In genere, è consigliabile inserire vincoli univoci su una tabella per evitare righe duplicate. Tuttavia, potresti trovarti a lavorare con un database in cui sono state create righe duplicate a causa di un errore umano, un bug nell'applicazione o dati non puliti da fonti esterne. Questo tutorial ti insegnerà come trovare queste righe duplicate.
Per continuare, avrai bisogno dell'accesso in lettura al tuo database e di uno strumento per interrogare il tuo database.
Identifica criteri duplicati
Il primo passaggio consiste nel definire i criteri per una riga duplicata. Hai bisogno di una combinazione di due colonne per essere univoche insieme o stai semplicemente cercando duplicati in una singola colonna? In questo esempio, stiamo cercando duplicati su due colonne nella nostra tabella Utenti:nome utente ed e-mail.
Scrivi query per verificare l'esistenza di duplicati
La prima query che scriveremo è una semplice query per verificare se esistono effettivamente duplicati nella tabella. Per il nostro esempio, la mia query è simile a questa:
SELECT username, email, COUNT(*)
FROM users
GROUP BY username, email
HAVING COUNT(*) > 1
HAVING è importante qui perché a differenza di WHERE , HAVING filtri sulle funzioni aggregate.
Se vengono restituite righe, significa che abbiamo dei duplicati. In questo esempio, i nostri risultati si presentano così:
| nome utente | conta | |
|---|---|---|
| Pietro | pete@example.com | 2 |
| Jessica | jessica@example.com | 2 |
| Miglia | miglia@example.com | 2 |
Elenca tutte le righe contenenti duplicati
Nel passaggio precedente, la nostra query ha restituito un elenco di duplicati. Ora, vogliamo restituire l'intero record per ogni riga duplicata.
Per fare ciò, dovremo selezionare l'intera tabella e unirla alle nostre righe duplicate. La nostra query è simile a questa:
SELECT a.*
FROM users a
JOIN (SELECT username, email, COUNT(*)
FROM users
GROUP BY username, email
HAVING count(*) > 1 ) b
ON a.username = b.username
AND a.email = b.email
ORDER BY a.email
Se guardi da vicino, vedrai che questa query non è così complicata. L'iniziale SELECT seleziona semplicemente ogni colonna nella tabella degli utenti, quindi inner la unisce alla tabella di dati duplicata dalla nostra query iniziale. Poiché stiamo unendo la tabella a se stessa, è necessario utilizzare degli alias (qui stiamo usando aeb) per etichettare le due versioni.
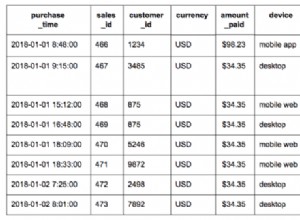
Ecco come appaiono i nostri risultati per questa query:
| id | nome utente | |
|---|---|---|
| 1 | Pietro | pete@example.com |
| 6 | Pietro | pete@example.com |
| 12 | Jessica | jessica@example.com |
| 13 | Jessica | jessica@example.com |
| 2 | Miglia | miglia@example.com |
| 9 | Miglia | miglia@example.com |
Poiché questo set di risultati include tutti gli ID riga, possiamo usarlo per aiutarci a deduplicare le righe in un secondo momento.