Indipendentemente da quale parte dell'equazione ti trovi, a volte è difficile trovare una persona qualificata per un lavoro specifico. In questo post, esaminiamo un modello di dati per aiutare i reclutatori e i dipartimenti delle risorse umane a rimanere organizzati durante il processo di assunzione.
La maggior parte di noi è stata coinvolta nel processo di assunzione, il più delle volte come candidato al lavoro. Possiamo però trovarci coinvolti anche sul versante delle assunzioni, magari mettendo alla prova le conoscenze tecniche del candidato. Il processo di reclutamento richiede un certo lasso di tempo e il gruppo di candidati diventa sempre più piccolo man mano che ci avviciniamo alla decisione finale. Il risultato dovrebbe essere la selezione della persona migliore per il lavoro.
Il reclutamento di per sé è piuttosto complicato, quindi discuteremo di un modello di dati abbastanza completo per coprire tutti gli aspetti del processo. Siediti sulla sedia e goditi l'articolo di oggi!
Come funziona il processo di reclutamento
La maggior parte delle parti del processo di reclutamento è di dominio pubblico, ma discuteremo esattamente come funziona prima di passare al modello di dati.
-
Rilevamento di un bisogno
Questo è un must assoluto nel processo di reclutamento; non ci sarà alcun processo se la direzione non è a conoscenza della necessità di assumere un nuovo dipendente. Tale esigenza potrebbe essere il risultato dell'avvio di una nuova azienda, della crescita in un'azienda esistente o dell'uscita di un dipendente attuale.
A meno che un'azienda non abbia posizioni rigorosamente definite (es. banche), non è sempre facile determinare quando assumere un nuovo dipendente. Parlare con i dipendenti e vedere molti straordinari può stimolare una nuova assunzione. Le normative interne o esterne possono anche richiedere che determinate posizioni siano assegnate solo a persone con competenze specifiche e un'esperienza lavorativa pertinente (ad es. revisore interno).
-
Delineare la posizione e le sue competenze richieste
Per avere un'idea di questo passaggio, pensa a una descrizione del lavoro davvero ben scritta. Contiene:
- Un elenco di tutte le attività relative al lavoro
- Titoli minimi di istruzione e esperienza lavorativa
- Competenze specifiche essenziali per le funzioni lavorative
- Abilità aggiuntive o preferite
- Un riepilogo di ciò che il datore di lavoro si aspetta dal candidato e di ciò che il candidato può aspettarsi da questo lavoro
- Una fascia di stipendio e forse un pacchetto di vantaggi
Queste informazioni sono importanti sia per i reclutatori che per i candidati. Non ha senso invitare dieci candidati al processo di selezione se nessuno di loro sarà soddisfatto dell'offerta finanziaria. E più dettagliata è la descrizione del lavoro, più facile sarà attrarre candidati qualificati.
-
Definire chi gestirà il processo e quando dovrebbe essere eseguita ogni attività
Il passaggio successivo consiste nel definire date specifiche in cui avverrà ciascuna parte del processo. Inoltre, le aziende possono assegnare dipendenti a ogni passaggio. Se l'azienda dispone di un dipartimento Risorse umane, probabilmente gestirà ogni parte del processo di reclutamento, anche se altri dipendenti possono apportare le loro conoscenze specifiche quando richiesto (ad esempio se stiamo assumendo uno specialista IT, il responsabile del dipartimento IT dovrebbe valutare i candidati ' abilità tecniche).
Se non c'è un dipartimento delle risorse umane, possiamo aspettarci che il personale di gestione sarà responsabile del processo. Nelle piccole e medie imprese, questo non è solo necessario, è anche desiderato.
-
Pubblicare il lavoro
Ora siamo pronti per pubblicare una descrizione del lavoro sul nostro sito, su bacheche di lavoro o aggregatori o su un giornale. Il posto di lavoro dovrebbe contenere i punti elenco elencati nel passaggio 2. Questo aiuterà i potenziali candidati a decidere se vogliono candidarsi per la posizione. È essenziale rendere la descrizione del lavoro accurata; abbiamo tutti perso tempo a fare colloqui per un lavoro che non corrispondeva alla sua descrizione o alle nostre aspettative.
-
Selezionare, testare e intervistare i candidati
Al termine del periodo di candidatura, i candidati con le competenze e l'esperienza più rilevanti saranno invitati a una fase di valutazione iniziale (di solito un colloquio o un test). Gli altri candidati saranno informati che non sono stati selezionati per il lavoro. Una grande azienda dovrebbe invitare un numero minimo predefinito di candidati alla valutazione iniziale. Ciò consente di risparmiare tempo sia per i candidati che per l'azienda.
Le piccole e medie imprese potrebbero decidere di continuare il processo fino a quando non trovano la soluzione migliore. In questi casi, il periodo di candidatura rimarrà aperto fino a quando non verrà trovato il candidato giusto e tutte le altre date saranno definite lungo il percorso.
Il processo di colloquio e test varierà in base alle dimensioni e all'organizzazione dell'azienda. Nelle grandi aziende con dipartimenti delle risorse umane, ci sarà probabilmente una serie di test per verificare le capacità lavorative dei candidati. Altri test possono misurare i tratti psicologici e della personalità per determinare la corrispondenza candidato-lavoro, la corrispondenza richiedente-azienda o persino la sanità mentale del richiedente. ☺
Questi test saranno generalmente suddivisi in più passaggi e ogni passaggio ridurrà il numero di candidati.
-
L'intervista finale
Questo passaggio sarà probabilmente un'intervista dei primi pochi candidati. È il passaggio più importante del processo perché i candidati possono parlare da soli, dimostrare la propria competenza e personalità e determinare se l'azienda e la posizione si adatteranno a loro. Dopo questo passaggio, il miglior candidato riceverà un'offerta. Se accettano, il processo di reclutamento per quella posizione è terminato. Se il candidato rifiuta l'offerta di lavoro, l'azienda farà un'offerta alla sua prossima scelta.
-
Ci sono differenze nel processo di reclutamento per le piccole, medie e grandi imprese? Come li risolveremo nel nostro modello?
Ci saranno alcune differenze nei processi di reclutamento di piccole, medie e grandi aziende. Inoltre, il processo varierà in base alle posizioni assunte. Pensa a quanto sono diverse le competenze e le esperienze richieste per un content manager, un ornitologo e un capitano di una nave da crociera. Alcuni lavori avranno più test e colloqui, altri potrebbero averne solo alcuni. Ma alla fine, tutto si riduce a ottenere le risposte giuste e a classificare i candidati.
In questo modello tratterò tutti i test e le interviste allo stesso modo. Conserveremo le risposte di ciascun candidato, le collegheremo alla domanda pertinente e memorizzeremo il punteggio del candidato per ogni fase del processo.
-
Chi può utilizzare questo modello di dati?
Questo modello è molto specifico e dovrebbe essere utilizzato solo per il processo di reclutamento. Ma non è limitato ai dipartimenti delle risorse umane; potresti anche utilizzare questo modello per gestire un servizio di reclutamento professionale.
-
Il modello dei dati
Il modello di dati si compone di cinque aree tematiche principali:
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
Descriverò ciascuna area tematica separatamente, nello stesso ordine in cui sono elencate.
Sezione 1:Lavori
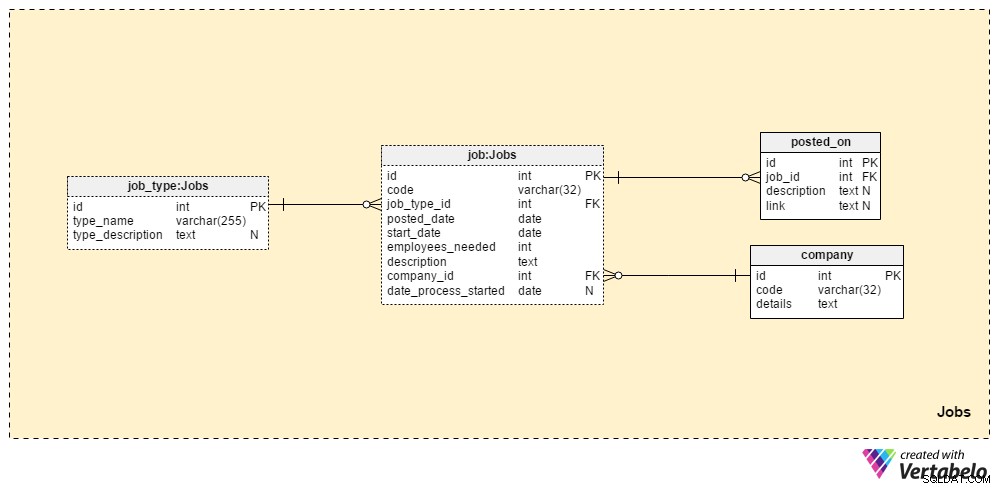
I Jobs la sezione memorizzerà tutti i dettagli per tutte le posizioni che abbiamo mai pubblicato. Le due tabelle del dizionario, la company tabella e il job_type tabella, fanno parte della configurazione iniziale. Le restanti due tabelle, job e posted_on , contengono dati "reali" relativi agli annunci di lavoro.
Il job_type dizionario contiene un elenco di tipi di lavoro diversi e UNICI. Possiamo aspettarci valori come "amministratore di database senior" o "Giornalista IT" da memorizzare nel type_name attributo. Il type_description attributo può memorizzare una descrizione più dettagliata del lavoro.
La company dizionario contiene un elenco di tutte le aziende con cui lavoriamo. Se assumiamo dipendenti solo per la nostra azienda, questo dizionario conterrà solo il nome della nostra azienda. Se siamo un'agenzia di reclutamento, memorizzerà i nomi di tutte le aziende che ci hanno assunto.
Un elenco di tutte le posizioni lavorative che abbiamo pubblicato è memorizzato nella tabella "lavoro". Gli attributi in questa tabella sono:
code– Il nostro ID UNICO interno utilizzato per denotare un lavoro.job_type_id– Fa riferimento al tipo di lavoro correlato.posted_date– La data in cui è stata pubblicata questa posizione lavorativa.start_date– La data di inizio prevista (primo giorno lavorativo) per quel lavoro.employees_needed– Il numero di dipendenti che vogliamo assumere durante questo processo di assunzione. Per lo più questo avrà un valore di "1", ma in alcuni casi, ad es. quando si avvia una nuova azienda o si crea un nuovo dipartimento, possiamo aspettarci valori più grandi.description– Una descrizione dettagliata di tale posizione. Questo è il luogo in cui elencheremo tutte le competenze lavorative richieste, preferite e desiderate.company_id– Fa riferimento all'ID dell'azienda che ci ha assunto. Se siamo un'agenzia di reclutamento, questo farà riferimento a un nome commerciale memorizzato nellacompanytavolo. In caso contrario, sarà l'ID della nostra azienda.date_process_started– La data di inizio del processo di assunzione. Questo potrebbe essere NULL se abbiamo bisogno di definire i passaggi e le azioni future riguardanti questo lavoro.
L'ultima tabella in questa area tematica è il posted_on tavolo. Per ogni job_id , memorizzeremo un link al job post e alla relativa description . Potremmo utilizzare questi dati per sapere dove i candidati trovano i nostri posti di lavoro.
Sezione 2:Candidati, reclutatori e documenti
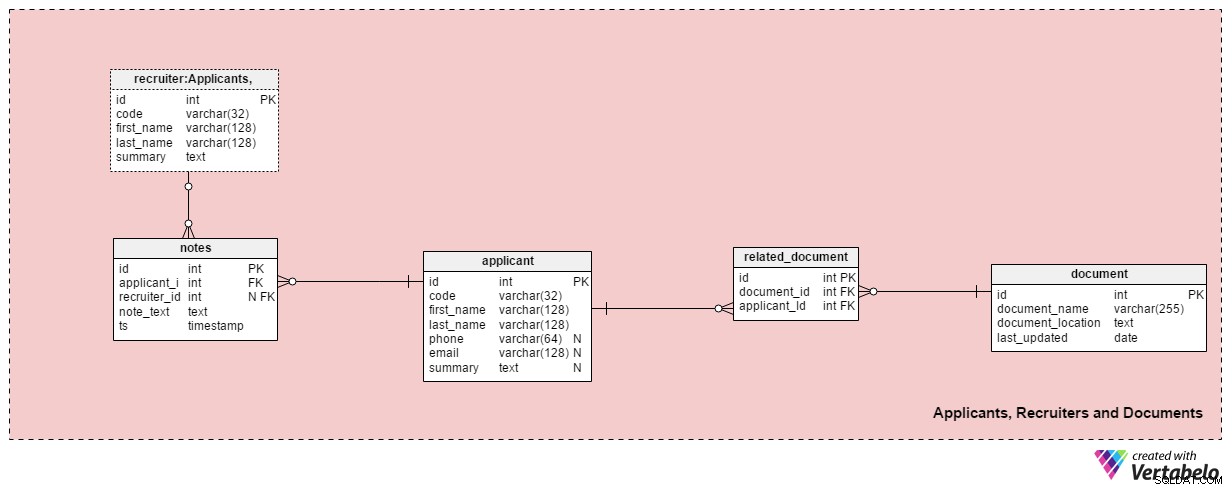
Questa area tematica contiene tutte le tabelle necessarie per memorizzare informazioni su reclutatori, candidati e relativi documenti.
Il applicant la tabella elenca tutti i candidati con cui abbiamo avuto contatti. Ogni richiedente è UNICAMENTE definito nel nostro sistema con un “codice”. Oltre a ciò, memorizzeremo il nome e il cognome di ogni candidato, phone numero, email indirizzo e il loro summary . Questa tabella può essere adattata per esigenze specifiche, ad es. aggiungendo ulteriori numeri di telefono, email o indirizzi fisici.
Metteremo in relazione i candidati con i documenti disponibili. Un elenco di tutti i documenti disponibili (CV o curriculum, lauree o diplomi, trascrizioni, certificazioni, ecc.) è archiviato nel document tavolo. Per ogni documento, memorizzeremo il suo nome nel sistema, la sua posizione e l'ora dell'aggiornamento più recente.
Metteremo in relazione i candidati con i documenti utilizzando il related_document tavolo. Contiene solo due chiavi esterne, che formano il document_id – applicant_id Coppia UNICA.
Il recruiter la tabella elenca i dipendenti che potrebbero essere assegnati a una domanda di lavoro o che inseriscono note relative a un candidato. Ogni reclutatore è UNICAMENTE definito dal suo code . Conserveremo solo i dettagli di base come first_name , last_name e il summary del reclutatore .
L'ultima tabella in questa area tematica sono le notes tavolo. Qui è dove memorizzeremo tutte le note relative a un richiedente. Potremmo memorizzare note come "Il candidato ha saltato la riunione" oppure "Il candidato è andato benissimo al primo colloquio" . Per ogni nota, memorizzeremo l'ID del recruiter che ha fatto quella nota, l'ID del relativo candidato, il note_text e il timestamp quando è stata creata la nota.
Sezione 3:Dettagli del test
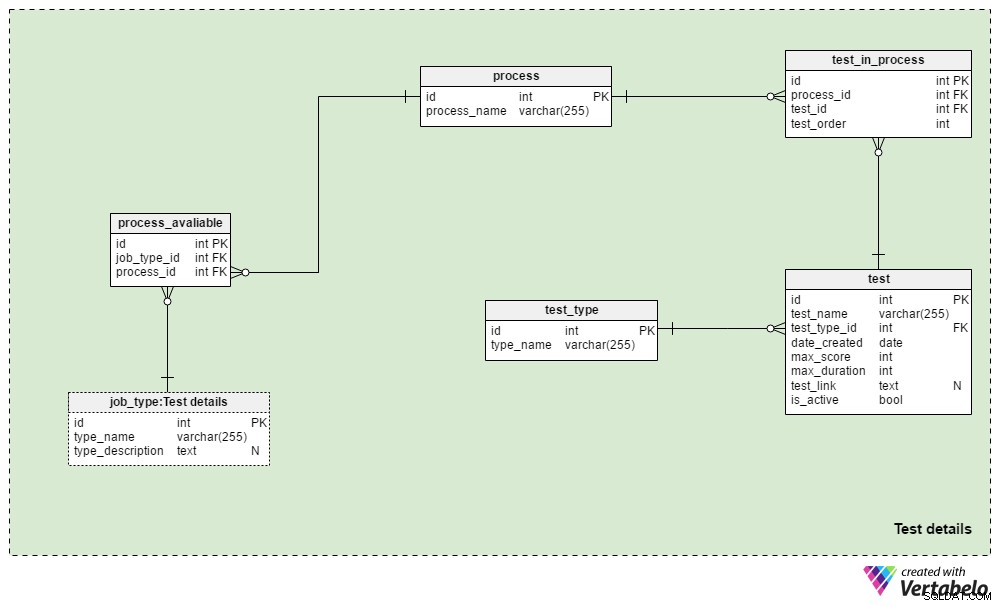
I Test details l'area tematica contiene le tabelle utilizzate per definire i processi di reclutamento e le prove utilizzate durante tali processi. In genere utilizzeremo sempre lo stesso processo di selezione per lo stesso tipo di lavoro:le modifiche vengono apportate solo quando sono richieste dalle circostanze aziendali. Potremmo utilizzare alcuni processi diversi per ogni tipo di lavoro e quasi sicuramente utilizzeremo lo stesso processo per diversi tipi di lavoro.
Il process table è un semplice dizionario contenente solo un process_name UNICO attributo. Elenca tutti i processi di reclutamento che abbiamo utilizzato e che stiamo attualmente utilizzando.
Metteremo in relazione i processi con diversi tipi di lavoro. Conserveremo queste relazioni nel process_available tavolo. I suoi unici attributi sono la coppia UNIQUE job_type_id – process_id . Quando sono disponibili più processi per un tipo di lavoro, ciò consente al reclutatore di sceglierne uno.
Il test_in_process La tabella viene utilizzata per definire l'ordine dei test durante quel processo. Gli attributi in questa tabella sono:
process_idetest_id– Fa riferimento al relativo processo e test.test_order– Il numero ordinale di quel test o fase del processo. Insieme aprocess_id, questo costituisce la chiave UNICA della tabella. Possiamo avere solo un passaggio alla volta durante il processo.
Il test la tabella elenca tutti i test attualmente e precedentemente utilizzati nel processo di reclutamento. Tratteremo anche le revisioni del CV e le interviste come test. Sebbene non necessitino di domande e risposte definite, fanno parte di una valutazione. Per ogni test memorizzeremo:
test_name– Una designazione UNICA per ogni test.test_type_id– Fa riferimento altest_typedizionario.date_created– La data in cui abbiamo creato questo test nel nostro sistema.max_score– Il punteggio massimo ottenibile per questo test. Questo valore è la somma di tutte le risposte corrette a questo test o il voto più alto che i reclutatori potrebbero dare a un CV oa un colloquio.max_duration– Quanto tempo (in minuti) il richiedente ha per completare il test.test_link– Contiene un collegamento alla posizione del test. Questo valore potrebbe essere NULL quando non utilizziamo un test nel processo.is_active– Indica se attualmente utilizziamo questo test.
Abbiamo già menzionato il test_type dizionario. Contiene tutti i nomi dei test UNICI per formato, ad es. "Revisione CV" , "test di abilità online" , "test di abilità cartaceo" e "intervista" .
Questo modello non include la struttura necessaria per memorizzare le domande e le risposte del test. Piuttosto, memorizza un collegamento alle posizioni che contengono queste informazioni. Lo stesso design verrà utilizzato nelle Applications argomento.
Sezione 4:Applicazioni
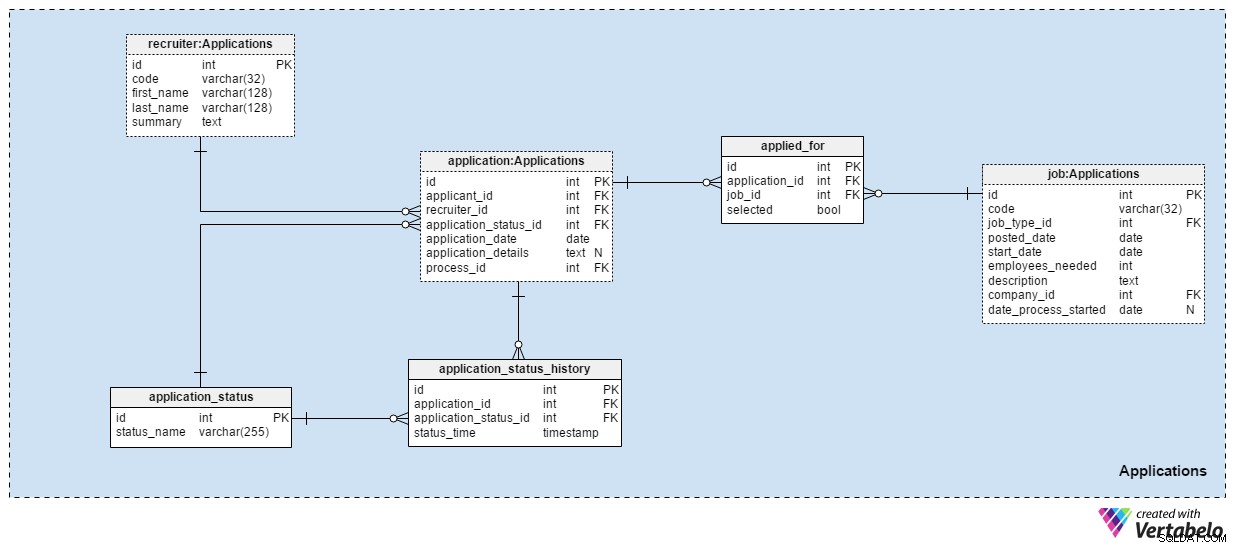
Le Applications l'area tematica è probabilmente la più importante in questo modello di dati. Tutte le altre aree tematiche menzionate finora hanno descritto le applicazioni. Questo memorizza le cose reali.
Ogni domanda che abbiamo ricevuto è registrata nella application tavolo. Per ogni domanda, memorizzeremo l'ID del candidato correlato, l'ID del reclutatore e un riferimento allo stato attuale di quella domanda. Aggiorneremo questo stato nello stesso momento in cui inseriamo una nuova voce in application_status_history tavolo. Il application_date viene utilizzato per memorizzare la data rilevante, mentre tutti i dettagli aggiuntivi sono memorizzati in formato testo. Il process_id l'attributo memorizza un riferimento al processo selezionato per quell'applicazione.
Le applicazioni cambieranno stato nel tempo. Un elenco di tutti gli stati delle applicazioni è archiviato in application_status dizionario. L'unico attributo è status_name e può contenere solo valori UNIQUE. I valori previsti includono:"applicato" , "CV esaminato" , "scelto per il test" , "rifiutato dopo la revisione del CV" , "ha superato il test" , "invitato a un colloquio" e "rinunciato dal richiedente" .
Conserveremo tutti gli stati delle applicazioni in application_status_history tavolo. Questa tabella contiene riferimenti all'application tabella e il application_status dizionario. Conserveremo anche l'esatto status_time quando questo stato è stato assegnato all'applicazione. Il application_id – status_time coppia costituisce la chiave UNICA di questa tabella.
Nella maggior parte dei casi, un candidato farà domanda per una sola posizione con una domanda. È possibile che un candidato si candidi per più di una posizione e noi sceglieremo il ruolo più adatto durante il processo di selezione. Nel applied_for tabella, memorizzeremo la coppia UNICA application_id – job_id . Registreremo anche se il richiedente correlato a tale domanda è stato selected per quella posizione. Possiamo aspettarci che tutti i selected i valori verranno impostati su "False" all'inizio del processo di selezione e che ne aggiorneremo solo uno per ogni posizione lavorativa a "Vero" .
Sezione 5:Test di applicazione
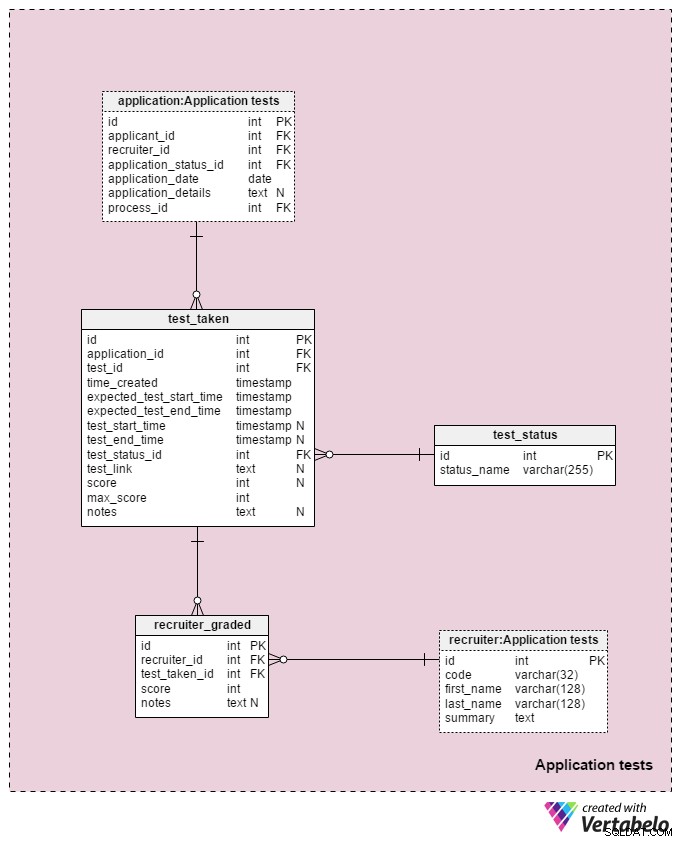
L'ultima area tematica del nostro modello verrà utilizzata per memorizzare i risultati di ogni test svolto durante il processo di selezione. Due tabelle utilizzate in questa area tematica sono copie da altre aree tematiche:application e recruiter . Vengono qui utilizzati per semplificare il modello.
Tutti i dettagli relativi a ciascun test sono memorizzati nel test_taken tavolo. Questa tabella contiene anche tutte le altre fasi del processo che potrebbero essere valutate, come una revisione del CV. Gli attributi in questa tabella sono:
application_id– Fa riferimento all'applicationtavolo. Si tratta di un test con il richiedente che lo ha sostenuto.test_id– Fa riferimento altestCatalogare. Potremmo anche fare riferimento atest_in_processtabella qui, che ci fornirebbe maggiori informazioni sul test svolto. Ho deciso di non farlo perché questa struttura ci offre maggiore flessibilità. (Ad esempio, se vogliamo consentire ai candidati di sostenere un test due volte o al di fuori degli orari abituali).time_created– L'ora effettiva in cui abbiamo inserito questo test nel nostro sistema.expected_test_start_timeeexpected_test_end_time– L'ora di inizio e di fine, come discusso con il richiedente. Potremmo modificare questi valori nel caso in cui il candidato o il selezionatore debbano posticipare il test.test_start_timeetest_end_time–Gli orari effettivi di inizio e fine del test. Questi conterranno valori NULL quando viene creato il test; i valori verranno aggiornati quando il richiedente inizia e termina questo test.test_status_id– Fa riferimento atest_statusdizionario.test_link– Link alla prova con le risposte del candidato. Verrà aggiornato al momento dell'invio del test da parte del richiedente.score– Il punteggio del richiedente in tale prova. Questo è determinato manualmente da un reclutatore (ad es. per una revisione del CV) o automaticamente (la somma di tutti i punteggi degli elementi del test). Potrebbe anche contenere un valore NULL per i test che non sono valutati o valutati su una scala predefinita. Inoltre, un test pianificato ma non ancora completato può avere un valore NULL.max_score– Il punteggio massimo raggiungibile del test. È lo stesso del valore memorizzato neltest."max_scoreattributo. Voglio mantenere quel valore perché il recruiter potrebbe modificare il test mentre viene somministrato e quindi cambiare il punteggio massimo che potrebbe essere raggiunto.notes– Eventuali note o commenti aggiuntivi inseriti dai reclutatori in merito a quel test specifico.
La combinazione di test_id – application_id – expected_test_start_time attributi costituisce la chiave UNICA di questa tabella. Prima di aggiungere una nuova sessione di test, dovremmo comunque verificare la presenza di intervalli di test sovrapposti per il candidato correlato e tutti i reclutatori correlati.
Il test_status il dizionario contiene un elenco di tutti i status_name UNIQUE che potrebbe essere assegnato a un test. Alcuni valori previsti includono:"non avviato" , "in corso" , "completato con successo" , "completato senza successo" , "rinviato" , "annullato" e "candidato annullato" .
L'ultima tabella nel nostro modello è il recruiter_graded tabella, che memorizza tutti i voti assegnati dai reclutatori durante la valutazione di ogni test. Pertanto, memorizzeremo i riferimenti al recruiter e test_taken tavoli. Conserveremo anche il score raggiunto così come eventuali notes . Questa informazione è molto importante, soprattutto quando classifichiamo i test manualmente (ad esempio per la revisione del CV e le interviste).
Oggi abbiamo discusso di un modello di dati in grado di coprire quasi tutte le situazioni nel processo di selezione e assunzione, comprese eccezioni non comuni.
La maggior parte di noi ha una certa esperienza con questo argomento. Per favore condividi la tua esperienza mentre eri nel ruolo di reclutatore o dall'altra parte della scrivania. Questo modello copre le situazioni che hai dovuto affrontare? In caso negativo, quali modifiche proporresti?