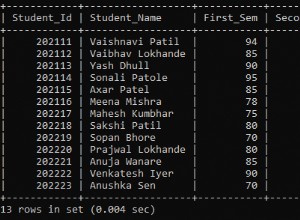
Le parole sono piuttosto logiche e le imparerai abbastanza velocemente. :)
In parole povere, SEEK implica la ricerca di posizioni precise per i record, che è ciò che fa SQL Server quando la colonna in cui stai cercando è indicizzata e il tuo filtro (la condizione WHERE) è sufficientemente accurato.
SCAN significa un intervallo più ampio di righe in cui il pianificatore dell'esecuzione della query stima che sia più veloce recuperare un intero intervallo anziché cercare singolarmente ogni valore.
E sì, puoi avere più indici sullo stesso campo e, a volte, può essere un'ottima idea. Gioca con gli indici e usa il pianificatore di esecuzione delle query per determinare cosa succede (scorciatoia in SSMS:Ctrl + M). Puoi anche eseguire due versioni della stessa query e il pianificatore di esecuzione ti mostrerà facilmente quante risorse e quante tempo sono impiegate da ciascuna, rendendo l'ottimizzazione abbastanza semplice.
Ma per ampliarli un po', supponiamo di avere una tabella di indirizzi del genere e che abbia oltre 1 miliardo di record:
CREATE TABLE ADDRESS
(ADDRESS_ID INT -- CLUSTERED primary key ADRESS_PK_IDX
, PERSON_ID INT -- FOREIGN KEY, NONCLUSTERED INDEX ADDRESS_PERSON_IDX
, CITY VARCHAR(256)
, MARKED_FOR_CHECKUP BIT
, **+n^10 different other columns...**)
Ora, se vuoi trovare tutte le informazioni sull'indirizzo per la persona 12345, l'indice su PERSON_ID è perfetto. Poiché la tabella contiene molti altri dati sulla stessa riga, sarebbe inefficiente e dispendioso in termini di spazio creare un indice non cluster per coprire tutte le altre colonne oltre a PERSON_ID. In questo caso, SQL Server eseguirà un indice SEEK sull'indice in PERSON_ID, quindi lo utilizzerà per eseguire una ricerca chiave nell'indice cluster in ADDRESS_ID e da lì restituirà tutti i dati in tutte le altre colonne sulla stessa riga.
Tuttavia, supponi di voler cercare tutte le persone in una città, ma non hai bisogno di altre informazioni sull'indirizzo. Questa volta, il modo più efficace sarebbe creare un indice su CITY e utilizzare l'opzione INCLUDE per coprire anche PERSON_ID. In questo modo, una singola ricerca/scansione dell'indice restituirebbe tutte le informazioni necessarie senza dover ricorrere al controllo dell'indice CLUSTERED per i dati PERSON_ID sulla stessa riga.
Ora, diciamo che entrambe le query sono necessarie ma ancora piuttosto pesanti a causa del miliardo di record. Ma c'è una query speciale che deve essere davvero molto veloce. Quella richiesta vuole tutte le persone sugli indirizzi che sono stati MARKED_FOR_CHECKUP e che devono vivere a New York (ignora qualunque cosa significhi il controllo, non importa). Ora potresti voler creare un terzo indice filtrato su MARKED_FOR_CHECKUP e CITY, con INCLUDE che copre PERSON_ID e con un filtro che dice CITY ='New York' e MARKED_FOR_CHECKUP =1. Questo indice sarebbe incredibilmente veloce, poiché copre solo le query che soddisfano quelle condizioni esatte, e quindi ha una frazione dei dati da esaminare rispetto agli altri indici.
(Disclaimer qui, tieni presente che il pianificatore di esecuzione delle query non è stupido, può utilizzare più indici non cluster insieme per produrre i risultati corretti, quindi gli esempi sopra potrebbero non essere i migliori disponibili poiché è molto difficile immaginare quando ne avresti bisogno 3 diversi indici che coprono la stessa colonna, ma sono sicuro che ti sei fatto un'idea.)
I tipi di indice, le loro colonne, le colonne incluse, gli ordini di ordinamento, i filtri, ecc. dipendono interamente dalla situazione. Dovrai creare indici di copertura per soddisfare diversi tipi di query, nonché indici personalizzati creati appositamente per query singolari e importanti. Ogni indice occupa spazio sull'HDD, quindi creare indici inutili è uno spreco e richiede una manutenzione aggiuntiva ogni volta che il modello di dati cambia e fa perdere tempo nelle operazioni di deframmentazione e aggiornamento delle statistiche però... quindi non vuoi semplicemente schiaffeggiare un indice su tutto neanche.
Sperimenta, impara e scopri quale funziona meglio per le tue esigenze.