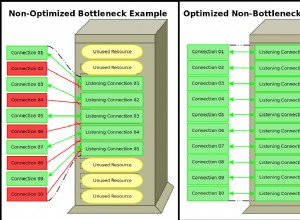
Se i TVP sono "notevolmente più lenti" delle altre opzioni, molto probabilmente non li stai implementando correttamente.
- Non dovresti usare una DataTable, a meno che la tua applicazione non ne abbia l'uso al di fuori dell'invio dei valori al TVP. Usando il
IEnumerable<SqlDataRecord>l'interfaccia è più veloce e utilizza meno memoria poiché non si duplica la raccolta in memoria solo per inviarla al DB. Ho questo documentato nei seguenti luoghi:- Come posso inserire 10 milioni di record nel più breve tempo possibile? (anche qui molte informazioni e link extra)
- Passa dizionario a stored procedure T-SQL
- Streaming dei dati In SQL Server 2008 da un'applicazione (su SQLServerCentral.com; è richiesta la registrazione gratuita)
-
Non dovresti usare
AddWithValueper SqlParameter, anche se questo non è probabilmente un problema di prestazioni. Tuttavia, dovrebbe essere:SqlParameter tvp = com.Parameters.Add("data", SqlDbType.Structured); tvp.Value = MethodThatReturnsIEnumerable<SqlDataRecord>(MyCollection); - Le TVP sono variabili di tabella e come tali non mantengono statistiche. Ciò significa che segnalano di avere solo 1 riga per Query Optimizer. Quindi, nel tuo proc, o:
- Utilizza la ricompilazione a livello di istruzione su qualsiasi query utilizzando il TVP per qualsiasi cosa diversa da un semplice SELECT:
OPTION (RECOMPILE) - Crea una tabella temporanea locale (ovvero un singolo
#) e copia il contenuto del TVP nella tabella temporanea - Puoi provare ad aggiungere una chiave primaria in cluster al tipo di tabella definito dall'utente
- Se utilizzi SQL Server 2014 o versioni successive, puoi provare a utilizzare OLTP in memoria/tabelle ottimizzate per la memoria. Consulta:Tabella temporanea e variabile di tabella più veloci utilizzando l'ottimizzazione della memoria
- Utilizza la ricompilazione a livello di istruzione su qualsiasi query utilizzando il TVP per qualsiasi cosa diversa da un semplice SELECT:
Riguardo al motivo per cui stai vedendo:
insert into @data ( ... fields ... ) values ( ... values ... )
-- for each row
insert into @data ( ... fields ... ) values ( ... values ... )
invece di:
insert into @data ( ... fields ... )
values ( ... values ... ),
( ... values ... ),
SE questo è effettivamente ciò che sta accadendo, allora:
- Se gli inserimenti vengono eseguiti all'interno di una Transazione, non vi è alcuna reale differenza di prestazioni
- La più recente sintassi dell'elenco di valori (ovvero
VALUES (row1), (row2), (row3)) è limitato a qualcosa come 1000 righe e quindi non è un'opzione praticabile per i TVP che non hanno tale limite. TUTTAVIA, questo non è probabilmente il motivo per cui vengono utilizzati singoli inserti, dato che non ci sono limiti quando si esegueINSERT INTO @data (fields) SELECT tab.[col] FROM (VALUES (), (), ...) tab([col]), che ho documentato qui:Numero massimo di righe per il costruttore del valore della tabella . Invece... - Il motivo è molto probabile che l'esecuzione di singoli inserimenti consenta lo streaming dei valori dal codice dell'app in SQL Server:
- usando un iteratore (cioè
IEnumerable<SqlDataRecord>indicato in n. 1 sopra), il codice dell'app invia ogni riga come viene restituita dal metodo e - costruire i
VALUES (), (), ...list, anche se si esegueINSERT INTO ... SELECT FROM (VALUES ...)approccio (che non è limitato a 1000 righe), che richiederebbe comunque la creazione dell'interoVALUESlista prima di inviare qualsiasi dei dati in SQL Server. Se sono presenti molti dati, la creazione della stringa super lunga richiederebbe più tempo e occuperebbe molta più memoria durante l'esecuzione.
- usando un iteratore (cioè
Consulta anche questo whitepaper del team di consulenza clienti di SQL Server:Massimizzare il throughput con TVP