzione su MySQL 8.0.15 con GTID abilitato. Diverse versioni principali potrebbero utilizzare comandi e passaggi diversi.
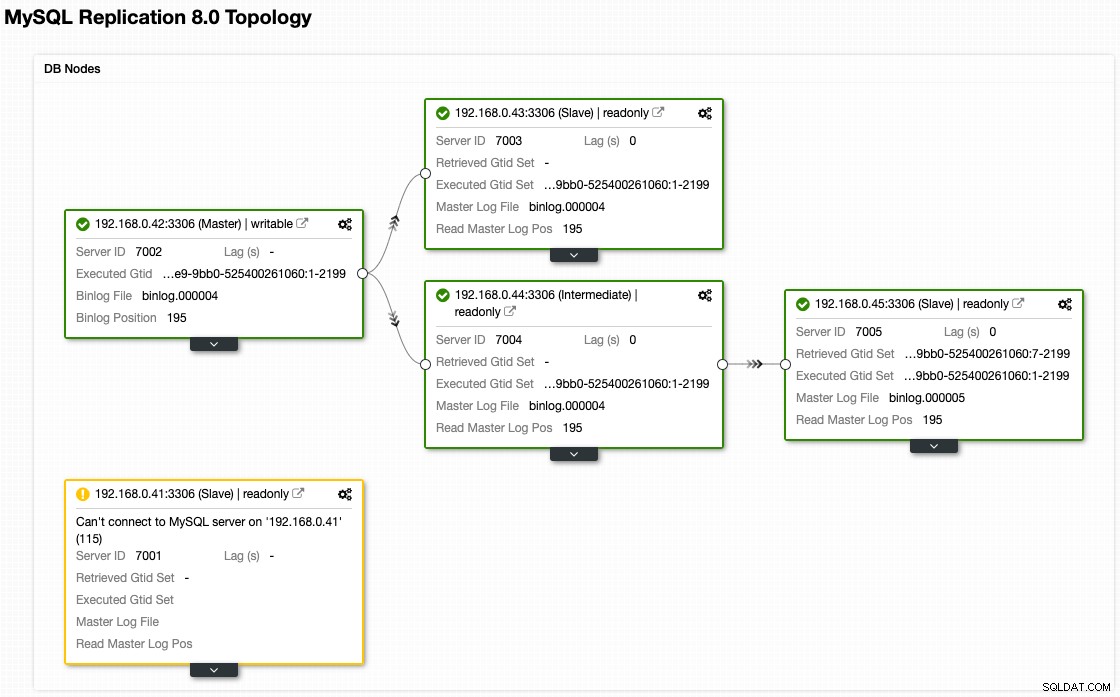
Anche se questo è l'aspetto della nostra architettura ora dopo il failover (tratto dalla vista Topologia di ClusterControl):
Provisioning del nodo
Prima che A possa essere un master, deve essere aggiornato con lo stato corrente del database. Il modo migliore per farlo è trasformare A come slave del master attivo, B. Poiché tutti i nodi sono configurati con log_slave_updates=ON (significa che uno slave produce anche log binari), possiamo effettivamente selezionare altri slave come C e D come la fonte di verità per la sincronizzazione iniziale. Tuttavia, più vicino al master attivo, meglio è. Tieni presente il carico aggiuntivo che potrebbe causare durante l'esecuzione del backup. Questa parte richiede la maggior parte delle ore di failback. A seconda dello stato del nodo e delle dimensioni del set di dati, la sincronizzazione del vecchio master potrebbe richiedere del tempo (potrebbero essere ore e giorni).
Una volta che il problema su "A" è stato risolto e pronto per entrare nella catena di replica, il primo passo migliore è provare a replicare da "B" (192.168.0.42) con l'istruzione CHANGE MASTER:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Se la replica funziona, dovresti vedere quanto segue nello stato della replica:
Slave_IO_Running: Yes
Slave_SQL_Running: YesSe la replica ha esito negativo, esaminare Last_IO_Error o Last_SQL_Error dall'output dello stato slave. Ad esempio, se viene visualizzato il seguente errore:
Last_IO_Error: error connecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 2Quindi, dobbiamo creare l'utente di replica sul master attivo corrente, B:
mysql> CREATE USER example@sqldat.com IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com;Quindi, riavvia lo slave su A per ricominciare a replicare:
mysql> STOP SLAVE;
mysql> START SLAVE;Un altro errore comune che vedresti è questa riga:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...Ciò probabilmente significa che lo slave ha problemi a leggere il file di registro binario dal master corrente. In alcune occasioni, lo slave potrebbe essere molto indietro rispetto al fatto che gli eventi binari richiesti per avviare la replica sono mancati dal master corrente, oppure il binario sul master è stato eliminato durante il failover e così via. In questo caso, il modo migliore è eseguire una sincronizzazione completa eseguendo un backup completo su B e ripristinandolo su A. Su B, puoi utilizzare mysqldump o Percona Xtrabackup per eseguire un backup completo:
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupTrasferisci il file di backup in A, reinizializza l'installazione MySQL esistente per una corretta pulizia ed esegui il ripristino del database:
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER example@sqldat.com IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root passwordUna volta ripristinato, impostare il collegamento di replica al master attivo B (192.168.0.42) e abilitare la sola lettura. Su A, esegui le seguenti istruzioni:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Per Percona Xtrabackup, fare riferimento alla pagina della documentazione su come ripristinare in A. Si tratta di un passaggio prerequisito per preparare il backup prima di sostituire la directory dei dati MySQL.
Una volta che A ha iniziato a replicare correttamente, monitorare Seconds_Behind_Master nello stato slave. Questo ti darà un'idea di quanto lontano ha lasciato lo schiavo e quanto tempo devi aspettare prima che raggiunga. A questo punto, la nostra architettura si presenta così:
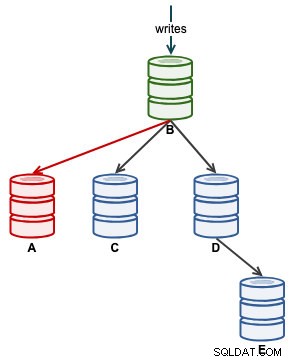
Una volta che Seconds_Behind_Master torna a 0, è il momento in cui A è diventato uno schiavo aggiornato.
Se stai utilizzando ClusterControl, hai la possibilità di risincronizzare il nodo eseguendo il ripristino da un backup esistente o creare e trasmettere il backup direttamente dal nodo master attivo:
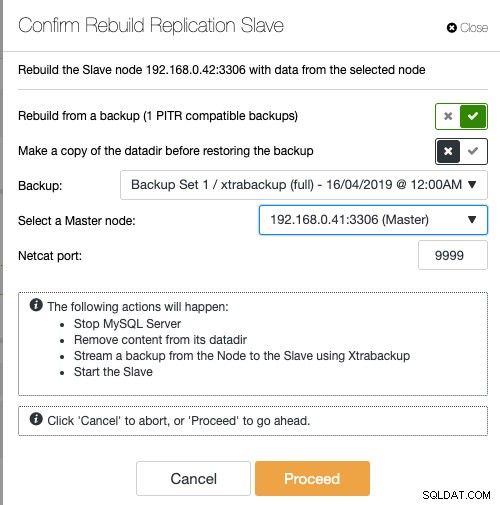
Lo staging dello slave con il backup esistente è il modo consigliato da fare per costruire lo slave, poiché non ha alcun impatto sul server master attivo durante la preparazione del nodo.
Promuove l'Antico Maestro
Prima di promuovere A come nuovo master, il modo più sicuro è interrompere tutte le operazioni di scrittura su B. Se ciò non è possibile, forza semplicemente B ad operare in modalità di sola lettura:
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';Quindi, su A, esegui SHOW SLAVE STATUS e controlla il seguente stato di replica:
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesIl valore di Read_Master_Log_Pos e Exec_Master_Log_Pos deve essere identico, mentre Seconds_Behind_Master è 0 e lo stato deve essere 'Slave ha letto tutto il registro dei relè'. Assicurati che tutti gli slave abbiano elaborato qualsiasi istruzione nel loro registro di inoltro, altrimenti rischierai che le nuove query influiscano sulle transazioni del registro di inoltro, innescando ogni tipo di problema (ad esempio, un'applicazione potrebbe rimuovere alcune righe a cui accedono le transazioni dal registro di inoltro).
In A, interrompere la replica e utilizzare l'istruzione RESET SLAVE ALL per rimuovere tutta la configurazione relativa alla replica e disabilitare la sola lettura:
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';A questo punto A è pronto per accettare scritture (sola_lettura=OFF), tuttavia gli slave non sono collegati ad esso, come illustrato di seguito:
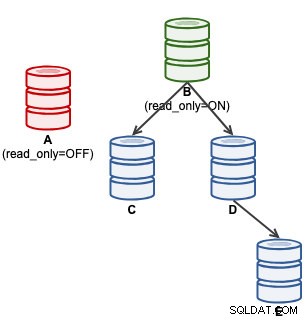
Per gli utenti ClusterControl, la promozione di A può essere eseguita utilizzando la funzione "Promuovi slave" in Azioni nodo. ClusterControl retrocederà automaticamente il master attivo B, promuoverà lo slave A come master e repoint C e D per replicare da A. B verrà messo da parte e l'utente dovrà scegliere esplicitamente "Change Replication Master" per ricongiungersi a B replicando da A in una fase successiva .
Reindirizzamento slave
È ora possibile modificare il master sugli slave correlati per replicare da A (192.168.0.41). Su tutti gli slave tranne E, configurare quanto segue:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Se sei un utente ClusterControl, puoi saltare questo passaggio poiché il repointing viene eseguito automaticamente quando hai deciso di promuovere A in precedenza.
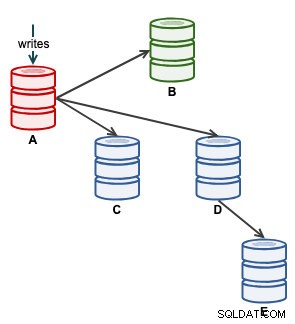
Possiamo quindi avviare la nostra applicazione per scrivere su A. A questo punto, la nostra architettura è simile a questa:
Dalla visualizzazione della topologia ClusterControl, abbiamo ripristinato il nostro cluster di replica alla sua architettura originale che assomiglia a questa:
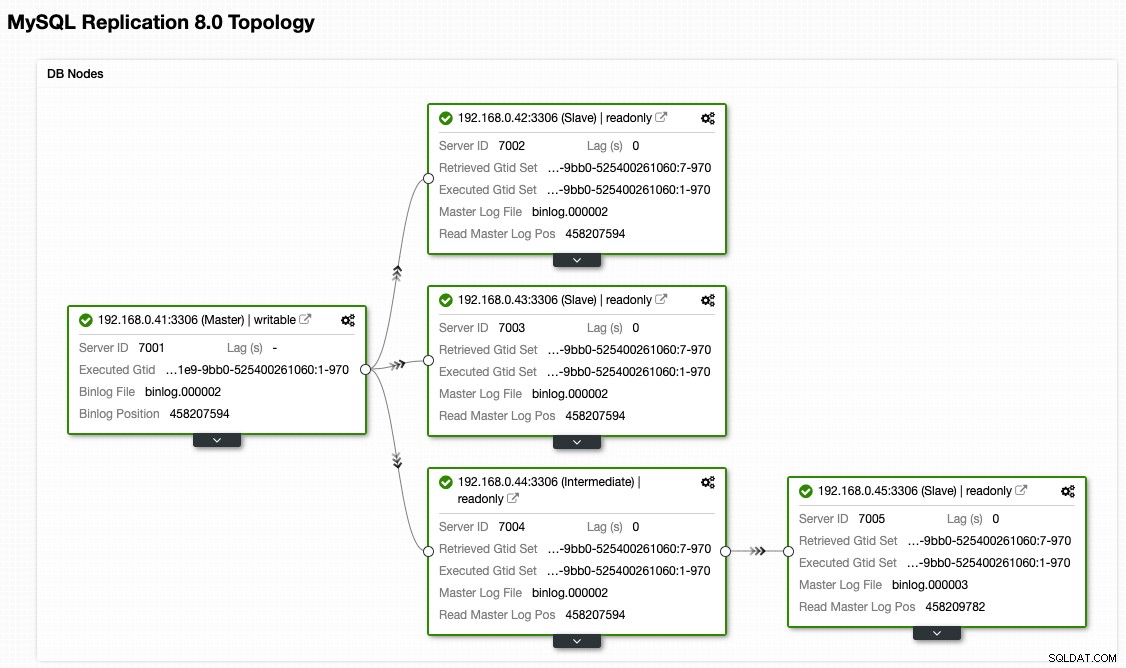
Tieni presente che l'esercizio di failback è molto meno rischioso rispetto al failover. È importante programmare questo esercizio durante le ore non di punta per ridurre al minimo l'impatto sulla tua attività.
Pensieri finali
Le operazioni di failover e failback devono essere eseguite con attenzione. L'operazione è abbastanza semplice se si dispone di un numero ridotto di nodi, ma per più nodi con una catena di replica complessa, potrebbe essere un esercizio rischioso e soggetto a errori. Abbiamo anche mostrato come è possibile utilizzare ClusterControl per semplificare operazioni complesse eseguendole tramite l'interfaccia utente, inoltre la visualizzazione della topologia viene visualizzata in tempo reale in modo da avere la comprensione della topologia di replica che si desidera creare.