Ho provato alcuni SELECT COUNT(*) FROM MyTable rispetto a SELECT COUNT(SomeColumn) FROM MyTable con varie dimensioni di tabelle e dove si trova SomeColumn once è una colonna chiave di clustering, una volta che si trova in un indice non cluster e una volta che non si trova affatto in alcun indice.
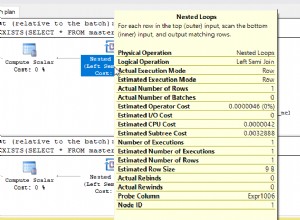
In tutti i casi, con tutte le dimensioni delle tabelle (da 300.000 righe a 170 milioni di righe), non vedo mai alcuna differenza in termini di velocità o piano di esecuzione - in tutti i casi, il COUNT viene gestito eseguendo una scansione dell'indice in cluster --> ovvero scansionando l'intera tabella, in pratica. Se è coinvolto un indice non cluster, la scansione è su quell'indice, anche quando si esegue un SELECT COUNT(*) !
Non sembra esserci alcuna differenza in termini di velocità o approccio al modo in cui vengono conteggiate queste cose:per contarle tutte, SQL Server deve solo scansionare l'intera tabella - punto.
I test sono stati eseguiti su SQL Server 2008 R2 Developer Edition