Introduzione
Uno Spool di indici desiderosi legge tutte le righe dall'operatore figlio in una tabella di lavoro indicizzata, prima di iniziare a restituire le righe all'operatore padre. Per alcuni aspetti, uno spool di indice desideroso è l'ultimo suggerimento di indice mancante , ma non viene segnalato come tale.
Valutazione dei costi
L'inserimento di righe in un tavolo di lavoro indicizzato è relativamente economico, ma non gratuito. L'ottimizzatore deve considerare che il lavoro coinvolto consente di risparmiare più di quanto non costi. Affinché ciò funzioni a favore della bobina, è necessario stimare che il piano consumi righe dalla bobina più di una volta. Altrimenti, potrebbe anche saltare lo spool ed eseguire l'operazione sottostante quella volta.
- Per essere accessibile più di una volta, lo spool deve apparire sul lato interno di un operatore di join di loop nidificato.
- Ogni iterazione del ciclo dovrebbe cercare un valore di chiave di spooling dell'indice particolare fornito dal lato esterno del ciclo.
Ciò significa che il join deve essere un applica , non un unire a loop nidificati . Per la differenza tra i due, consulta il mio articolo Applicare contro i cicli nidificati Unisciti.
Caratteristiche degne di nota
Mentre uno spool indice desideroso può apparire solo sul lato interno di un loop nidificato applica , non è una "bobina di prestazioni". Uno spool di indice desideroso non può essere disabilitato con il flag di traccia 8690 o NO_PERFORMANCE_SPOOL suggerimento per la query.
Le righe inserite nello spool dell'indice non vengono normalmente preordinate in base all'ordine delle chiavi dell'indice, il che può causare la divisione della pagina dell'indice. Il flag di traccia non documentato 9260 può essere utilizzato per generare un Ordina operatore prima dello spool di indice per evitare ciò. Lo svantaggio è che il costo aggiuntivo di smistamento può dissuadere l'ottimizzatore dal scegliere l'opzione spool.
SQL Server non supporta gli inserimenti paralleli in un indice b-tree. Ciò significa che tutto ciò che si trova al di sotto di uno spool di indice desideroso parallelo viene eseguito su un singolo thread. Gli operatori sotto lo spool sono ancora (in modo fuorviante) contrassegnati dall'icona del parallelismo. Viene scelto un thread per scrivere alla bobina. Gli altri thread attendono EXECSYNC mentre ciò completa. Una volta che lo spool è popolato, può essere letto da da fili paralleli.
Gli spool di indice non dicono all'ottimizzatore che supportano l'output ordinato dalle chiavi di indice dello spool. Se è richiesto un output ordinato dallo spool, è possibile che venga visualizzato un Ordina non necessario operatore. Gli spool di indice desiderosi dovrebbero spesso essere comunque sostituiti da un indice permanente, quindi questa è una preoccupazione minore per la maggior parte del tempo.
Esistono cinque regole di ottimizzazione che possono generare uno Spool di indice desideroso opzione (conosciuta internamente come un indice al volo ). Ne esamineremo tre in dettaglio per capire da dove provengono gli spool di indici ansiosi.
SelToIndexOnTheFly
Questo è il più comune. Corrisponde a una o più selezioni relazionali (dette anche filtri o predicati) appena sopra un operatore di accesso ai dati. Il SelToIndexOnTheFly la regola sostituisce i predicati con un predicato di ricerca su uno spool di indice ansioso.
Demo
Un AdventureWorks esempio di database di esempio è mostrato di seguito:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%';
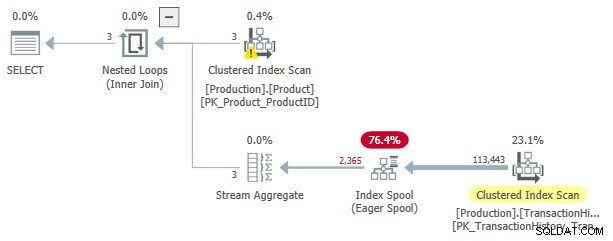
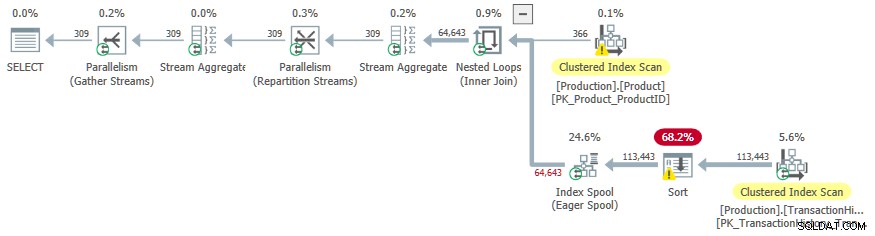
Questo piano di esecuzione ha un costo stimato di 3,0881 unità. Alcuni punti di interesse:
- Il Nesd Loops Inner Join operatore è un applica , con
ProductIDeSafetyStockLeveldalProducttabella come riferimenti esterni . - Nella prima iterazione dell'applicazione, Eager Index Spool è completamente popolato da Scansione indice cluster della
TransactionHistorytabella. - Il tavolo di lavoro dello spool ha un indice cluster digitato su
(ProductID, Quantity). - Righe corrispondenti ai predicati
TH.ProductID = P.ProductIDeTH.Quantity < P.SafetyStockLevelricevono una risposta dallo spool usando il suo indice. Questo vale per ogni iterazione dell'applicazione, inclusa la prima. - Il
TransactionHistoryla tabella viene scansionata solo una volta.
Input ordinato nello spool
È possibile applicare l'input ordinato allo spool dell'indice desideroso, ma ciò influisce sul costo stimato, come indicato nell'introduzione. Per l'esempio precedente, l'abilitazione del flag di traccia non documentato produce un piano senza uno spool:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%'
OPTION (QUERYTRACEON 9260);
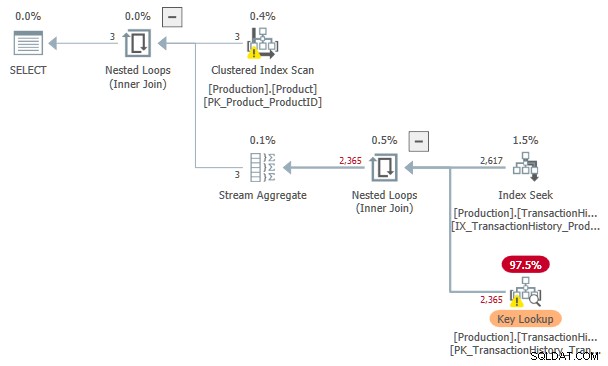
Il costo stimato di questa Ricerca dell'indice e Ricerca chiave il piano è 3.11631 unità. Questo è più del costo del piano con uno spool di indice da solo, ma inferiore al piano con uno spool di indice e input ordinato.
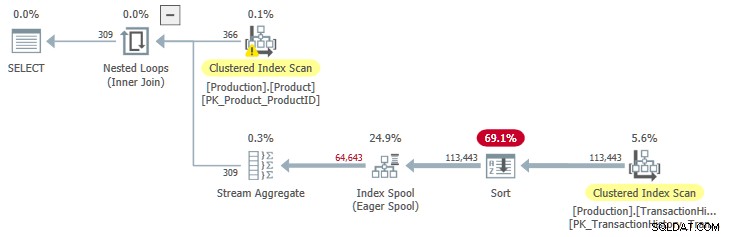
Per visualizzare un piano con input ordinato nello spool, è necessario aumentare il numero previsto di iterazioni del ciclo. Questo dà alla bobina la possibilità di rimborsare il costo aggiuntivo dell'Ordinamento . Un modo per espandere il numero di righe previste dal Product tabella è quello di creare il Name predicato meno restrittivo:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'[A-P]%'
OPTION (QUERYTRACEON 9260); Questo ci fornisce un piano di esecuzione con input ordinato nello spool:
Unisciti aIndexOnTheFly
Questa regola trasforma un inner join a una richiesta , con una bobina di indice ansioso sul lato interno. Almeno uno dei predicati di join deve essere una disuguaglianza affinché questa regola venga soddisfatta.
Questa è una regola molto più specializzata di SelToIndexOnTheFly , ma l'idea è più o meno la stessa. In questo caso, la selezione (predicato) che viene trasformata in una ricerca di spool indice è associata al join. La trasformazione da join a applica consente di spostare il predicato del join dal join stesso al lato interno dell'applicazione.
Demo
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN);
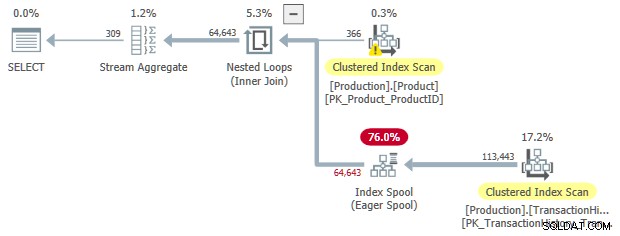
Come prima, possiamo richiedere un input ordinato allo spool:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN, QUERYTRACEON 9260);
Questa volta, il costo aggiuntivo dello smistamento ha incoraggiato l'ottimizzatore a scegliere un piano parallelo.
Un effetto collaterale indesiderato è l'Ordina l'operatore si riversa su tempdb . La concessione di memoria totale disponibile per l'ordinamento è sufficiente, ma è divisa equamente tra thread paralleli (come al solito). Come indicato nell'introduzione, SQL Server non supporta gli inserimenti paralleli in un indice b-tree, quindi gli operatori sotto lo spool dell'indice desideroso vengono eseguiti su un singolo thread. Questo singolo thread ottiene solo una frazione della concessione di memoria, quindi Ordina si riversa su tempdb .
Questo effetto collaterale è forse uno dei motivi per cui il flag di traccia non è documentato e non è supportato.
SelSTVFToIdxOnFly
Questa regola fa la stessa cosa di SelToIndexOnTheFly , ma per una funzione con valori di tabella di streaming (sTVF) sorgente di riga. Questi sTVF sono ampiamente utilizzati internamente per implementare DMV e DMF, tra le altre cose. Appaiono nei moderni piani di esecuzione come Funzione con valore di tabella operatori (originariamente come scansioni di tabelle remote ).
In passato, molti di questi sTVF non potevano accettare parametri correlati da una applicazione. Potrebbero accettare valori letterali, variabili e parametri di modulo, ma non applicare riferimenti esterni. Ci sono ancora avvisi al riguardo nella documentazione, ma ora sono in qualche modo obsoleti.
Ad ogni modo, il punto è che a volte non è possibile per SQL Server passare una applicazione riferimento esterno come parametro a un sTVF. In quella situazione, può avere senso materializzare parte del risultato sTVF in uno spool di indice ansioso. La presente regola fornisce tale capacità.
Demo
L'esempio di codice successivo mostra una query DMV convertita correttamente da un join a un applica . Riferimenti esterni vengono passati come parametri al secondo DMV:
-- Transformed to an apply
-- Outer reference passed as a parameter
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id = DES.session_id
OPTION (FORCE ORDER);
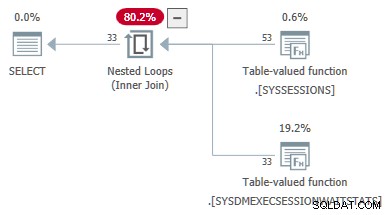
Le proprietà del piano delle statistiche di attesa TVF mostrano i parametri di input. Il secondo valore del parametro viene fornito come riferimento esterno dalle sessioni Motorizzazione:
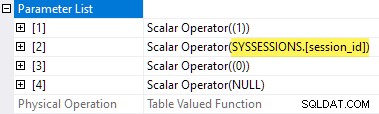
È un peccato che sys.dm_exec_session_wait_stats è una vista, non una funzione, perché ci impedisce di scrivere una richiesta direttamente.
La riscrittura di seguito è sufficiente per sconfiggere la conversione interna:
-- Rewrite to avoid TVF parameter trickery
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id >= DES.session_id
AND DESWS.session_id <= DES.session_id
OPTION (FORCE ORDER);
Con il session_id predicati ora non utilizzati come parametri, il SelSTVFToIdxOnFly la regola è libera di convertirli in uno spool di indice desideroso:
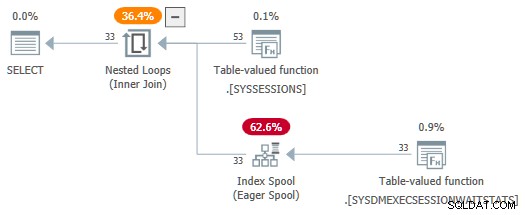
Non voglio lasciarti con l'impressione che siano necessarie riscritture complicate per ottenere uno spool di indice desideroso su una sorgente DMV:rende solo una demo più semplice. Se ti capita di incontrare una query con join DMV che produce un piano con uno spool ansioso, almeno sai come ci è arrivato.
Non puoi creare indici su DMV, quindi potrebbe essere necessario utilizzare un hash o unire join se il piano di esecuzione non funziona abbastanza bene.
CTE ricorsive
Le restanti due regole sono SelIterToIdxOnFly e JoinIterToIdxOnFly . Sono controparti dirette di SelToIndexOnTheFly e JoinToIndexOnTheFly per fonti di dati CTE ricorsive. Questi sono estremamente rari nella mia esperienza, quindi non fornirò demo per loro. (Proprio così l'Iter parte del nome della regola ha senso:deriva dal fatto che SQL Server implementa la ricorsione della coda come iterazione nidificata.)
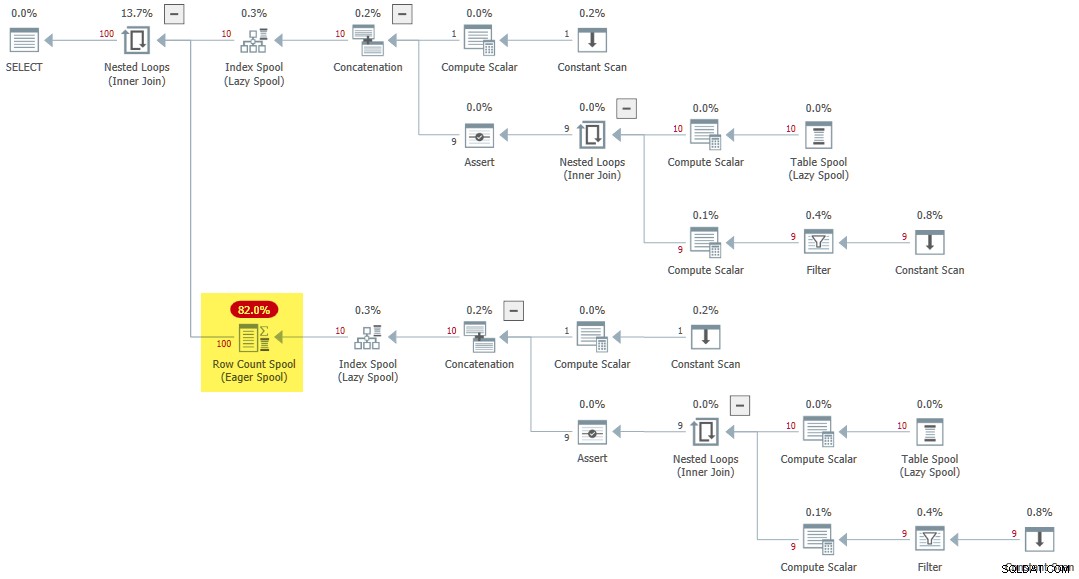
Quando un CTE ricorsivo viene referenziato più volte all'interno di un'applicazione, una regola diversa (SpoolOnIterator ) può memorizzare nella cache il risultato del CTE:
WITH R AS
(
SELECT 1 AS n
UNION ALL
SELECT R.n + 1
FROM R
WHERE R.n < 10
)
SELECT
R1.n
FROM R AS R1
CROSS JOIN R AS R2; Il piano di esecuzione prevede un raro Spool di conteggio delle righe desiderose :
Pensieri finali
Gli spool di indice desiderosi sono spesso un segno che nello schema del database manca un utile indice permanente. Questo non è sempre il caso, come mostrano gli esempi di funzioni con valori di tabella di streaming.



