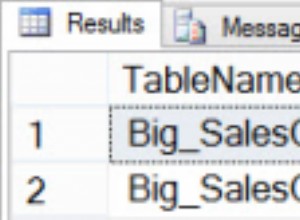
La distinzione tra indice cluster e non cluster è che l'indice cluster determina l'ordine fisico delle righe nel database . In altre parole, applicando l'indice cluster a PersonId significa che le righe saranno ordinate fisicamente per PersonId nella tabella, consentendo a una ricerca dell'indice su questo di andare direttamente alla riga (piuttosto che a un indice non cluster, che ti indirizzerebbe alla posizione della riga, aggiungendo un passaggio aggiuntivo).
Detto questo, è insolito affinché la chiave primaria non sia l'indice cluster, ma non inaudito. Il problema con il tuo scenario è in realtà l'opposto di quello che stai assumendo:vuoi unico valori in un indice cluster, non duplicati. Poiché l'indice cluster determina l'ordine fisico della riga, se l'indice si trova su una colonna non univoca, il server deve aggiungere un valore di sfondo alle righe che hanno un valore chiave duplicato (nel tuo caso, qualsiasi riga con lo stesso valore PersonId ) in modo che il valore combinato (chiave + valore di sfondo) sia univoco.
L'unica cosa che suggerirei è non utilizzando una chiave surrogata (il tuo CourtOrderId ) come chiave primaria, ma usa invece una chiave primaria composta di PersonId e qualche altra colonna o insieme di colonne che identificano in modo univoco. Se ciò non è possibile (o non pratico), tuttavia, inserisci l'indice cluster su CourtOrderId .