Il failover automatico per MySQL Replication è oggetto di dibattito da molti anni.
È un bene o un male?
Per coloro che hanno una memoria lunga nel mondo MySQL, potrebbero ricordare l'interruzione di GitHub nel 2012, causata principalmente dal software che ha preso decisioni sbagliate.
GitHub era appena migrato a una combinazione di MySQL Replication, Corosync, Pacemaker e Percona Replication Manager. PRM ha deciso di eseguire un failover dopo aver fallito i controlli di integrità sul master, che è stato sovraccaricato durante una migrazione dello schema. È stato selezionato un nuovo master, ma ha funzionato male a causa delle cold cache. L'elevato carico di query dal sito occupato ha causato un nuovo errore degli heartbeat PRM sul master freddo e il PRM ha quindi attivato un altro failover sul master originale. E i problemi continuavano, come riassunto di seguito.
 Fonte:Henrik Ingo &Massimo Brignoli's al Percona Live 2013
Fonte:Henrik Ingo &Massimo Brignoli's al Percona Live 2013 Avanti veloce di un paio d'anni e GitHub è tornato con un framework piuttosto sofisticato per la gestione della replica MySQL e il failover automatizzato! Come dice Shlomi Noach:
“A tal fine, utilizziamo failover master automatizzati. Il tempo impiegato da un essere umano per svegliare e riparare un master guasto è al di là delle nostre aspettative di disponibilità e l'esecuzione di un tale failover a volte non è banale. Prevediamo che gli errori master vengano rilevati e ripristinati automaticamente entro 30 secondi o meno e prevediamo che il failover comporti una perdita minima di host disponibili".
La maggior parte delle aziende non sono GitHub, ma si potrebbe obiettare che a nessuna azienda piacciono le interruzioni. Le interruzioni sono dirompenti per qualsiasi attività commerciale e costano anche denaro. La mia ipotesi è che la maggior parte delle aziende probabilmente desiderasse avere una sorta di failover automatizzato e le ragioni per non implementarlo sono probabilmente la complessità delle soluzioni esistenti, la mancanza di competenza nell'implementazione di tali soluzioni o la mancanza di fiducia nel software da adottare una decisione così importante.
Esistono numerose soluzioni di failover automatizzate, inclusi (e non limitati a) MHA, MMM, MRM, mysqlfailover, Orchestrator e ClusterControl. Alcuni sono sul mercato da diversi anni, altri sono più recenti. Questo è un buon segno, più soluzioni significano che il mercato è presente e le persone stanno cercando di affrontare il problema.
Quando abbiamo progettato il failover automatico all'interno di ClusterControl, abbiamo utilizzato alcuni principi guida:
-
Assicurati che il master sia davvero morto prima di eseguire il failover
Nel caso di una partizione di rete, in cui il software di failover perde il contatto con il master, smetterà di vederlo. Ma il master potrebbe funzionare bene e può essere visto dal resto della topologia di replica.
ClusterControl raccoglie le informazioni da tutti i nodi del database, nonché da qualsiasi proxy di database/bilanciatore di carico utilizzato, quindi crea una rappresentazione della topologia. Non tenterà un failover se gli slave possono vedere il master, né se ClusterControl non è sicuro al 100% dello stato del master.
ClusterControl consente inoltre di visualizzare facilmente la topologia dell'installazione, nonché lo stato dei diversi nodi (questa è la comprensione da parte di ClusterControl dello stato del sistema, in base alle informazioni che raccoglie).
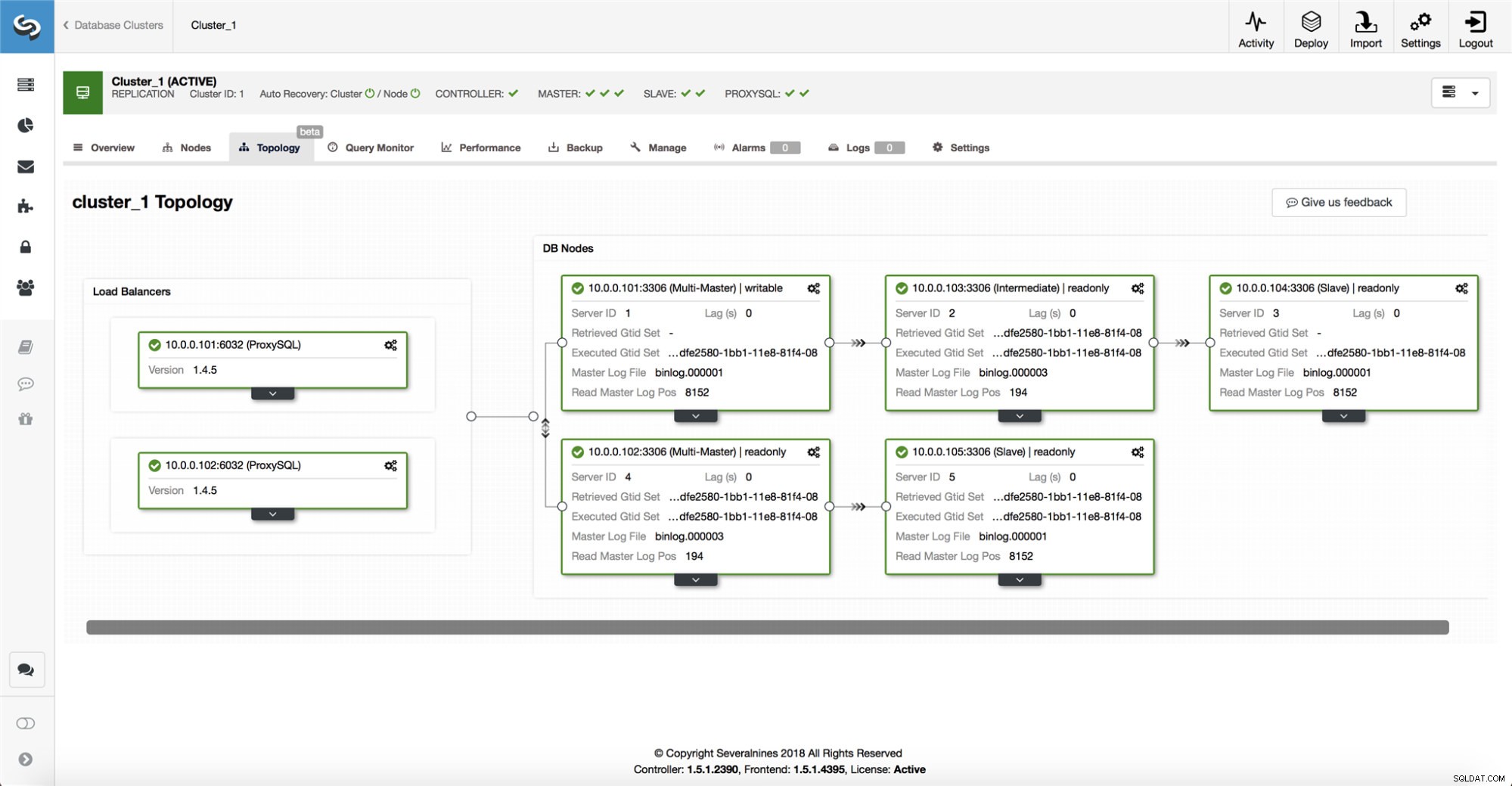
-
Failover solo una volta
Molto è stato scritto sullo sbattimento. Può diventare molto disordinato se lo strumento di disponibilità decide di eseguire più failover. È una situazione pericolosa. Ciascun master eletto, per quanto breve sia il periodo in cui ha ricoperto il ruolo di master, potrebbe avere le proprie serie di modifiche che non sono mai state replicate su nessun server. Quindi potresti finire con l'incoerenza tra tutti i maestri eletti.
-
Non eseguire il failover su uno slave incoerente
Quando si seleziona uno slave da promuovere come master, ci assicuriamo che lo slave non presenti incongruenze, ad es. transazioni errate, in quanto ciò potrebbe interrompere la replica.
-
Scrivi solo al maestro
La replica va dal master agli slave. Scrivere direttamente su uno schiavo creerebbe un set di dati divergente e ciò può essere una potenziale fonte di problemi. Impostiamo gli slave su read_only e super_read_only nelle versioni più recenti di MySQL o MariaDB. Consigliamo inoltre l'uso di un sistema di bilanciamento del carico, ad esempio ProxySQL o MaxScale, per proteggere il livello dell'applicazione dalla topologia del database sottostante e da eventuali modifiche ad essa. Il sistema di bilanciamento del carico applica anche le scritture sul master corrente.
-
Non recuperare automaticamente il master fallito
Se il master è guasto ed è stato scelto un nuovo master, ClusterControl non tenterà di recuperare il master guasto. Come mai? Quel server potrebbe avere dati che non sono stati ancora replicati e l'amministratore dovrebbe eseguire alcune indagini sull'errore. Ok, puoi ancora configurare ClusterControl per cancellare i dati sul master guasto e farlo unire come slave al nuovo master, se sei d'accordo con la perdita di alcuni dati. Ma per impostazione predefinita, ClusterControl lascerà essere il master fallito, finché qualcuno non lo guarderà e deciderà di reintrodurlo nella topologia.
Quindi, dovresti automatizzare il failover? Dipende da come hai configurato la replica. Le configurazioni di replica circolare con più master scrivibili o topologie complesse probabilmente non sono buoni candidati per il failover automatico. Ci atteniamo ai principi di cui sopra durante la progettazione di una soluzione di replica.
Su PostgreSQL
Quando si tratta di replica in streaming PostgreSQL, ClusterControl utilizza principi simili per automatizzare il failover. Per PostgreSQL, ClusterControl supporta modelli di replica sia asincroni che sincroni tra il master e gli slave. In entrambi i casi e in caso di guasto viene eletto nuovo master lo slave con i dati più aggiornati. I master non riusciti non vengono ripristinati/corretti automaticamente per rientrare nella configurazione della replica.
Ci sono alcune misure protettive adottate per assicurarsi che il master fallito sia a terra e rimanga giù, ad es. viene rimosso dal set di bilanciamento del carico nel proxy e viene ucciso se ad es. l'utente lo riavvierà manualmente. È un po' più difficile rilevare le divisioni di rete tra ClusterControl e il master, poiché gli slave non forniscono alcuna informazione sullo stato del master da cui stanno replicando. Quindi un proxy davanti alla configurazione del database è importante in quanto può fornire un altro percorso al master.
Su MongoDB
La replica di MongoDB all'interno di un set di repliche tramite l'oplog è molto simile alla replica di binlog, quindi come mai MongoDB recupera automaticamente un master guasto? Il problema persiste e MongoDB lo risolve annullando tutte le modifiche che non sono state replicate sugli slave al momento dell'errore. Tali dati vengono rimossi e inseriti in una cartella di "ripristino", quindi spetta all'amministratore ripristinarli.
Per saperne di più, controlla ClusterControl; e sentiti libero di commentare o porre domande di seguito.



