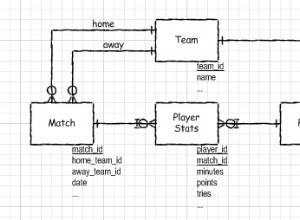
Le colonne Intero/Identità vengono spesso utilizzate per le chiavi primarie nelle tabelle del database per una serie di motivi. Le colonne della chiave primaria devono essere univoche, non aggiornabili e in realtà dovrebbero essere prive di significato. Ciò rende una colonna di identità una scelta piuttosto buona perché il server otterrà il valore successivo per te, devono essere univoci e gli interi sono relativamente piccoli e utilizzabili (rispetto a un GUID).
Alcuni architetti di database sosterranno che altri tipi di dati dovrebbero essere utilizzati per i valori delle chiavi primarie e che i criteri "senza significato" e "non aggiornabile" possono essere argomentati in modo convincente da entrambe le parti. Indipendentemente da ciò, i campi intero/identità sono piuttosto convenienti e molti progettisti di database ritengono che creino valori chiave adeguati per l'integrità referenziale.
- La scelta migliore per la chiave primaria sono i tipi di dati interi poiché i valori interi vengono elaborati più velocemente dei valori dei tipi di dati carattere. Un tipo di dati carattere (come chiave primaria) deve essere convertito in valori equivalenti ASCII prima dell'elaborazione.
- Il recupero del record sulla base della chiave primaria sarà più rapido in caso di numeri interi come chiavi primarie poiché ciò significherà che saranno presenti più record dell'indice su una singola pagina. Quindi il tempo totale di ricerca diminuisce. Anche i join saranno più veloci. Ma questo sarà applicabile nel caso in cui la tua query utilizzi la ricerca dell'indice cluster e non la scansione e se viene utilizzata solo una tabella. Nel caso in cui la scansione non abbia una colonna aggiuntiva significherà più righe su una pagina di dati.
Spero che questo ti aiuterà!