Visto che stai usando la primavera. Puoi usare MultipartFile per ottenere il file nel controller e quindi utilizzare Binary di org.bson per archiviare il file in MongoDB , se la dimensione dell'immagine è <16 MB (se la dimensione dell'immagine è> 16 MB è possibile utilizzare GridF
).
Devi aggiungere solo una dipendenza al tuo progetto:spring-data-mongoDB
Prendiamo un esempio di una raccolta di utenti che assomiglia a questa:
@Document
public class User {
@Id
private String id;
private String name;
private Binary image;
// getters and setters
}
Qui puoi vedere Binary image che rappresenta il tuo file immagine.
Ora crea un repository per questa raccolta di utenti utilizzando MongoRepository
public interface UserRepository extends MongoRepository<User, String>{
}
Crea un controller a scopo dimostrativo. Usa @RequestParam MultipartFile file per ottenere il file nel controller, ottenere i byte dal file e impostarlo sull'oggetto utente user.setImage(new Binary(file.getBytes())); l'esempio completo è di seguito:
@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping("/users")
User createUser(@RequestParam String name, @RequestParam MultipartFile file) throws IOException {
User user = new User();
user.setName(name);
user.setImage(new Binary(file.getBytes()));
return userRepository.save(user);
}
@GetMapping("/users")
String getImage(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
Encoder encoder = Base64.getEncoder();
return encoder.encodeToString(user.get().getImage().getData());
}
}
Avvia il server e raggiungi il punto finale come mostrato nella schermata del postino sotto
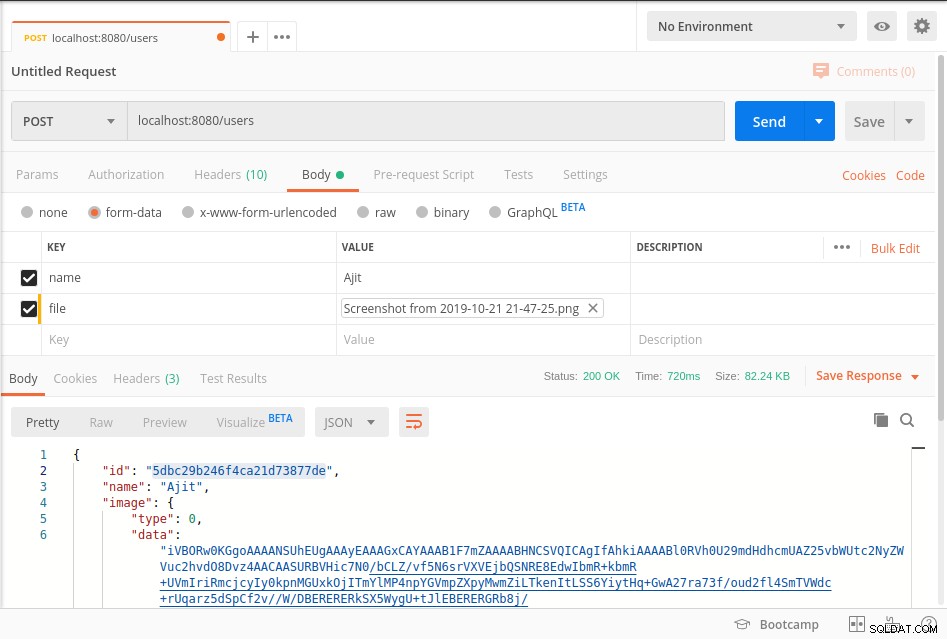
I tuoi dati sono archiviati in mongoDb in BinData format e per ottenere i dati dal database fare riferimento a getImage metodo del codice sopra.
MODIFICA:
Il richiedente sta usando tess4j libreria per estrarre testo da immagine e doOCR è un metodo in questa libreria. Ho seguito questi passaggi per estrarre il testo dall'immagine nella mia applicazione di avvio primaverile.
-
Installa
tesseract-ocrnel tuo sistema:sudo apt-get install tesseract-ocr -
Scarica
eng.traineddatadati di formazione da https://github.com/tesseract-ocr/tessdata e spostalo nella cartella principale del progetto. -
Aggiungi di seguito la dipendenza al tuo progetto:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
- Aggiungi il codice seguente al progetto esistente:
@GetMapping("/image-text")
String getImageText(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
ITesseract instance = new Tesseract();
try {
ByteArrayInputStream bais = new ByteArrayInputStream(user.get().getImage().getData());
BufferedImage bufferImg = ImageIO.read(bais);
String imgText = instance.doOCR(bufferImg);
return imgText;
} catch (Exception e) {
return "Error while reading image";
}
}