Un Database Management System è la cassaforte delle informazioni. Cercheremo di progettare il sistema di gestione del database in modo che il database rimanga ben gestito e fornisca gli scopi.
In questo articolo parleremo della progettazione e dell'amministrazione di sistemi di database di grandi dimensioni. Utilizzeremo più costituzioni che includeranno tecnologie di database, archiviazione, distribuzione dei dati, risorse del server, pattern di architettura e alcuni altri.
Preferibilmente, dovremmo cercare un database di grandi dimensioni nel dominio Telco, piattaforme di eCommerce, dominio assicurativo, sistema bancario, sanitario, sistema energetico, ecc. Prima di scegliere la giusta tecnologia di database, dobbiamo tenere a mente alcuni parametri. ovvero Traffico, TPS (Transazioni al secondo), spazio di archiviazione stimato al giorno, HA e DR.
Progettazione di un database di grandi dimensioni
Durante la costruzione del nostro database, dobbiamo prestare attenzione a diversi parametri perché spesso è molto problematico cambiare il database con un sostituto. Consideriamoli ora.
Tecnologia di database
La tecnologia dei database è il fattore principale. Se scegli il giusto sistema di gestione del database, aiuterà la tua azienda a funzionare in modo efficiente e senza sforzo.
Esistono varie tecnologie di database con molte funzionalità. Tuttavia, durante l'utilizzo di tecnologie di database open source, potresti non ottenere l'accesso ad alcune funzionalità esplicite delle soluzioni predefinite. Le tecnologie di database aziendali come Microsoft SQL Server, Oracle, ecc. le fornirebbero.
Molte tecnologie di database aziendali implementano HA (High Availability), DR (Disaster Recovery), Mirroring, Data Replication, Secondary Read Replica e soluzioni aziendali configurabili molto più convenienti e pronte. Possono essere presenti o meno nei database open source.
Ci sono molte molte ragioni. Ad esempio, a volte scopriamo che l'architettura esistente è disturbata perché i fattori sopra menzionati non sono funzionali in quanto ne abbiamo bisogno.
Archiviazione
Lo storage influisce drasticamente sulle prestazioni della soluzione aziendale. Le soluzioni aziendali richiedono storage di prim'ordine o SSD con una certa quantità di IOPS. Tuttavia, è così? On-premises o Cloud, la dimensione e il tipo di archiviazione determinano i costi dell'infrastruttura.
Considerando le prestazioni di archiviazione, è necessario prestare attenzione al tipo di dati e al comportamento dell'elaborazione dei dati. Dobbiamo optare per la selezione dell'archiviazione in base ai dati dell'utente e al loro trattamento. Se l'utente utilizzerà più database, è necessario fornire la scelta di archiviazione sulla SAN per database diversi per i tipi di dati e il comportamento di elaborazione dei dati.
L'ingegnere del database fornirà una migliore retrospezione sui vari database necessari per il calcolo IOPS se gli utenti non hanno bisogno di uno spazio di archiviazione premium.
Distribuzione dati
La maggior parte delle recenti tecnologie di database (SQL o NoSQL) offre funzionalità di partizionamento o sharding.
- La partizione ridistribuisce i dati nel file system basato sulla chiave di partizione.
- Il partizionamento orizzontale distribuisce le informazioni tra i nodi del database e i dati verrebbero archiviati nella stessa macchina o in una diversa macchina.
Fondamentalmente, ogni servizio di database o tabella di database non richiederà le funzionalità di partizionamento/sharding dei dati. Richiedono solo di essere applicati su database contenenti oggetti di dimensioni maggiori. Ciò migliorerà le prestazioni.
Risorse del server
Macchine diverse richiedono diversi tipi e dimensioni di memoria e CPU. Devi considerare le risorse a livello hardware, come memoria, processore, ecc. Ad esempio, una macchina che deve gestire database più grandi o più database avrà bisogno di più memoria e CPU. Quindi, la qualità della memoria e del processore è significativa. Gestirà diversi tipi di processori disponibili sul mercato con diverse cache della CPU.
Molte volte, ci imbattiamo in problemi di cui potremmo non essere a conoscenza. Non abbiamo prestato attenzione all'utilizzo e al ruolo della cache della CPU dell'hardware. Ma è fondamentale per selezionare e soddisfare i requisiti hardware con sistemi di database più grandi.
Modello architettonico
Nella progettazione di database, il modello Architecture ha sempre un ruolo esemplare. In precedenza, i sistemi di database erano progettati in modo estremamente monolitico. Ora utilizziamo Micro-Service based o Hybrid (Monolitico + Micro).
Le prestazioni, l'espandibilità e l'assenza di tempi di inattività dipendono molto dal modello dell'architettura e dalla progettazione del database. Ogni applicazione potrebbe avere un database separato e tutti i database potrebbero essere liberamente accoppiati tra loro. In caso di inattività di qualsiasi applicazione o database, un'altra parte del prodotto non verrà interrotta. Tutti i microservizi sarebbero indipendenti e accoppiati liberamente.
Microservizio
Il diagramma seguente spiega come tutte le applicazioni vengono distribuite e comunicano con l'aiuto dei loro database, che sono liberamente accoppiati allo stesso tempo. Possiamo manipolare i dati con T-SQL. Le informazioni verranno raccolte o accumulate da varie applicazioni e il cliente potrà accedere ai dati. Fare riferimento al diagramma con il numero di applicazioni ridimensionate e il relativo database integrato.
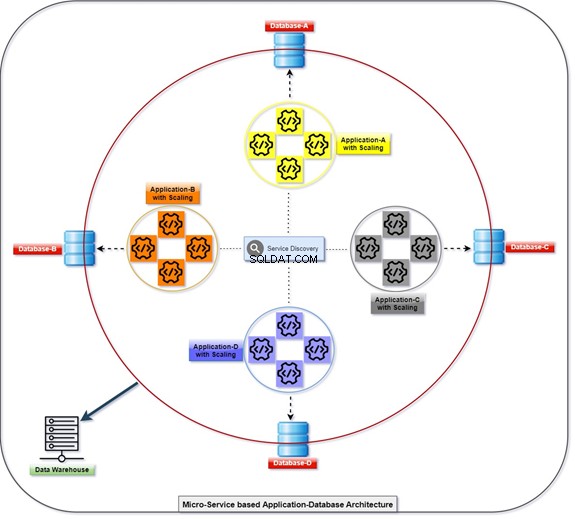
Monolitico
Quale RDBMS dovremmo usare? Potrebbe essere Oracle, Microsoft SQL Server, Postgres, MySQL, MongoDB o qualsiasi altro database. Il modo convenzionale di gestire tutte le tabelle o gli oggetti gestiti in uno o più database in un unico server è noto come Monolitico.
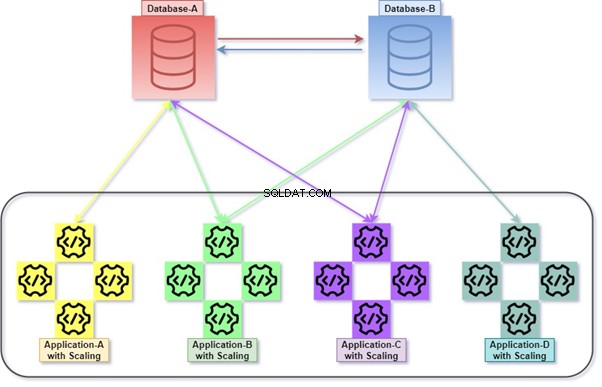
Ibrido
Hybrid è una permutazione di Monolithic e Micro Service. È una pratica abbastanza comune, poiché consente numerose applicazioni, numerosi database e server di database. Numerosi database e server di database potrebbero essere strettamente collegati tra loro.
Ad esempio, eseguire query con JOIN tra tabelle appartenenti a due o più database nello stesso server di database o in diversi. Query remota utilizzata per il recupero/manipolazione dei dati con un altro server di database.
Tutto riguarda l'architettura di SQL Server. Tuttavia, stiamo parlando della manipolazione dei dati tra tabelle diverse all'interno dello stesso database o database diversi che potrebbero risiedere sullo stesso server o server diversi.
Sia nell'architettura ibrida che monolitica, utilizziamo JOIN tra varie tabelle all'interno dello stesso database o di database diversi. È piuttosto complesso quando seguiamo gli standard di base dei microservizi perché la distribuzione delle tabelle può avvenire tra i servizi di database (Dbas).
Con le tecnologie di database Enterprise come Microsoft SQL Server, Oracle, ecc., l'utente può interrogare le tabelle del database distribuito con l'aiuto di Linked Server Joins. Ma non è disponibile in tutte le tecnologie di database open source. È noto come approccio ad accoppiamento stretto che potrebbe non funzionare quando il servizio database remoto non è disponibile.
Ora, discutiamo di renderlo slegato. Perché abbiamo bisogno della manipolazione dei dati tra database remoti?
Perché richiediamo la manipolazione dei dati tra database remoti?
Gli utenti richiederanno che i dati vengano recuperati da più di un servizio di database quando il sistema è progettato con l'aiuto di servizi micro o ibridi. L'intero processo è visto dal back-end che può gestire quantità di dati manipolate dall'applicazione.
Quando esaminiamo le query su più database in tempo reale, uniamo sempre le tabelle di entità master, non le tabelle di metadati. Le tabelle master non saranno più grandi delle tabelle di metadati. A fini di reporting, utilizziamo sempre il data warehouse per raccogliere tutte le informazioni. Ma non è facile da gestire e mantenere per ogni prodotto. Se progettiamo la soluzione aziendale, possiamo permetterci il magazzino. Ma non possiamo permettercelo per prodotti di piccole o medie dimensioni.
Ad esempio, abbiamo bisogno di un report con i dati di diverse tabelle che risiedono in database diversi. Non è un'operazione facile da eseguire, poiché raccoglie i dati utilizzando diversi microservizi e li unisce per produrre il report. Pertanto, i dati necessari devono essere sincronizzati.
Cosa possiamo utilizzare come soluzione standard eseguire la sincronizzazione dei dati di tabelle ad accoppiamento libero tra due database?
La replica delle tabelle deve essere utilizzata per una semplice sincronizzazione dei dati tra più database. L'esempio è la replica delle transazioni per la sincronizzazione dei dati Simplex e la Merge Replication per la sincronizzazione dei dati Duplex fornita da SQL Server.
Esistono alcune soluzioni open source e di terze parti a pagamento in grado di sincronizzare i dati tra più database. Anche soluzioni ad accoppiamento libero con l'aiuto di code di messaggi come SQL Server Transaction Replication possono essere sviluppate dagli utenti autonomamente.
Conclusione
I DBA progettano database a modo loro. Durante l'architettura del database e la scelta del sistema di gestione del database, devono tenere a mente molti aspetti. Abbiamo presentato i fattori più essenziali per la progettazione del database, in particolare per i database di dimensioni maggiori. Resta sintonizzato per i prossimi materiali!