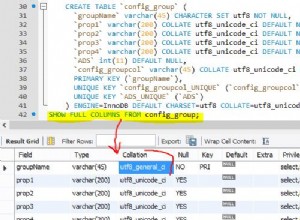
L'ottimizzatore di SQL Server contiene la logica per rimuovere i join ridondanti, ma ci sono delle restrizioni e i join devono essere probabilmente ridondante . Per riassumere, un join può avere quattro effetti:
- Può aggiungere colonne extra (dalla tabella unita)
- Può aggiungere righe extra (la tabella unita potrebbe corrispondere a una riga di origine più di una volta)
- Può rimuovere righe (la tabella unita potrebbe non avere una corrispondenza)
- Può introdurre
NULLs (per unRIGHToFULL JOIN)
Per rimuovere correttamente un join ridondante, la query (o vista) deve tenere conto di tutte e quattro le possibilità. Quando questo è fatto, correttamente, l'effetto può essere sorprendente. Ad esempio:
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID
L'ottimizzatore può semplificare con successo la seguente query:
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';
A:

Rob Farley ha scritto in modo approfondito queste idee nel libro originale MVP Deep Dives , e c'è una registrazione della sua presentazione sull'argomento in SQLBit.
Le principali restrizioni sono che le relazioni di chiave esterna devono essere basati su un'unica chiave per contribuire al processo di semplificazione, e il tempo di compilazione delle query relative a tale vista può diventare piuttosto lungo, soprattutto con l'aumento del numero di join. Potrebbe essere una vera sfida scrivere una vista a 100 tabelle che ottenga tutta la semantica esattamente corretta. Sarei propenso a trovare una soluzione alternativa, magari utilizzando SQL dinamico .
Detto questo, le qualità particolari della tua tabella denormalizzata possono significare che la vista è abbastanza semplice da assemblare, richiedendo solo FOREIGN KEYs forzate non NULL colonne di riferimento abili e UNIQUE appropriato vincoli per far funzionare questa soluzione come speri, senza il sovraccarico di 100 operatori di join fisici nel piano.
Esempio
Utilizzando dieci tabelle anziché cento:
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
La definizione della tabella padre (con compressione della pagina):
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);
La vista:
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;
Hackera le statistiche per far pensare all'ottimizzatore che la tabella sia molto grande:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;
Esempio di query utente:
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';
Ci fornisce questo piano di esecuzione:
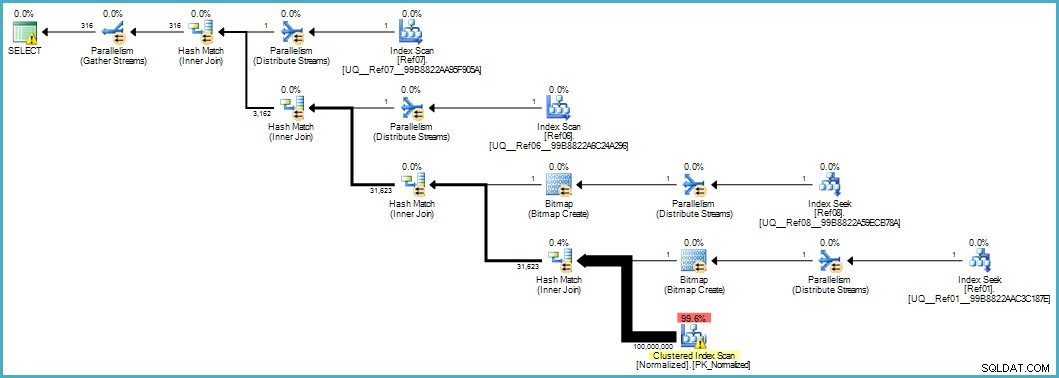
La scansione della tabella Normalizzata sembra scadente, ma entrambe le bitmap del filtro Bloom vengono applicate durante la scansione dal motore di archiviazione (quindi le righe che non possono corrispondere non emergono nemmeno fino al Query Processor). Questo potrebbe essere sufficiente per fornire prestazioni accettabili nel tuo caso e sicuramente migliori rispetto alla scansione della tabella originale con le sue colonne traboccanti.
Se sei in grado di eseguire l'aggiornamento a SQL Server 2012 Enterprise in una fase, hai un'altra opzione:creare un indice di archivio colonne nella tabella Normalizzata:
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);
Il piano di esecuzione è:
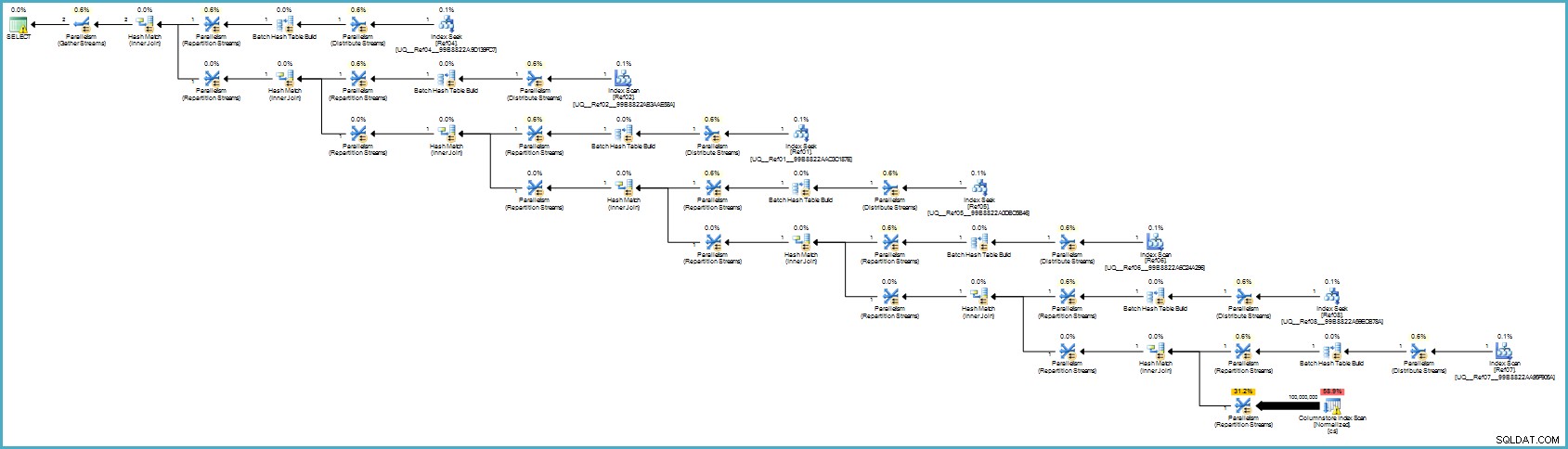
Probabilmente ti sembra peggio, ma l'archiviazione delle colonne fornisce una compressione eccezionale e l'intero piano di esecuzione viene eseguito in modalità batch con filtri per tutte le colonne che contribuiscono. Se il server dispone di thread e memoria adeguati, questa alternativa potrebbe davvero volare.
In definitiva, non sono sicuro che questa normalizzazione sia l'approccio corretto considerando il numero di tabelle e le possibilità di ottenere un piano di esecuzione scadente o richiedere tempi di compilazione eccessivi. Probabilmente correggerei prima lo schema della tabella denormalizzata (tipi di dati corretti e così via), eventualmente applicherei la compressione dei dati... le solite cose.
Se i dati appartengono veramente a uno schema a stella, probabilmente è necessario più lavoro di progettazione che dividere semplicemente gli elementi di dati ripetuti in tabelle separate.