Nel 2012, ho scritto un post sul blog qui evidenziando gli approcci per il calcolo di una mediana. In quel post, ho affrontato il caso molto semplice:volevamo trovare la mediana di una colonna su un'intera tabella. Da allora mi è stato detto più volte che un requisito più pratico è calcolare una mediana partizionata . Come nel caso di base, esistono diversi modi per risolvere questo problema in varie versioni di SQL Server; non sorprende che alcuni si comportino molto meglio di altri.
Nell'esempio precedente, avevamo solo colonne generiche id e val. Rendiamolo più realistico e diciamo che abbiamo venditori e il numero di vendite che hanno fatto in un certo periodo. Per testare le nostre query, creiamo prima un semplice heap con 17 righe e verifichiamo che tutte producano i risultati che ci aspettiamo (SalesPerson 1 ha una mediana di 7,5 e SalesPerson 2 ha una mediana di 6,0):
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) VALUES (1, 6 ),(1, 11),(1, 4 ),(1, 4 ), (1, 15),(1, 14),(1, 4 ),(1, 9 ), (2, 6 ),(2, 11),(2, 4 ),(2, 4 ), (2, 15),(2, 14),(2, 4 );
Ecco le query, che testeremo (con molti più dati!) rispetto all'heap sopra, nonché con indici di supporto. Ho scartato un paio di query dal test precedente, che non sono state affatto ridimensionate o non sono state mappate molto bene alle mediane partizionate (vale a dire, 2000_B, che utilizzava una tabella #temp, e 2005_A, che utilizzava la riga opposta numeri). Tuttavia, ho aggiunto alcune idee interessanti da un recente articolo di Dwain Camps (@DwainCSQL), basato sul mio post precedente.
SQL Server 2000+
L'unico metodo dell'approccio precedente che funzionava abbastanza bene su SQL Server 2000 da includerlo anche in questo test era l'approccio "minimo di una metà, massimo dell'altra":
SELECT DISTINCT s.SalesPerson, Median = (
(SELECT MAX(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount) AS t)
+ (SELECT MIN(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount DESC) AS b)
) / 2.0
FROM dbo.Sales AS s; Onestamente ho provato a imitare la versione della tabella #temp che ho usato nell'esempio più semplice, ma non si è adattata affatto bene. A 20 o 200 righe funzionava bene; al 2000 ci voleva quasi un minuto; a 1.000.000 ho rinunciato dopo un'ora. L'ho incluso qui per i posteri (clicca per rivelare).
CREATE TABLE #x
(
i INT IDENTITY(1,1),
SalesPerson INT,
Amount INT,
i2 INT
);
CREATE CLUSTERED INDEX v ON #x(SalesPerson, Amount);
INSERT #x(SalesPerson, Amount)
SELECT SalesPerson, Amount
FROM dbo.Sales
ORDER BY SalesPerson,Amount OPTION (MAXDOP 1);
UPDATE x SET i2 = i-
(
SELECT COUNT(*) FROM #x WHERE i <= x.i
AND SalesPerson < x.SalesPerson
)
FROM #x AS x;
SELECT SalesPerson, Median = AVG(0. + Amount)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE SalesPerson = x.SalesPerson
AND x.i2 - (SELECT MAX(i2) / 2.0 FROM #x WHERE SalesPerson = x.SalesPerson)
IN (0, 0.5, 1)
)
GROUP BY SalesPerson;
GO
DROP TABLE #x; SQL Server 2005+1
Questo utilizza due diverse funzioni di windowing per derivare una sequenza e un conteggio complessivo degli importi per addetto alle vendite.
SELECT SalesPerson, Median = AVG(1.0*Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount),
c = COUNT(*) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2005+2
Questo è venuto dall'articolo di Dwain Camps, che fa lo stesso di sopra, in un modo leggermente più elaborato. Questo fondamentalmente annulla le righe interessanti in ogni gruppo.
;WITH Counts AS
(
SELECT SalesPerson, c
FROM
(
SELECT SalesPerson, c1 = (c+1)/2,
c2 = CASE c%2 WHEN 0 THEN 1+c/2 ELSE 0 END
FROM
(
SELECT SalesPerson, c=COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
) a
) a
CROSS APPLY (VALUES(c1),(c2)) b(c)
)
SELECT a.SalesPerson, Median=AVG(0.+b.Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount)
FROM dbo.Sales a
) a
CROSS APPLY
(
SELECT Amount FROM Counts b
WHERE a.SalesPerson = b.SalesPerson AND a.rn = b.c
) b
GROUP BY a.SalesPerson; SQL Server 2005+3
Questo si basava su un suggerimento di Adam Machanic nei commenti al mio post precedente e migliorato anche da Dwain nel suo articolo sopra.
;WITH Counts AS
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
)
SELECT a.SalesPerson, Median = AVG(0.+Amount)
FROM Counts a
CROSS APPLY
(
SELECT TOP (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
b.Amount, r = ROW_NUMBER() OVER (ORDER BY b.Amount)
FROM dbo.Sales b
WHERE a.SalesPerson = b.SalesPerson
ORDER BY b.Amount
) p
WHERE r BETWEEN ((a.c - 1) / 2) + 1 AND (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
GROUP BY a.SalesPerson; SQL Server 2005+4
È simile a "2005+ 1" sopra, ma invece di usare COUNT(*) OVER() per ricavare i conteggi, esegue un self-join rispetto a un aggregato isolato in una tabella derivata.
SELECT SalesPerson, Median = AVG(1.0 * Amount)
FROM
(
SELECT s.SalesPerson, s.Amount, rn = ROW_NUMBER() OVER
(PARTITION BY s.SalesPerson ORDER BY s.Amount), c.c
FROM dbo.Sales AS s
INNER JOIN
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales GROUP BY SalesPerson
) AS c
ON s.SalesPerson = c.SalesPerson
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2012+1
Questo è stato un contributo molto interessante del collega MVP di SQL Server Peter "Peso" Larsson (@SwePeso) nei commenti all'articolo di Dwain; utilizza CROSS APPLY e il nuovo OFFSET / FETCH funzionalità in un modo ancora più interessante e sorprendente rispetto alla soluzione di Itzik per il calcolo della mediana più semplice.
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median); SQL Server 2012+2
Infine, abbiamo il nuovo PERCENTILE_CONT() funzione introdotta in SQL Server 2012.
SELECT SalesPerson, Median = MAX(Median)
FROM
(
SELECT SalesPerson,Median = PERCENTILE_CONT(0.5) WITHIN GROUP
(ORDER BY Amount) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
GROUP BY SalesPerson; Le vere prove
Per testare le prestazioni delle query precedenti, creeremo una tabella molto più sostanziale. Avremo 100 venditori unici, con 10.000 cifre dell'importo delle vendite ciascuno, per un totale di 1.000.000 di righe. Inoltre, eseguiremo ogni query sull'heap così com'è, con un indice non cluster aggiunto su (SalesPerson, Amount) e con un indice cluster sulle stesse colonne. Ecco la configurazione:
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO --CREATE CLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --CREATE NONCLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --DROP INDEX x ON dbo.sales; ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3;
Ed ecco i risultati delle query precedenti, rispetto all'heap, all'indice non cluster e all'indice cluster:
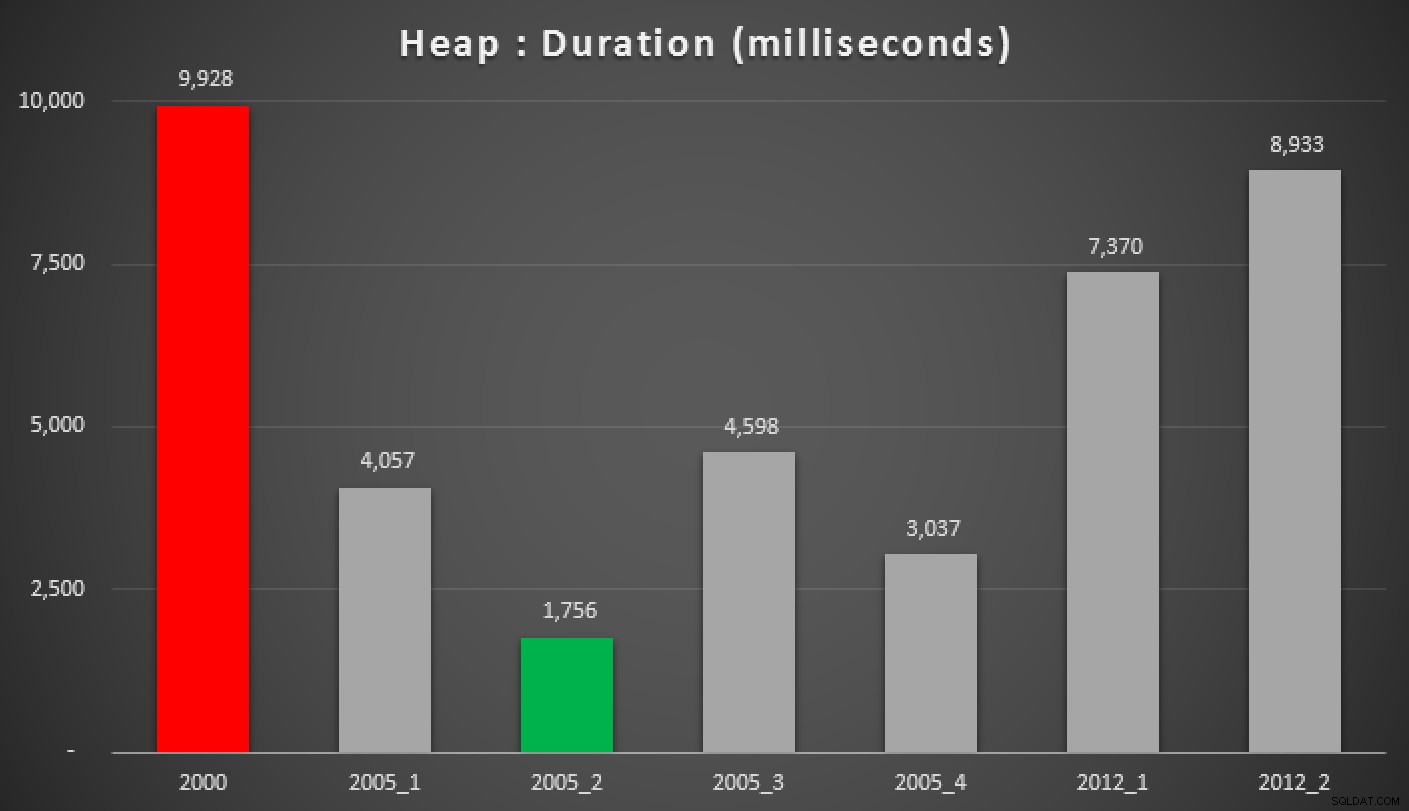
Durata, in millisecondi, di vari approcci mediani raggruppati (contro un mucchio)
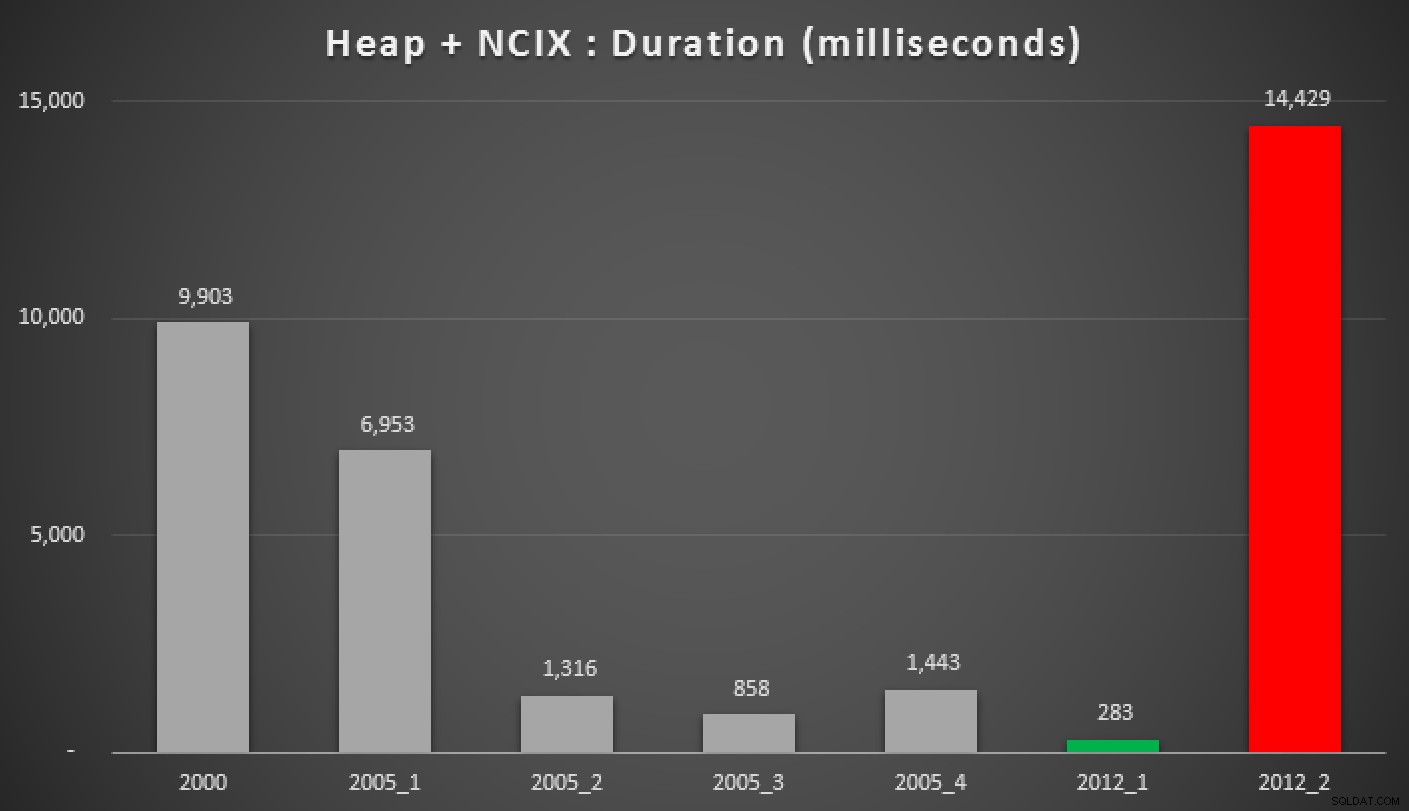
Durata, in millisecondi, di vari approcci mediani raggruppati (contro un heap con un indice non cluster)
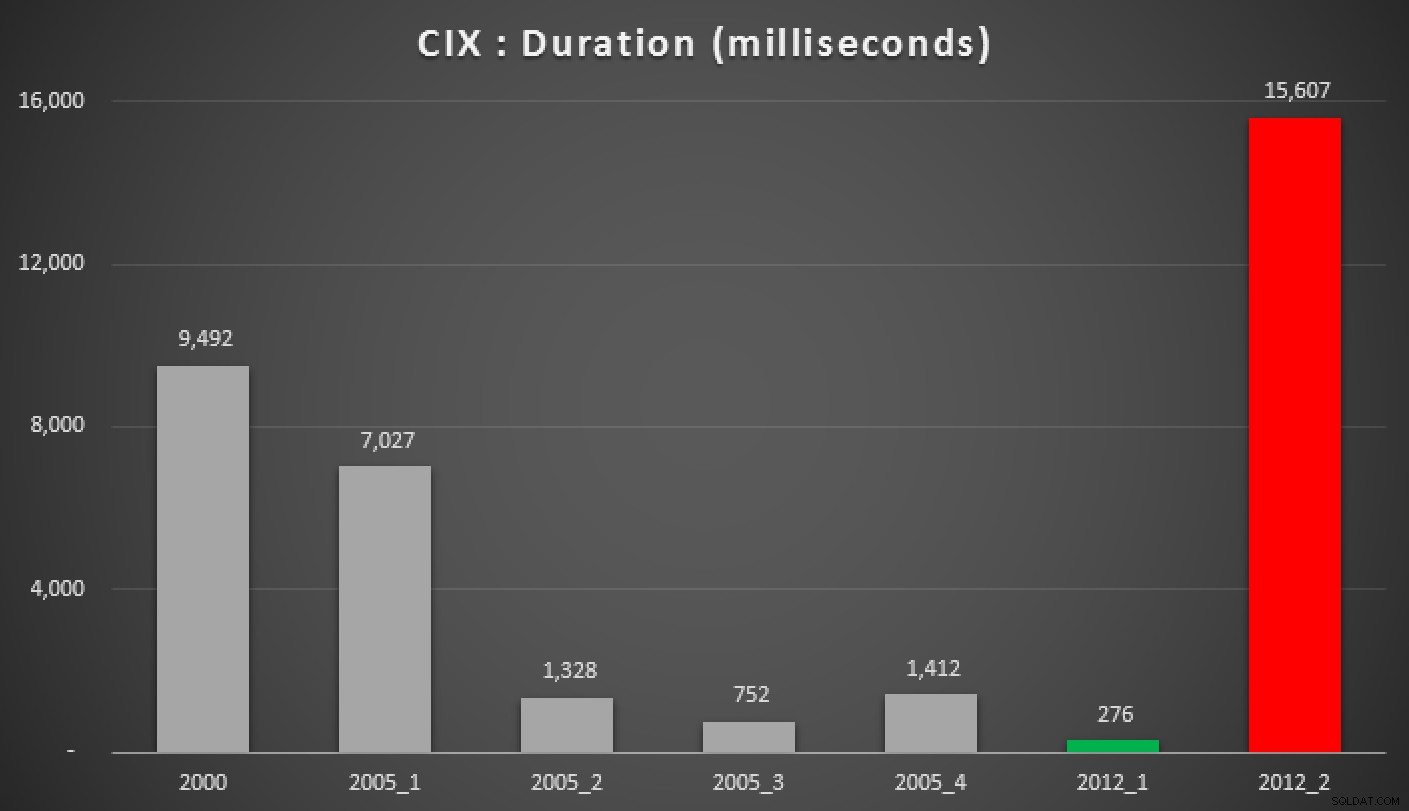
Durata, in millisecondi, di vari approcci mediani raggruppati (contro un indice cluster)
E Hekaton?
Naturalmente, ero curioso di sapere se questa nuova funzionalità di SQL Server 2014 potesse aiutare con una di queste query. Quindi ho creato un database In-Memory, due versioni In-Memory della tabella Sales (una con un indice hash su (SalesPerson, Amount) e l'altro solo su (SalesPerson) ), ed eseguire nuovamente gli stessi test:
CREATE DATABASE Hekaton; GO ALTER DATABASE Hekaton ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE Hekaton ADD FILE (name = 'xtp', filename = 'c:\temp\hek.mod') TO FILEGROUP xtp; GO ALTER DATABASE Hekaton SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT ON; GO USE Hekaton; GO CREATE TABLE dbo.Sales1 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson, Amount) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO CREATE TABLE dbo.Sales2 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales1 (SalesPerson, Amount) -- TABLOCK/TABLOCKX not allowed here SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3; INSERT dbo.Sales2 (SalesPerson, Amount) SELECT SalesPerson, Amount FROM dbo.Sales1;
I risultati:
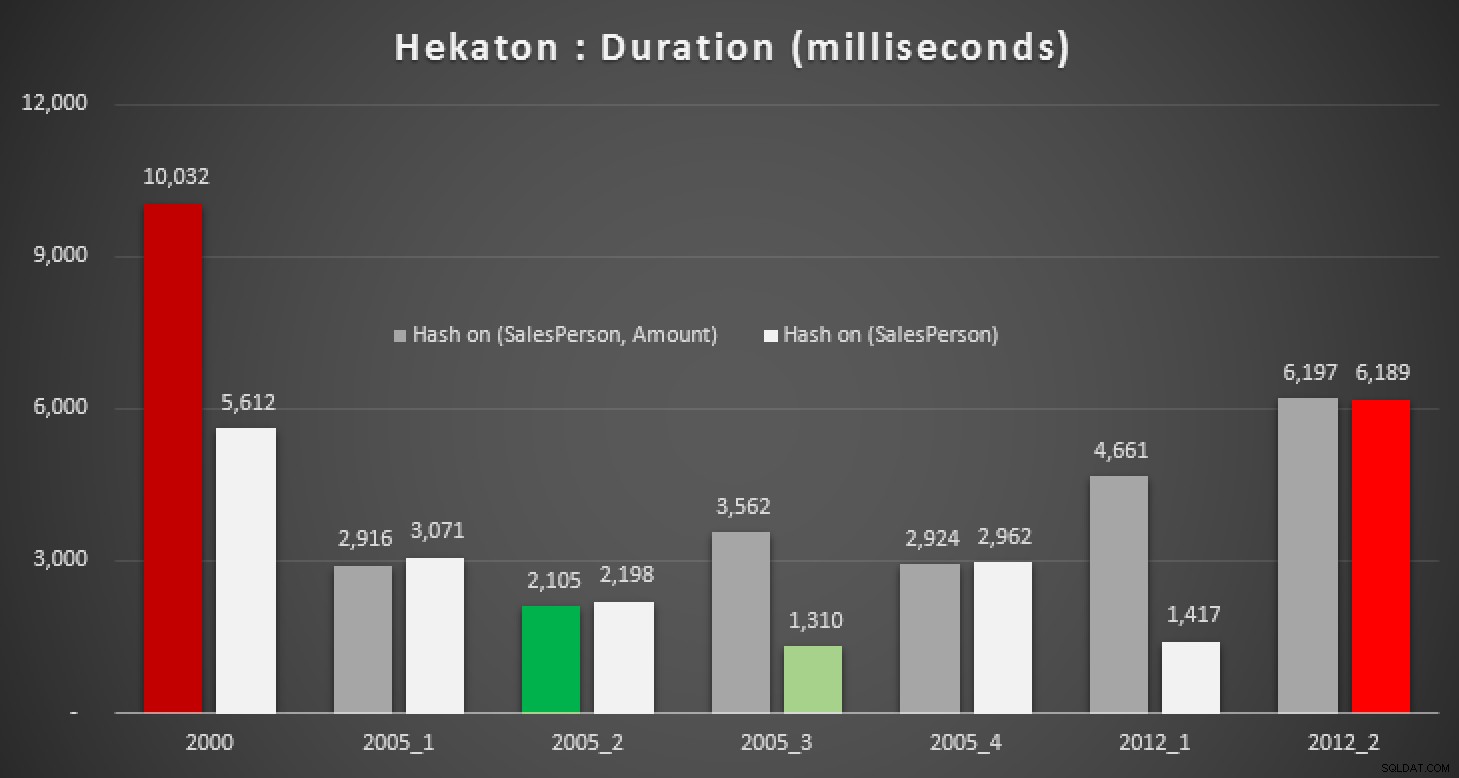
Durata, in millisecondi, per vari calcoli mediani rispetto a In-Memory tabelle
Anche con il giusto indice hash, non vediamo miglioramenti significativi rispetto a una tabella tradizionale. Inoltre, provare a risolvere il problema della mediana utilizzando una stored procedure compilata in modo nativo non sarà un compito facile, poiché molti dei costrutti linguistici usati sopra non sono validi (anche alcuni di questi sono rimasto sorpreso). Il tentativo di compilare tutte le variazioni della query di cui sopra ha prodotto questa serie di errori; alcuni si sono verificati più volte all'interno di ciascuna procedura e, anche dopo aver rimosso i duplicati, questo è ancora abbastanza comico:
Msg 10794, livello 16, stato 47, procedura GroupedMedian_2000L'opzione 'DISTINCT' non è supportata con stored procedure compilate in modo nativo.
Msg 12311, livello 16, stato 37, procedura GroupedMedian_2000
Subquery ( query nidificate all'interno di un'altra query) non sono supportati con le stored procedure compilate in modo nativo.
Msg 10794, livello 16, stato 48, procedura GroupedMedian_2000
L'opzione 'PERCENT' non è supportata con le stored procedure compilate in modo nativo.
Msg 12311, livello 16, stato 37, procedura GroupedMedian_2005_1
Le sottoquery (query annidate all'interno di un'altra query) non sono supportate con le stored procedure compilate in modo nativo.
Msg 10794, livello 16, stato 91 , Procedura GroupedMedian_2005_1
La funzione di aggregazione 'ROW_NUMBER' non è supportata con stored procedure compilate in modo nativo.
Msg 10794, Livello 16, Stato 56, Procedura GroupedMedian_2005_1
L'operatore 'IN' non è supportato con stored procedure compilate in modo nativo.
Msg 12310, Livello 16, stato 36, procedura GroupedMedian_2005_2
Le espressioni di tabella comuni (CTE) non sono supportate con procedure archiviate compilate in modo nativo.
Msg 12309, livello 16, stato 35, procedura GroupedMedian_2005_2
Dichiarazioni del modulo INSERT...VALUES... che inseriscono più righe non sono supportati con le stored procedure compilate in modo nativo.
Msg 10794, livello 16, stato 53, procedura GroupedMedian_2005_2
L'operatore 'APPLY' non è supportato con le stored procedure compilate in modo nativo.
Msg 12311, livello 16, stato 37, procedura GroupedMedian_2005_2
Le sottoquery (query nidificate all'interno di un'altra query) non sono supportate con stored procedure compilate in modo nativo.
Msg 10794, livello 16, stato 91, procedura GroupedMedian_2005_2
La funzione di aggregazione 'ROW_NUMBER' non è supportata con le stored procedure compilate in modo nativo.
Msg 12310, Level 16, State 36, Procedure GroupedMedian_2005_3
Common Table Expressions (CTE) are non supportato con l'archivio compilato in modo nativo procedure.
Msg 12311, livello 16, stato 37, procedura GroupedMedian_2005_3
Le sottoquery (query annidate all'interno di un'altra query) non sono supportate con le stored procedure compilate in modo nativo.
Msg 10794, livello 16, stato 91 , Procedura GroupedMedian_2005_3
La funzione di aggregazione 'ROW_NUMBER' non è supportata con stored procedure compilate in modo nativo.
Msg 10794, Livello 16, Stato 53, Procedura GroupedMedian_2005_3
L'operatore 'APPLY' non è supportato con stored procedure compilate in modo nativo.
Msg 12311, livello 16, stato 37, procedura GroupedMedian_2005_4
Le sottoquery (query annidate all'interno di un'altra query) non sono supportate con le stored procedure compilate in modo nativo.
Msg 10794, livello 16, stato 91, procedura GroupedMedian_2005_4
La funzione di aggregazione 'ROW_NUMBER' non è supportata con stored procedure compilate in modo nativo.
Msg 10794, livello 16, stato 56, procedura GroupedMedian_2005_4
L'operatore 'IN' non è supportato con stor compilato in modo nativo ed procedure.
Msg 12311, livello 16, stato 37, procedura GroupedMedian_2012_1
Le sottoquery (query annidate all'interno di un'altra query) non sono supportate con le stored procedure compilate in modo nativo.
Msg 10794, Livello 16, Stato 38, Procedura GroupedMedian_2012_1
L'operatore 'OFFSET' non è supportato con le stored procedure compilate in modo nativo.
Msg 10794, Livello 16, Stato 53, Procedura GroupedMedian_2012_1
L'operatore 'APPLY' non è supportato con le stored procedure compilate in modo nativo.
Msg 12311, livello 16, stato 37, procedura GroupedMedian_2012_2
Le sottoquery (query nidificate all'interno di un'altra query) non sono supportate con le stored procedure compilate in modo nativo.
Msg 10794, livello 16, stato 90, procedura GroupedMedian_2012_2
La funzione di aggregazione 'PERCENTILE_CONT' non è supportata con le stored procedure compilate in modo nativo.
Come attualmente scritto, nessuna di queste query può essere trasferita in una stored procedure compilata in modo nativo. Forse qualcosa da esaminare per un altro post di follow-up.
Conclusione
Scartando i risultati di Hekaton e quando è presente un indice di supporto, la query di Peter Larsson ("2012+ 1") utilizzando OFFSET/FETCH è uscito come il vincitore di gran lunga in questi test. Sebbene un po' più complesso della query equivalente nei test non partizionati, questo corrispondeva ai risultati che ho osservato l'ultima volta.
In quegli stessi casi, il 2000 MIN/MAX approccio e PERCENTILE_CONT() del 2012 sono usciti come cani veri; di nuovo, proprio come i miei precedenti test contro il caso più semplice.
Se non sei ancora su SQL Server 2012, la tua prossima opzione migliore è "2005+ 3" (se hai un indice di supporto) o "2005+ 2" se hai a che fare con un heap. Mi dispiace di aver dovuto inventare un nuovo schema di denominazione per questi, principalmente per evitare confusione con i metodi nel mio post precedente.
Naturalmente, questi sono i miei risultati rispetto a uno schema e a un set di dati molto specifici:come per tutti i consigli, dovresti testare questi approcci rispetto al tuo schema e ai tuoi dati, poiché altri fattori possono influenzare risultati diversi.
Un'altra nota
Oltre ad avere prestazioni scadenti e non essere supportato nelle procedure memorizzate compilate in modo nativo, un altro punto dolente di PERCENTILE_CONT() è che non può essere utilizzato nelle modalità di compatibilità precedenti. Se provi, ricevi questo errore:
La funzione PERCENTILE_CONT non è consentita nella modalità di compatibilità corrente. È consentito solo in modalità 110 o superiore.