Spero di aver capito bene. Quindi lo ripeto.
- Hai 1 tabella con molte voci
- Hai questo elenco da Excel dove cerchi la "colonna di ricerca"
- In caso di corrispondenza, sostituisci l'intero valore con "sostituisci colonna"
Se questo è il caso, allora questa potrebbe essere la soluzione:
declare @data table (Column1 nvarchar(50))
insert into @data
(Column1)
values (N'RbC investment for Seniors 65+'),
(N'RBC inv for juniors')
declare @replace table
(
OriginalValue nvarchar(50),
NewValue nvarchar(50),
[priority] int
)
insert into @replace
(OriginalValue, NewValue, [priority])
values (N'rbc inv', N'RBC dominion securities', 2),
(N'rbc dom', N'RBC dominion securities', 2),
(N'RBC', N'RBC Bank', 3)
update @data
set Column1 = coalesce((
select top 1
NewValue
from @replace
where Column1 like '%' + OriginalValue + '%'
order by [priority]
), Column1)
select *
from @data
La tabella "dati" sarebbe quella in cui esegui la sostituzione.
Ci possono essere alcuni effetti collaterali usando quello (ad es. caratteri jolly come % in "search_column", forse più corrispondenze - in questo momento ne viene presa una "casuale", le prestazioni potrebbero non essere le migliori, ...) Ma suppongo per una risposta più precisa mi servirebbe una domanda migliore.
Modifica:
Grazie a Ralph... ho aggiunto una priorità alla tabella "replace" per poter gestire le corrispondenze duplicate.
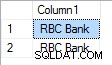
Nel caso in cui "RBC" abbia priorità 3 il risultato è:
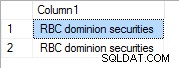
Con priorità 1 è: