Il motore di esecuzione delle query di SQL Server dispone di due modi per implementare un'operazione logica di "unione di tutti", utilizzando gli operatori fisici Concatenazione e Unisci join Concatenazione. Sebbene l'operazione logica sia la stessa, esistono differenze importanti tra i due operatori fisici che possono fare un'enorme differenza per l'efficienza dei piani di esecuzione.
Query Optimizer fa un lavoro ragionevole nella scelta tra le due opzioni in molti casi, ma in quest'area è molto lontano dall'essere perfetto. Questo articolo descrive le opportunità di ottimizzazione delle query presentate da Merge Join Concatenation e descrive in dettaglio i comportamenti interni e le considerazioni di cui devi essere a conoscenza per trarne il massimo.
Concatenazione

L'operatore di concatenazione è relativamente semplice:il suo output è il risultato della lettura completa di ciascuno dei suoi input in sequenza. L'operatore di concatenazione è un n-ary operatore fisico, il che significa che può avere '2...n' input. Per illustrare, rivisitiamo l'esempio basato su AdventureWorks del mio precedente articolo, "Riscrivere le query per migliorare le prestazioni":
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
La query seguente elenca gli ID prodotto e transazione per sei prodotti particolari:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
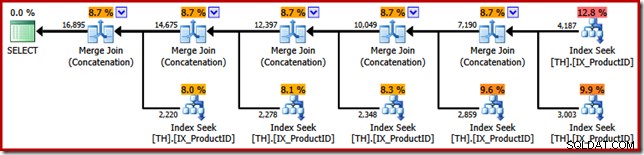
Produce un piano di esecuzione con un operatore di concatenazione con sei input, come mostrato in SQL Sentry Plan Explorer:
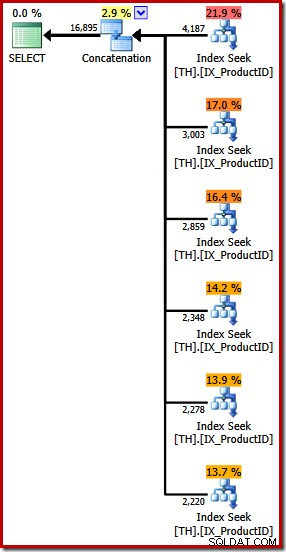
Il piano sopra prevede una ricerca dell'indice separata per ogni ID prodotto elencato, nello stesso ordine specificato nella query (lettura dall'alto verso il basso). L'indice di ricerca più in alto è per il prodotto 870, il successivo in basso è per il prodotto 873, quindi 921 e così via. Niente di tutto ciò è un comportamento garantito, ovviamente, è solo qualcosa di interessante da osservare.
Ho accennato in precedenza che l'operatore di concatenazione forma il suo output leggendo i suoi input in sequenza. Quando questo piano viene eseguito, ci sono buone probabilità che il set di risultati mostri prima le righe per il prodotto 870, poi 873, 921, 712, 707 e infine il prodotto 711. Anche in questo caso, questo non è garantito perché non abbiamo specificato un ORDINE BY, ma mostra come la concatenazione opera internamente.
Un "Piano di esecuzione" SSIS
Per ragioni che avranno senso tra un momento, considera come potremmo progettare un pacchetto SSIS per eseguire lo stesso compito. Potremmo certamente anche scrivere il tutto come una singola istruzione T-SQL in SSIS, ma l'opzione più interessante è creare un'origine dati separata per ogni prodotto e utilizzare un componente SSIS "Union All" al posto della concatenazione di SQL Server operatore:
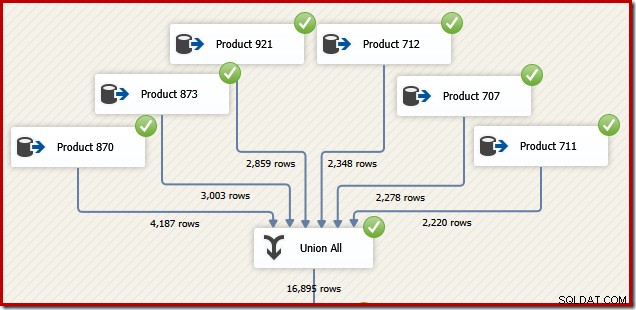
Ora immagina di aver bisogno dell'output finale di quel flusso di dati nell'ordine dell'ID transazione. Un'opzione potrebbe essere quella di aggiungere un componente di ordinamento esplicito dopo l'unione di tutti:
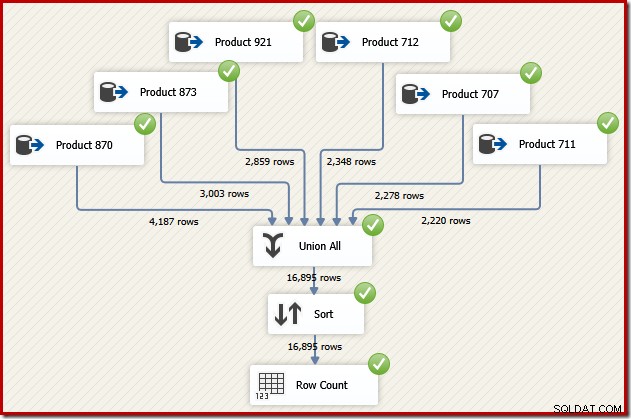
Ciò farebbe sicuramente il lavoro, ma un progettista SSIS esperto ed esperto si renderebbe conto che esiste un'opzione migliore:leggere i dati di origine per ciascun prodotto nell'ordine dell'ID transazione (utilizzando l'indice), quindi utilizzare un'operazione di conservazione dell'ordine per combinare i set .
In SSIS, il componente che combina le righe di due flussi di dati ordinati in un unico flusso di dati ordinato è denominato "Unisci". Segue un flusso di dati SSIS riprogettato che utilizza Unisci per restituire le righe desiderate nell'ordine dell'ID transazione:
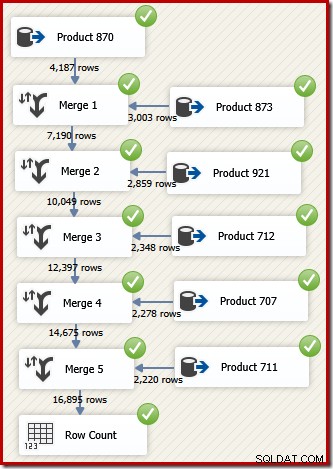
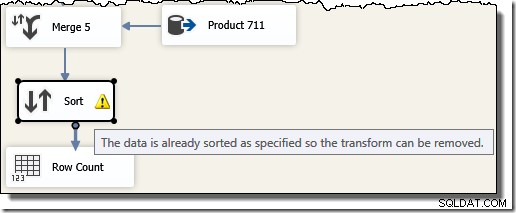
Nota che abbiamo bisogno di cinque componenti Unisci separati perché Unisci è un componente binario, a differenza del componente SSIS "Union All", che era n-ary . Il nuovo flusso di unione produce risultati nell'ordine dell'ID transazione, senza richiedere un costoso (e bloccante) componente di ordinamento. Infatti, se proviamo ad aggiungere un Sort on Transaction ID dopo l'unione finale, SSIS mostra un avviso per farci sapere che lo stream è già ordinato nel modo desiderato:
Il punto dell'esempio SSIS può ora essere rivelato. Osserva il piano di esecuzione scelto da Query Optimizer di SQL Server quando gli chiediamo di restituire i risultati della query T-SQL originale nell'ordine dell'ID transazione (aggiungendo una clausola ORDER BY):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Le somiglianze con il pacchetto SSIS Merge sono sorprendenti; anche fino alla necessità di cinque operatori binari "Unisci". L'unica differenza importante è che SSIS ha componenti separati per "Unisci unisci" e "Unisci" mentre SQL Server utilizza lo stesso operatore principale per entrambi.
Per essere chiari, gli operatori Merge Join (concatenazione) nel piano di esecuzione di SQL Server non eseguire un join; il motore riutilizza semplicemente lo stesso operatore fisico per implementare l'unione di conservazione degli ordini all.
Scrittura di piani di esecuzione in SQL Server
SSIS non dispone di un linguaggio di specifica del flusso di dati, né di un ottimizzatore per trasformare tale specifica in un'attività di flusso di dati eseguibile. Spetta al progettista del pacchetto SSIS rendersi conto che è possibile un'unione che preserva l'ordine, impostare le proprietà dei componenti (come le chiavi di ordinamento) in modo appropriato, quindi confrontare le prestazioni. Ciò richiede più impegno (e abilità) da parte del progettista, ma fornisce un ottimo grado di controllo.
La situazione in SQL Server è l'opposto:scriviamo una query specifica utilizzando il linguaggio T-SQL, quindi affidati a Query Optimizer per esplorare le opzioni di implementazione e sceglierne una efficiente. Non abbiamo la possibilità di costruire direttamente un piano di esecuzione. Il più delle volte, questo è altamente auspicabile:SQL Server sarebbe senza dubbio piuttosto meno popolare se ogni query richiedesse la scrittura di un pacchetto in stile SSIS.
Tuttavia (come spiegato nel mio post precedente), il piano scelto dall'ottimizzatore può essere sensibile al T-SQL utilizzato per descrivere i risultati desiderati. Ripetendo l'esempio di quell'articolo, avremmo potuto scrivere la query T-SQL originale utilizzando una sintassi alternativa:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
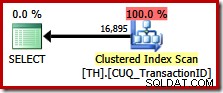
Questa query specifica esattamente lo stesso set di risultati di prima, ma l'ottimizzatore non considera un piano di conservazione degli ordini (unione di concatenazione), scegliendo invece di eseguire la scansione dell'indice cluster (un'opzione molto meno efficiente):
Utilizzo della conservazione dell'ordine in SQL Server
Evitare l'ordinamento non necessario può portare a notevoli guadagni di efficienza, sia che si parli di SSIS o SQL Server. Raggiungere questo obiettivo può essere più complicato e difficile in SQL Server perché non abbiamo un controllo così granulare sul piano di esecuzione, ma ci sono ancora cose che possiamo fare.
In particolare, capire come funziona internamente l'operatore di concatenazione di join unione di SQL Server può aiutarci a continuare a scrivere T-SQL chiaro e relazionale, incoraggiando al contempo Query Optimizer a considerare le opzioni di elaborazione di conservazione degli ordini (unione), ove appropriato.
Come funziona la concatenazione Unisci unisciti

Un normale Merge Join richiede che entrambi gli input siano ordinati sulle chiavi di join. Unisci join concatenazione, d'altra parte, unisce semplicemente due flussi già ordinati in un unico flusso ordinato:non c'è alcun join, in quanto tale.
Questo fa sorgere la domanda:qual è esattamente l'"ordine" che viene mantenuto?
In SSIS, dobbiamo impostare le proprietà della chiave di ordinamento sugli input Unisci per definire l'ordinamento. SQL Server non ha equivalenti a questo. La risposta alla domanda precedente è un po' complicata, quindi la faremo passo dopo passo.
Considera l'esempio seguente, che richiede una concatenazione di tipo merge di due tabelle heap non indicizzate (il caso più semplice):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
Queste due tabelle non hanno indici e non esiste una clausola ORDER BY. Quale ordinamento "conserverà" la concatenazione di join join? Per darti un momento per pensarci, diamo prima un'occhiata al piano di esecuzione prodotto per la query precedente nelle versioni di SQL Server prima 2012:
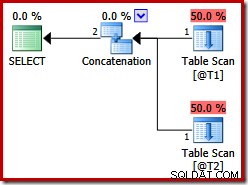
Non esiste un'unione di join concatenazione, nonostante l'hint di query:prima di SQL Server 2012, questo hint funziona solo con UNION, non UNION ALL. Per ottenere un piano con l'operatore di unione desiderato, è necessario disabilitare l'implementazione di un UNION ALL logico (UNIA) utilizzando l'operatore fisico Concatenation (CON). Tieni presente che quanto segue non è documentato e non è supportato per l'uso in produzione:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
Tale query produce lo stesso piano di SQL Server 2012 e 2014 con il solo suggerimento per la query MERGE UNION:
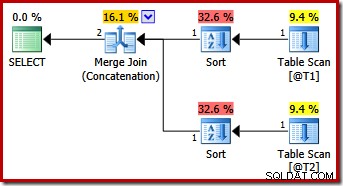
Forse inaspettatamente, il piano di esecuzione presenta ordinamenti espliciti su entrambi gli input per l'unione. Le proprietà di ordinamento sono:
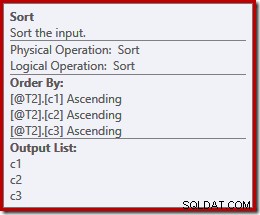
Ha senso che un'unione di conservazione dell'ordine richieda un ordinamento di input coerente, ma perché ha scelto (c1, c2, c3) invece di, diciamo (c3, c1, c2) o (c2, c3, c1)? Come punto di partenza, gli input di concatenazione di unione vengono ordinati nell'elenco di proiezione dell'output. La stella di selezione nella query si espande in (c1, c2, c3) in modo che sia l'ordine scelto.
Ordina per unione elenco proiezioni output
Per illustrare ulteriormente il punto, possiamo espandere noi stessi la stella di selezione (come dovremmo!) Scegliendo un ordine diverso (c3, c2, c1) mentre ci siamo:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Gli ordinamenti ora cambiano per corrispondere (c3, c2, c1):
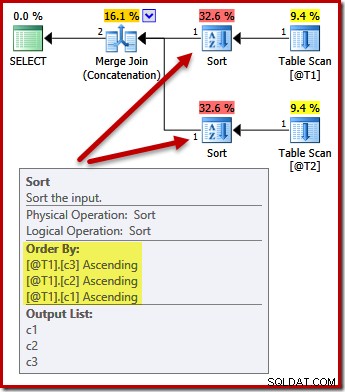
Di nuovo, la query output order (supponendo che dovessimo aggiungere alcuni dati alle tabelle) non è garantito per essere ordinato come mostrato, perché non abbiamo la clausola ORDER BY. Questi esempi hanno semplicemente lo scopo di mostrare come l'ottimizzatore seleziona un ordinamento di input iniziale, in assenza di altri motivi per ordinare.
Ordini di smistamento in conflitto
Consideriamo ora cosa succede se lasciamo l'elenco di proiezione come (c3, c2, c1) e aggiungiamo un requisito per ordinare i risultati della query in base a (c1, c2, c3). Gli input per l'unione verranno comunque ordinati su (c3, c2, c1) con un ordinamento post-unione su (c1, c2, c3) per soddisfare l'ORDER BY?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
No. L'ottimizzatore è abbastanza intelligente da evitare l'ordinamento due volte:
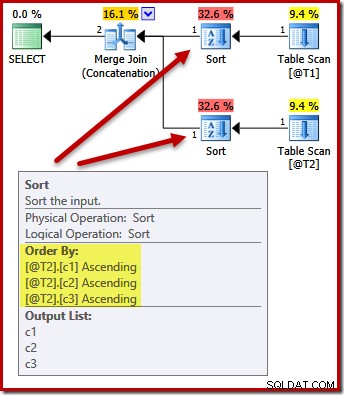
L'ordinamento di entrambi gli input su (c1, c2, c3) è perfettamente accettabile per la concatenazione di unione, quindi non è richiesto un doppio ordinamento.
Tieni presente che questo piano fa garantire che l'ordine dei risultati sarà (c1, c2, c3). Il piano ha lo stesso aspetto dei piani precedenti senza ORDER BY, ma non tutti i dettagli interni sono presentati nei piani di esecuzione visibili all'utente.
L'effetto dell'unicità
Quando si sceglie un ordinamento per gli input di unione, l'ottimizzatore è influenzato anche da eventuali garanzie di unicità esistenti. Considera l'esempio seguente, con cinque colonne, ma nota i diversi ordini di colonna nell'operazione UNION ALL:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Il piano di esecuzione include gli ordinamenti su (c5, c1, c2, c4, c3) per la tabella @T1 e (c5, c4, c3, c2, c1) per la tabella @T2:
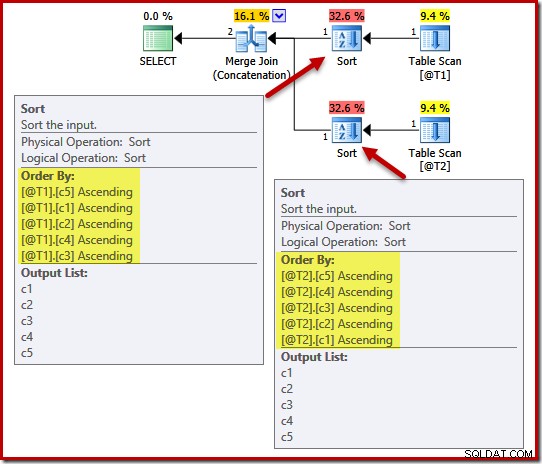
Per dimostrare l'effetto dell'unicità su questi tipi, aggiungeremo un vincolo UNIQUE alla colonna c1 nella tabella T1 e alla colonna c4 nella tabella T2:
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Il punto sull'unicità è che l'ottimizzatore sa che può interrompere l'ordinamento non appena incontra una colonna che è garantita come unica. L'ordinamento per colonne aggiuntive dopo che è stata rilevata una chiave univoca non influirà sull'ordinamento finale, per definizione.
Con i vincoli UNIQUE in atto, l'ottimizzatore può semplificare l'elenco di ordinamento (c5, c1, c2, c4, c3) da T1 a (c5, c1) perché c1 è univoco. Allo stesso modo, l'elenco di ordinamento (c5, c4, c3, c2, c1) per T2 è semplificato in (c5, c4) perché c4 è una chiave:
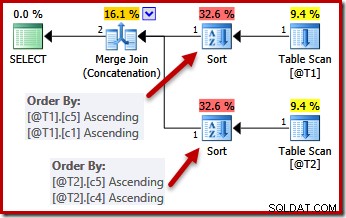
Parallelismo
La semplificazione dovuta a una chiave univoca non è perfettamente implementata. In un piano parallelo, i flussi vengono partizionati in modo che tutte le righe per la stessa istanza dell'unione finiscano sullo stesso thread. Questo partizionamento del set di dati si basa sulle colonne di unione e non è semplificato dalla presenza di una chiave.
Lo script seguente utilizza il flag di traccia non supportato 8649 per generare un piano parallelo per la query precedente (che altrimenti non cambia):
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
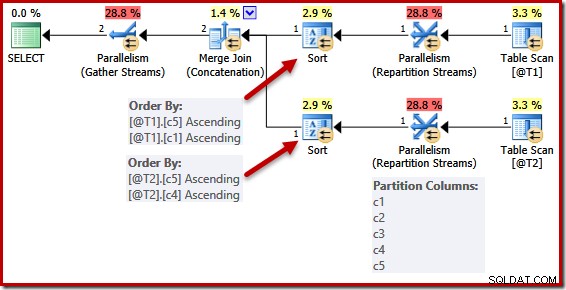
Gli elenchi di ordinamento sono semplificati come prima, ma gli operatori Repartition Streams continuano a partizionare su tutte le colonne. Se questa semplificazione fosse implementata in modo coerente, gli operatori di ripartizionamento opererebbero anche solo su (c5, c1) e (c5, c4).
Problemi con indici non univoci
Il modo in cui l'ottimizzatore ragiona sui requisiti di ordinamento per la concatenazione di unione può causare problemi di ordinamento non necessari, come mostra l'esempio successivo:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Osservando la query e gli indici disponibili, ci si aspetterebbe un piano di esecuzione che esegua una scansione ordinata degli indici cluster, utilizzando la concatenazione di join di unione per evitare la necessità di qualsiasi ordinamento. Questa aspettativa è pienamente giustificata, poiché gli indici cluster forniscono l'ordinamento specificato nella clausola ORDER BY. Sfortunatamente, il piano che effettivamente otteniamo include due tipi:
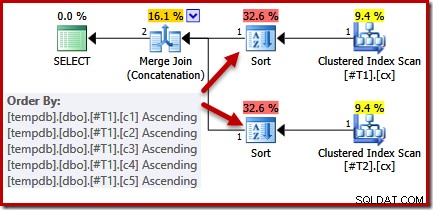
Non esiste una buona ragione per questi ordinamenti, vengono visualizzati solo perché la logica di Query Optimizer è imperfetta. L'elenco delle colonne di output di unione (c1, c2, c3, c4, c5) è un superset di ORDER BY, ma non esiste un unico chiave per semplificare tale elenco. Come risultato di questa lacuna nel ragionamento dell'ottimizzatore, conclude che l'unione richiede che il suo input sia ordinato (c1, c2, c3, c4, c5).
Possiamo verificare questa analisi modificando lo script per rendere unico uno degli indici cluster:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Il piano di esecuzione ora ha solo un ordinamento sopra la tabella con l'indice non univoco:
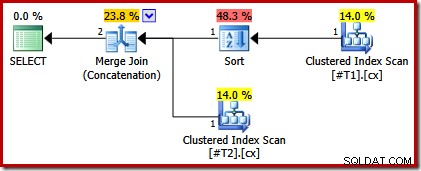
Se ora creiamo entrambi indici cluster univoci, non vengono visualizzati ordinamenti:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
Con entrambi gli indici univoci, gli elenchi di ordinamento dell'input di unione iniziale possono essere semplificati nella sola colonna c1. L'elenco semplificato corrisponde quindi esattamente alla clausola ORDER BY, quindi non sono necessari ordinamenti nel piano finale:
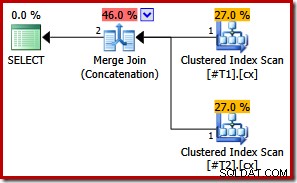
Si noti che non abbiamo nemmeno bisogno del suggerimento per la query in questo ultimo esempio per ottenere il piano di esecuzione ottimale.
Pensieri finali
Eliminare gli ordinamenti in un piano di esecuzione può essere complicato. In alcuni casi, può essere semplice come modificare un indice esistente (o fornirne uno nuovo) per fornire le righe nell'ordine richiesto. Query Optimizer esegue nel complesso un lavoro ragionevole quando sono disponibili gli indici appropriati.
In (molti) altri casi, tuttavia, evitare gli ordinamenti può richiedere una comprensione molto più approfondita del motore di esecuzione, di Query Optimizer e degli stessi operatori del piano. Evitare gli ordinamenti è senza dubbio un argomento avanzato di ottimizzazione delle query, ma anche incredibilmente gratificante quando tutto va bene.