Ebbene, analizzare la diffusione del coronavirus SARS-CoV-2 non è stato il caso d'uso dei miei sogni . Ma sulla base delle risposte all'articolo Tracking Coronavirus COVID-19 Near Real Time with SAP HANA XSA di Ferry Djaja, ho deciso di aggiungere anche i miei due groszy.
[Aggiornato il 20-03-30 con i link modificati ai dati di origine; e il nuovo output della mappa basato sulla nuova granularità dei dati. Grazie Douglas Maltby per il tuo commento!]
Nel suo post sul blog, Ferry ha utilizzato JavaScript in SAP HANA XSA per estrarre i dati dai file CSV aggiornati quotidianamente dalla Johns Hopkins University.
Vorrei mostrarvi come estrapolare e caricare questi file in SAP HANA utilizzando solo poche righe di codice grazie a SAP HANA Python Client API for Machine Learning (hana_ml pacchetto).
Alcune persone erano confuse con la visualizzazione sulla mappa alla fine:tieni presente che questo articolo si concentra sul caso d'uso tecnico che collega diversi componenti, non sull'analisi approfondita dei dati del coronavirus.
Ottieni l'ambiente Python, ad es. Giove
Userò Jupyter nel contenitore Docker per quello. Dai un'occhiata al mio post precedente Capire i contenitori (parte 05):file condivisi tra l'host e i contenitori se non hai familiarità con come avviarlo. Inoltre puoi eseguire tutti gli stessi passaggi di seguito da qualsiasi altro ambiente Python.
Quindi, ho il mio contenitore myjupyter01 in esecuzione. Sono connesso all'interfaccia utente di Jupyter come descritto nel blog precedente.
Installa hana_ml
L'immagine Jupyter che ho usato dal registro Docker Hub era jupyter/minimal-notebook . Contiene già alcuni popolari pacchetti di elaborazione dati, come pandas .
Ma in aggiunta, devo installare hana_ml , che — nella sua attuale versione 1.0.8 — è disponibile nel repository PyPI:https://pypi.org/project/hana-ml/.
Il comando per eseguire l'installazione è python -m pip install hana_ml , ma poiché lo eseguo dal notebook Jupyter con il kernel Python3, devo eseguirlo con ! all'inizio:
!python -m pip install hana_ml
Ovviamente, questa fase di installazione deve essere eseguita una sola volta. Non è necessario rieseguirlo nello stesso contenitore, ad es. quando si ricaricano i file più recenti.
Usa pandas per importare file con dati
Importiamo gli stessi tre file (confirmed , deaths , recovered ) da https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series come Ferry utilizzato nel suo esempio.
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
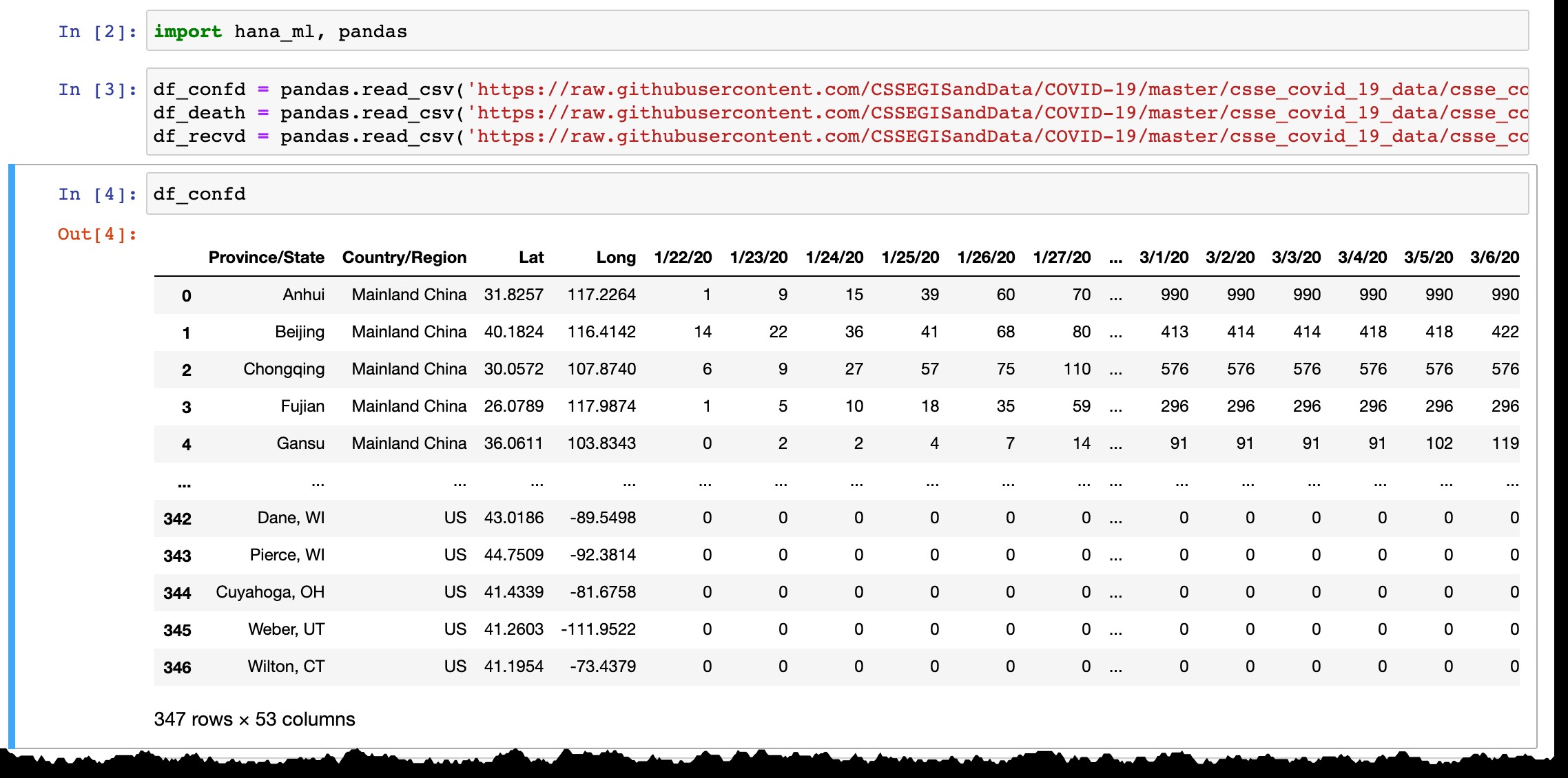
Come puoi vedere dall'anteprima del dataframe Pandas, elenca solo i paesi o le province con casi confermati e ogni giorno viene aggiunta la nuova colonna con gli ultimi dati del giorno precedente. Le righe vengono aggiunte quando i primi casi vengono confermati nella nuova regione.
Usa pandas per riformattare il frame di dati
Prima di rendere persistenti i dati in SAP HANA, procediamo:
- Rimuovi tutte le colonne della data tranne l'ultima,
- Rinomina l'ultima colonna dalla data effettiva (come il
3/10/20di oggi aConfirmed).
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
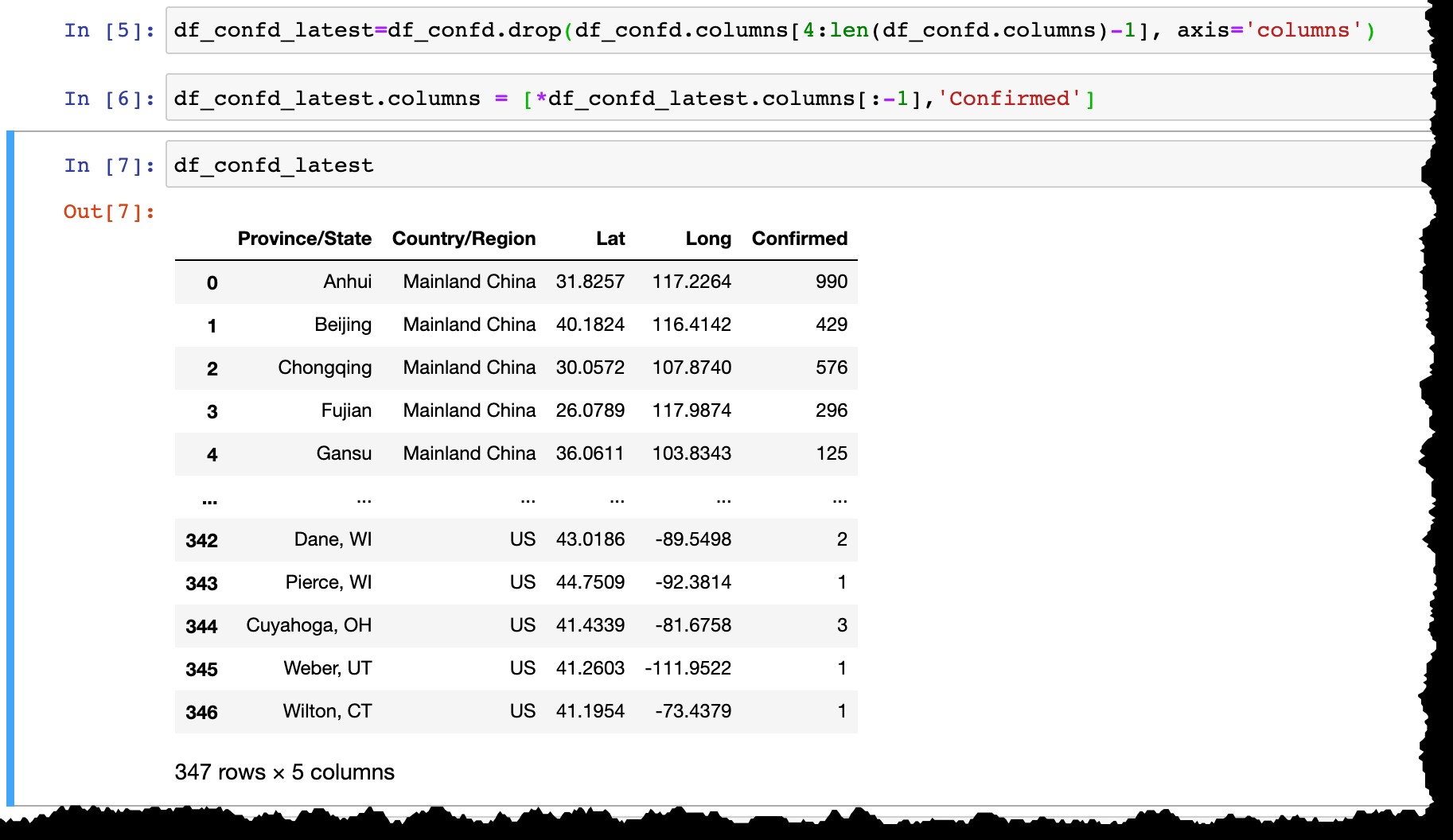
Usa hana_ml per rendere persistenti i dati nella tabella SAP HANA
Ora permettetemi di connettermi alla mia istanza di SAP HANA Express con l'utente hanaml che esiste già lì…
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
... e converti il dataframe Pandas df_confd_latest in un dataframe HANA hdf_confd .
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
Una volta creato il dataframe HANA:
- In HANA viene creata una tabella di colonna fisica e lì vengono inseriti i dati del dataframe di Pandas
- frame di dati HANA
hdf_confdin Python non memorizza alcun dato nel tuo laptop, ma punta solo a una tabellaHANAML.df_confdnella memoria del server SAP HANA e tutte le operazioni Python sul dataframe HANA vengono eseguite fisicamente in HANA db senza spostare i dati tra il server e un client, - Per visualizzare il risultato di qualsiasi operazione, dobbiamo applicare
collect()metodo per convertire dataframe HANA in Panda (e, di conseguenza, per portare i dati dal server db HANA al client locale).
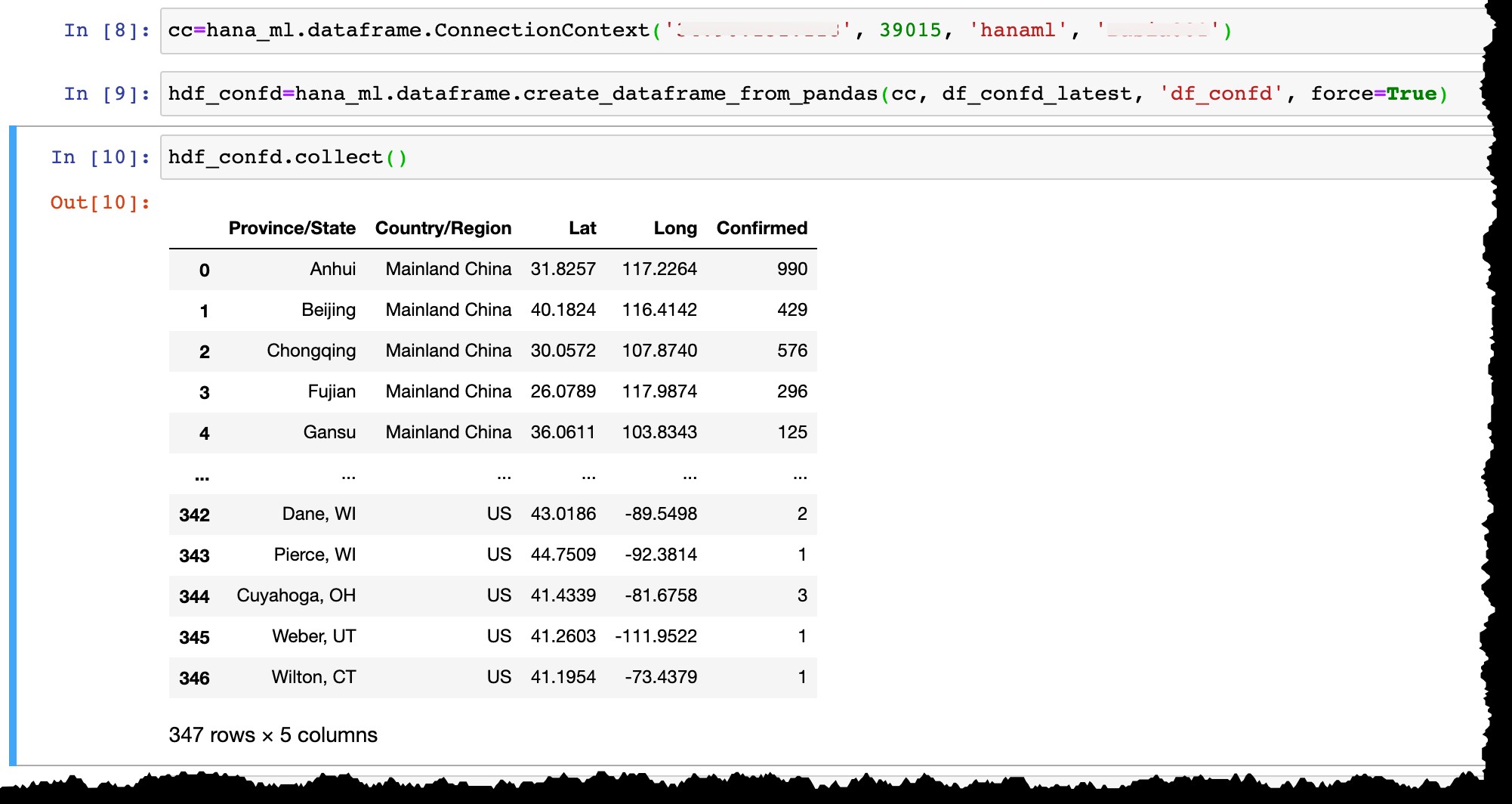
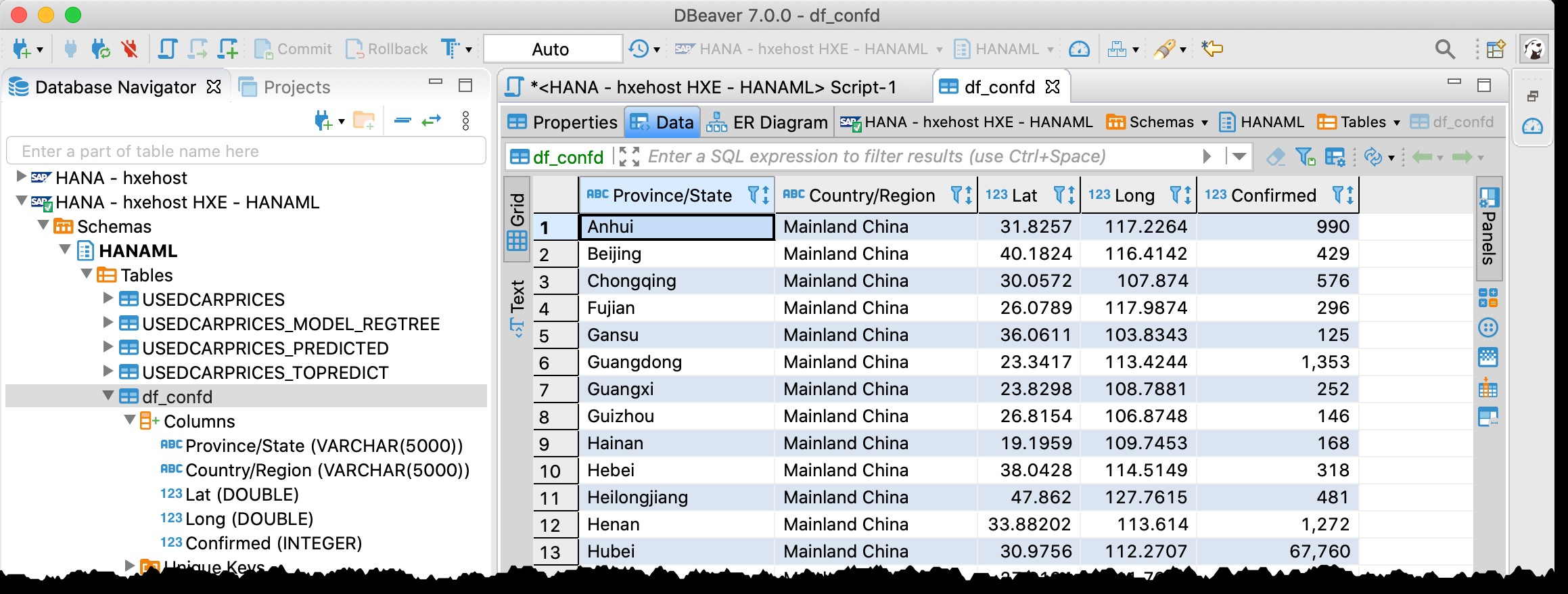
Utilizzare DBeaver per controllare i dati in SAP HANA...
Potresti ricordarti che usavo già DBeaver, lo strumento di database gratuito che supporta SAP HANA, nel mio post precedente "GeoArt con SAP HANA e DBeaver".
Lo sto usando di nuovo ora e in effetti riesco a trovare la tabella df_confd nello schema HANAML con tutti i dati dal dataframe Pandas di origine.
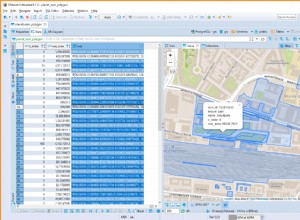
... e fai un'anteprima spaziale
Poiché la tabella contiene colonne di latitudine e longitudine, posso visualizzare i paesi/stati interessati direttamente da DBeaver con il seguente SQL utilizzando l'anteprima dei dati spaziali.
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
Avevo bisogno di cambiare la proiezione della mappa in EPSG:4326 per ottenere questi punti sulla mappa. E DBeaver mi mostra il resto dei dati del record quando faccio clic su un punto qualsiasi.
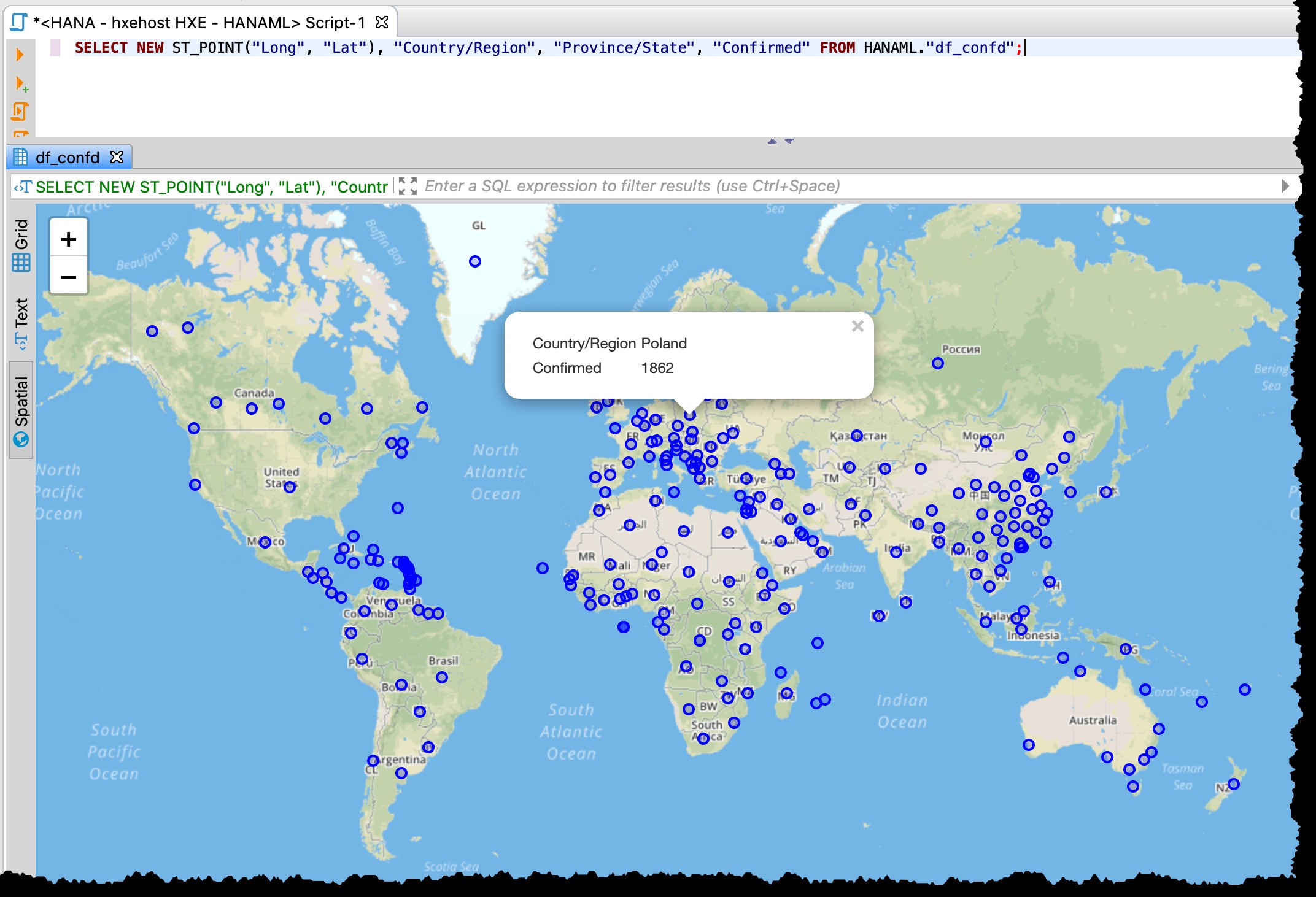
[Sotto è il vecchio screenshot dell'11-03-2020, che mostra anche la diversa granularità di ad es. Dati USA utilizzati in quel momento]
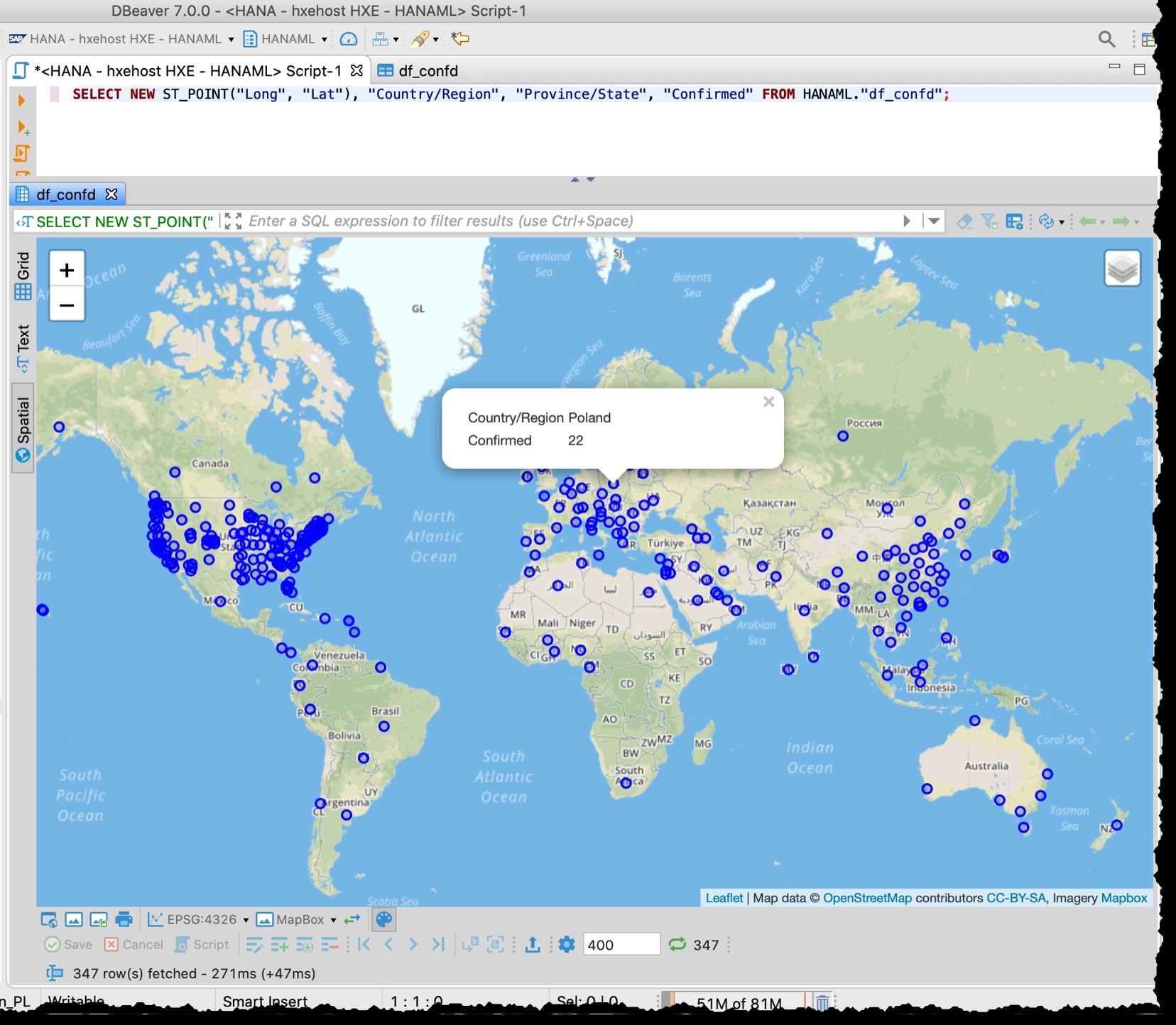
L'anteprima spaziale di DBeaver non è uno strumento di esplorazione visiva geospaziale completo. Eppure è abbastanza buono vedere i paesi/regioni interessati (a seconda della granularità nei file di origine).
Se sei interessato a saperne di più su hana_ml …
... quindi consiglierei sicuramente di controllare esercitazione pratica:Machine Learning push-down su SAP HANA con Python di Andreas Forster.
HANA ML fa parte del nuovo argomento "Analisi avanzata con SAP HANA" per gli eventi CodeJam. Purtroppo a causa della situazione del coronavirus, questo mese abbiamo dovuto annullare il primo organizzato da Jakob Flaman a Berna. Un altro è organizzato da Ewelina Pękała il 27 maggio a Katowice:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417. Speriamo che la situazione diventi normale a quel punto e non dovremo cancellare anche questo.